







title: 输入和输出流
tag: 标签名
categories: 分类
comment: 是否允许评论(true or false)
description: 描述
top_img: https://z3.ax1x.com/2021/10/06/4xq2s1.png
cover: https://z3.ax1x.com/2021/10/06/4xq2s1.png
输入/输出流
在JavaAPI中,可以从其中读入一个字节序列的对象称为输入流,而可以向其中写入一个字节序列的对象称作输出流。抽象类InputStream和OutputStream构成了输入/输出类层次结构的基础。
读写字节
InputStream类有一个抽象方法:
abstract int read();
这个方法将读入一个字节,并返回读入的字节,或者在遇到输入源结尾时返回-1。在设计具体的输入流类时,必须覆盖这个方法以提供适用的功能,例如,在FileInputStream类中,这个对象是从某个文件中读入一个字节,而System.in是从“标准输入”中读取信息,即从控制台或重定向的文件中读入信息。
OutputStream类定义了下面的抽象方法:
abstract void write(int b);
它可以向某个输出位置写出一个字节。
ransferTo方法可以将所有字节从一个输入流传递到一个输出流:
in.transfer(out);
read和write方法在执行时都将阻塞,直至字节确实被读入或写出。
available方法使我们可以去检查当前可读入的字节数量:
int bytesAvailable = in.available();
if(bytesAvailable > 0){
var data = new byte[bytesAvailable];
in.read(data);
}
当你完成对输入/输出流的读写时,应该调用close方法来关闭它,这个调用会释放掉十分有限的操作系统资源。
关闭一个输出流的同时还会冲刷输出流的缓冲区:所有被临时置于缓冲区中,以便用更大的包的形式传递的字节在关闭输出流时都将被送出。
API
java.io.InputStream
abstract int read()
// 从数据中读入一个字节,并返回该字节。这个read方法在碰到
// 输入流的结尾时返回-1
int read(byte[] b)
// 读入一个字节数组,并返回实际读入的字节数。
int read(byte[] b,int off,int len)
int readNBytes(byte[] b,int off,int len)
// 读入的值将置于b中从off开始的位置,如果未阻塞,则读入由len指定数量的字节。
byte[] readAllBytes()
// 产生一个数组,包含可以从当前流中读入的所有字节。
long transferTo(OutputStream out)
// 将当前输入流中的所有字节传送到给定的输出流,返回传递的字节数
long skip(long n)
// 在输入流中跳过n个字节,返回实际跳过的字节数
int available
// 返回在不阻塞的情况下课获取的字节数
void close()
// 关闭这个输入流。
java.io.OutputStream
abstract void write(int n)
// 写出一个字节的数据
void write(byte[] b)
void write(byte[] b,int off,int len)
// 写出所有字节或者某个范围的字节到数组b中
void close()
// 冲刷并关闭输出流
void flush()
// 冲刷输出流,也就是将所有缓冲的数据发送到目的地
完整的流家族
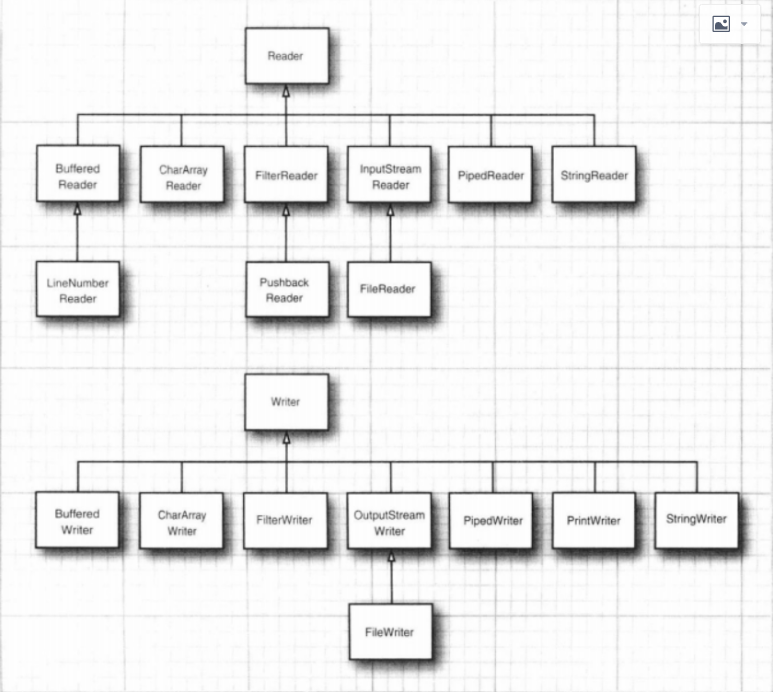
组合输入/输出流过滤器
FileInputStream和FileOutputStream可以提供附着在一个磁盘文件上的输入流和输出流,而你只需要向其构造器提供文件名或文件的完整路径名。如:
var fin = new FileInputStream("employee.dat");
这行代码可以查看用户目录下名为“employee.dat”的文件。
为了从文件中读入数字,首先需要创建一个FileInputStream,然后将其传递给DataInputStream的构造器:
var fin = new FileInputStream("employee.dat");
var din = new DataInputStream(fin);
double x = din.readDouble();
输入流在默认情况下是不被缓存区缓存的,也就是说,每个对read的调用都会请求操作系统再分发一个字节。如果我们想用缓冲机制和用于文件的数据输入方法,那么就需要使用下面这种相当复杂的构造器序列:
var din = new DataInputStream(
new BufferInputStream(
new FileInputStream("employee.dat");
)
)
我们把DataInputStream置于构造器链的最后,我们希望使用DataInputStream的方法,并且希望它们能够使用带缓冲机制的read方法。
从一个ZIP压缩文件中通过使用下面的输入流序列来读入数字
var zin = new ZipInputStream(new FileInputStream("employee.zip"));
var din = new DataInputSteam(zin);
API
java.io.FileInputStream
FileInputStream(String name)
FileInputStream(File file)
// 使用name字符串或file对象指定路径名的文件创建一个新的文件输入流。
java.io.FileOutputStream
FileOutputStream(String name)
FileOutputStream(String name,boolean append)
FileOutputStream(File file)
FileOutputStream(File file,boolean append)
// 使用name字符串或file对象指定路径名的文件创建一个新的文件输出流。如果
// append参数为true,那么数据将被添加到文件尾,而具有相同名字的已有
// 文件不会被删除,否则,这个方法会删除所有具有相同名字的已有文件
java.io.BufferedInputStream
BufferedInputStream(InputStream in)
// 创建一个带缓冲区的输入流。带缓冲区的输入流从流中读入字符时,
// 不会每次都访问设备。当缓冲区为空时,会向缓冲区中读入一个新的数据块。
java.io.BufferedOutputStream
BufferedOutputStream(OutputStream out)
// 创建一个带缓冲区的输出流。带缓冲区的输出流在收集要写出的字符时,
// 不会每次都访问设备,当缓冲区填满或当流被冲刷时,数据就被写出
文本输入与输出
在InputStreamReader构造器中选择一种具体的编码方式。
var in = new InputStreamReader(new FileInputStream("data.txt").
StandardCharsets.UTF_8);
如何写出文本输出
可以使用PrintWriter。这个类拥有以文本格式打印字符串和数字的方法。
var out = new PrintWriter("employee.txt",StandardCharsets.UTF_8);
String name = "Harry Hacker";
double salary = 75000;
out.print(name);
out.print(' ');
out.print(salary);
将会把字符Harry Hacker 75000.0输出到写出器out,之后这些字符将会被转换成字节并最终写入到employee.txt中。
如何读入文本输入
早期的java版本中,处理文本输入的唯一方式就是通过BufferedReader类。它的readLine方法会产生一行文本,或者在无法获得更多的输入时返回null,如下所示:
InputStream inputStream = ...
try(var in = new BufferedReader(new InputStreamReader
(inputStream,charset))){
String line;
while((line = in.readline()) != null)
{
do something with line
}
}
以文本格式存储对象
将一个Employee记录数组存储成了一个文本文件。

写入代码:
public static void writeEmployee(PrintWriter out,Employee e){
out.println(e.getName()+"|"+e.getSalary()+"|"+e.getHireDay());
}
读入记录。我们每次读入一行,然后分离所有的字段。我们使用一个扫描器来读入每一行,然后调用String,split方法将这一行断开成一组标记。
public static Employee readEmployee(Scanner in){
String line = in.readLine();
String[] tokens = line.split("\\|");
String name = tolens[0];
double salary = Double.parseDouble(tokens[1]);
LocalDate hireDate = LocalDate.parse(tokens[2]);
int year = hireDate.getYear();
int month = hireDate.getMonthValue();
int day = hireDate.getDayOfMonth();
return new Employee(name,salary,year,month,day);
}
字符编码方式
输入和输出流都是用于字节序列的,但是在许多情况下,我们希望操作的是文本,即字符序列。于是,字符如何修改成字节成了主要的问题。
Java针对字符使用的是Unicode标准。每个字符或"编码点"都具有一个21位的整数。
为了获得另一种编码方式的Charset,可以使用静态的forName方法:
Charset shiftJIS = Charset.forName("shift-JIS");
在读入或写出文本时,应该使用Charset对象。如,我们可以像下面这样将一个字节数组转换为字符串:
var str = new String(bytes,StandradCharsets.UTF_8);
对象输入/输出流与序列化
当你需要存储相同类型额数据时,使用固定长度的记录格式是一个不错的选择。但是,在面向对象程序中创建的对象很少全部都有具有相同的类型。
Java语言支持一种对象序列化的非常通用的机制,它可以将任何对象写出到输出流中。
保存和加载序列化对象
为了保存对象数据,首先需要打开一个ObjectOutputStream对象:
var out = new ObjectOutputStream(
new FileOutputStream("employee.dat"));
为了保存对象,可以直接使用ObjectOutputStream的writeObject方法:
var harry = new Employee("QJS",5000,1989,10,1);
var boss = new Manager("JQ",6000,1990,12,15);
out.writeObjct(harry);
out.writeObject(boss);
为了将这些对象读回,首先需要获得一个ObjectInputStream对象:
var in = new ObjectInputStream(
new FileInputStream("employee.dat"));
然后用readObject方法以这些对象被写出时的顺序获得它们:
var e1 = (Employee)in.readObject();
var e2 = (Employee)in.readObject();
但是,对希望在对象输出流中存储或从对象输入流中恢复的所有类都应进行一下修改,这些类必须实现Serializable接口:
calss Employee implements Serializable{....}
有一个重要的情况需要我们去考虑:当一个对象被多个对象共享,作为它们各自状态的一部分时,比如两个经理共用一个秘书。我们对象序列化时应该怎样设计?
保存这样的网络是一种挑战,因为我们不能去保存和恢复秘书对象的内存地址,因为当对象被重新加载时,它可能占据的是与原来完全不同的内存地址。
每个对象都是用一个序列号保存的,这就是这种机制之所以被称为序列化的原因。下面是其算法:
- 对你遇到的每个对象引用都关联一个序列号
- 对于每个对象,当第一次遇到时,保存其对象数据输出到流中
- 如果某个对象之前已经被保存过,那么只写出“与之前保存过的序列号为x的对象相同”

在读回对象时,整个过程是反过来的
- 对于对象输入流中的对象,在第一次遇到其序列号时,构建它,并使用流中数据来初始化它,然后记录这个顺序号和新对象之间的关联。
- 当遇到“与之前保存过的序列号为x的对象相同”这一标记时获取与这个序列号相关联的对象引用。
API
java.io.ObjectOutputStream
ObjectOutputStream(OutputStream out)
// 创建一个ObjectOutputStream使得你可以将对象写出到指定OutputStream
void writeObject(Object obj)
// 写出指定的对象到ObjectOutputStream,这个方法将存储指定对象的类、
// 类的签名以及这个类及其超类中非静态和非瞬时的域的值
java.io.ObjectInputStream
ObjectInputStream(InputStream in)
// 创建一个ObjectInputStream用于从指定的InputStream中读回对象的信息。
Object readObject()
// 从ObjectInputStream中读入一个对象。
修改默认的序列化机制
某些数据域时不可以序列化的,如,只对本地方法有意义的存储文件句柄,这种信息在稍后重新加载对象或将其传送到其他机器上时都是没有用的。
Java拥有一种很简单的机制来防止这种域被序列化,那就是将它们标记成transient的。如果这些域属于不可序列化的类,你也需要将它们标记成transient的。
序列化单例和类型安全的枚举
在序列化和反序列化,如果目标对象是唯一的,那么你必须加倍当心,这通常会在实现单例和类型安全的枚举时发生。
如果你使用的是java语言的enum结构,那么你就不必担心序列化,它能够正常工作。但是如果在维护遗留代码可能会出现问题,其中包含下面这样的枚举类型:
public class Orientation{
public static fianl Orientation HORIZONTAL = new Orientation(1);
public static fianl Orientation VERTICAL = new Orientation(2);
private int value;
private Orientation(int v){
value = v;
}
}
注意因为其构造器是私有的,因此,不可能创建超出Orientation.HORIZONTAL和Orientation.VERTICAL之外的对象。
一般的序列化方法不能解决这个问题,此时我们需要一种称为readResolve的特殊序列化方法,如果定义了readResolve方法,在对象被序列化之后就会调用它。它必须返回一个对象,而该对象之后会成为readObject的返回值。示例如下:
protected Object readResolve() throws ObjectStreamException{
if(value == 1) return Orientation.HORIZONTAL;
if(value == 2) return Orientation.VERTICAL;
throw new ObjectStreamException();
}
版本管理
如果使用序列化来保存对象,就需要考虑在程序演化是会有什么问题。1.1版本可以读入旧文件吗?仍旧使用1.0版本的用户可以读入新版本的文件吗?
无论类的定义产生了什么样的变化,它的SHA指纹也会跟着变化,而我们都知道对象输入流将拒绝读入具有不同指纹的对象。但是,类可以表明它对早起版本的保持兼容,要想这样做,就必须首先获得这个类的早期版本的指纹。我们可以使用JDK中的单机程序serialver来获得这个数字。
serivaler Employee
将会打印出:
Employee: static final long serivalVersionUID = -1814239825517340645L;
这个类的所有较新的版本都必须把serivalVersionUID常量定义为与最初版本的指纹相同。
class Employee implements Serializable{
...
public static final long erivalVersionUID = -1814239825517340645L;
}
如果一个类具有名为serialVersionUID的静态数据成员,它就不需要在人工计算指纹,而只需直接使用这个值。
一旦这个静态数据成员被置于某个类的内部,那么序列化系统就可以读入这个类的对象的不同版本。
如果这个类只有方法产生了变化,那么在读入新对象数据时不会有任何问题。但是如果数据域发生了变化,那么就可能会有问题。如,旧文件对象可能比程序中的对象具有更过或更少的数据域,或者数据域的类型个可能有所不同。在这些情况中,对象输入流将尽力转换成这个类的当前版本。
对象输入流会将这个类当前版本的数据域与被序列化的版本中的数据域进行比较,当然,对象流只会考虑非瞬时和非静态的数据域。如果这两部分数据域之间名字匹配而类型不匹配,那么对象输入流不会尝试将一种类型转换成另一钟类型,因为这两个对象不兼容;
下面是一个示例:假设我们已经用雇员类的最初版本1.0在磁盘上保存了大量的雇员记录,现在我们在Employee类中添加了称为department的数据域,从而将其演化到了2.0版本,下面是将1.0版对象的程序读入2.0版以及从2.0版本读入到1.0版本,可以看到额外的department域被忽略。

操作文件
Path
Path(路径)表示的是一个目录名序列,其后还可以跟着一个文件名。路径中的第一个部分可以是根部件,例如/,而允许访问的根部件取决于文件系统。以根部件开始的路径是绝对路径;否则,就是相对路径。如,我么要分别创建一个绝对路径和一个相对路径;其中,对于绝对路径,我们假设计算机运行的是类UNIX的文件系统:
Path absolute = Paths.get("/home","harry");
Path relative = Paths.get("myprog","conf","user.properties");
组合或解析路径是司空见惯的操作,调用p.resolve(q)将按照下列规则返回一个路径:
- 如果q是绝对路径,则结果就是q
- 否则,根据文件系统的规则,将"p后面跟着q"作为结果。
假设你的应用系统需要查找相对于给定基目录的工作目录,其中基目录是从配置文件中读取的,
Path workRelative = Paths.get("work");
Path workPath = basePath.resolve(workRelative);
resolve方法有一种快捷方式,它接受一个字符串而不是路径:
Path workPath = basePath.resolve("work");
还有一个方便的方法为resolveSibling,它通过解析指定路径的父路径产生其兄弟路径。如:
Path temPath = workPath.resolveSibling("temp");
将创建/opt/myapp/temp
API
java.nio.file.Paths
static Path get(String first,String...more)
// 通过连接给定的字符串创建一个路径
java.nio.file.Path
Path resolve(Path other)
Path resolve(String other)
// 如果other是绝对路径,那么就返回other;否则,返回通过连接this和
// other获得的路径
Path resolveSibling(Path other)
Path resolveSibling(String other)
// 如果other是绝对路径,那么就返回other;否则,返回通过连接
// this和other获得的路径
Path relativize(Path other)
// 返回用this进行解析,相对于other的相对路径
toFile()
// 从该路径中创建一个File对象
java.io.File
Path toPath()
// 从该文件中创建一个Path对象。
读写文件
Files类可以使得普通文件操作变得快捷。可以使用下面的方式很容易地读取文件的所有内容
byte[] bytes = Files.readAllBytes(path);
从文本文件中读取内容:
var content = Files.readString(path,charset);
如果希望将文件当作行序列读入,那么可以调用:
List<String> lines = Files.readAllLines(path,charset);
如果希望写出一个字符串到文件中,可以调用:
Files.writeString(path,content.charset);
向指定文件追加内容,可以调用:
Files.write(path,content.getBytes(charset),
StandardOpention.APPEND);
用下面的语句将一个行的集合写出到文件中:
Files.write(path,lines,charset);
API
static byte[] readAllBytes(Path path)
static String readString(Path path,Charset charset)
static List<String> readAllLines(Path path,Charset charset)
// 读入文件的内容
static Path write(Path path,byte[] contents,OpenOption...options)
static Path write(Path path,String contents,Charset charset,
OpenOption...options);
static Path write(Path path,
Iterable<? extends CharSequence>content,
OpenOption options);
// 将给定内容写出到文件中,并返回path
static InputStream newInputStream(Path path,OpenOption...options)
static BufferedWriter newBufferedWriter(
Path path,Charset charset,OpenOption...options
)
// 打开一个文件,用于读入或写出
创建文件和目录
创建新目录可以调用
Files.createDirectory(path);
其中,路径中除最后一个部件外,其他部分都必须是存在的。要创建路径中的中间目录,应该使用
Files.createDirectories(path);
可以使用下面的语句创建一个空文件:
Files.createFile(path);
如果文件已经存在了,那么这个调用就会抛出异常。
API
java.nio.file.Files
static Path createFile(Path path,FileAttribute<?>...attrs)
static Path createDirectory(Path path,FileAttribute<?>...attrs)
static Path createDirectories(Path path,FileAttibute<?>...attrs)
// 创建一个文件或目录,createDirectories方法还会创建路径中所有的中间
// 目录
static Path createTempFile(String prefix,String suffix,
FileAttribute<?>...attrs)
static Path createTemplateDirectory(String prefix,
FileAttribute<?>...attrs)
// 在适合临时文件的位置,或者在给定的父目录中,创建一个临时文件或目录。
// 返回所创建的文件或目录的路径
复制、移动和删除文件
将文件从一个位置复制到另一个位置可以直接调用
Files.copy(fromPath,toPath);
移动文件可以调用
Files.move(fromPath,toPath);
如果目标路径已经存在,那么复制或移动将失败。如果想要覆盖已有的目标路径,可以使用REPLACE_EXISTING选项:
Files.copy(fromPath,toPath,StandardCopyOption.REPLACE_EXISTING,
StandardCopyOption.COPY_ATTRIBUTES
);
你还可以将一个输入流复制到Path中,这表示想要将该输入流存储到硬盘上。类似地,你可以将一个Path复制到输出流中,可以使用下面的调用:
Files.copy(inputStream,toPath);
Files.copy(fromPath,outputStream);
删除文件可以使用:
Files.delete(path);
如果删除的文件不存在,这个方法就会抛出异常,因此,可以使用下面的方法:
Files.deleteIfExists(path);
该删除方法可以用来移除空目录。
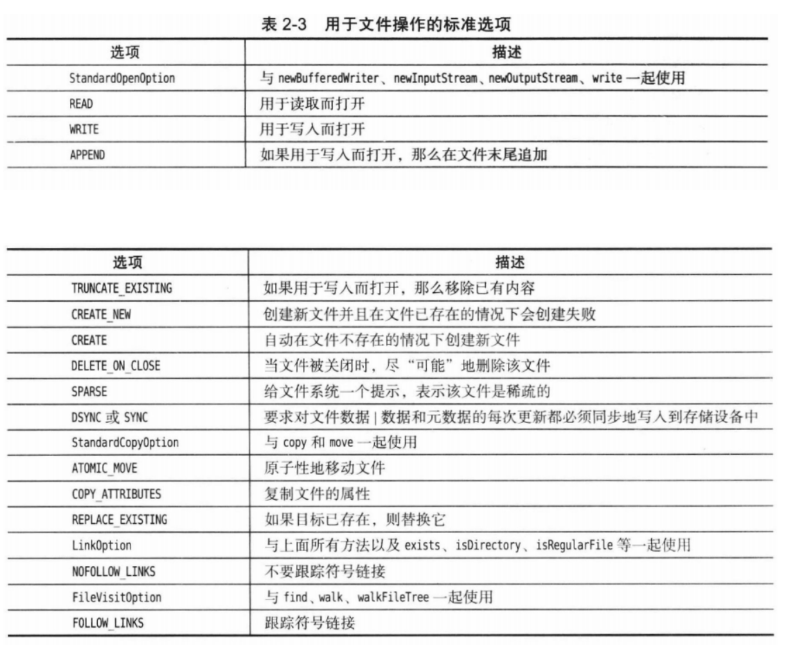
获取文件信息
下面的静态方法都返回一个boolean值,表示检查路径的某个属性的结果:
- exists
- isHidden
- isReadable,isWritable,isExecutable
- isRegularFile,isDirectory,isSymbol
size方法将返回文件的字节数:
long fileSize = Files.size(path);
访问目录中的项
静态的files.list方法会返回一个可以读取目录中各个项的Stream
因为读取目录涉及需要关闭的系统资源,所以应该使用try块:
try(Stream<Path> entries = Files.list(pathToDirectory)){
...
}
list方法不会进入子目录。为了处理目录中的所有子目录,需要使用File.walk方法。
try(Stream<Path> entries = Files.walk(pathToRoot)){
// Contains all descendants,visited in depth-first order
}
使用目录流
Files.walk方法会产生一个可遍历目录中所有子孙的Stream
try(DirectoryStream<Path> entries = Files.newDirectoryStream(dir)){
for(Path entry: entries){
....
}
}
带资源的try语句块用来确保目录流可以被正确关闭。
ZIP文件系统
Paths类会在默认文件系统中查找路径,即在用户本地磁盘中的文件。下面是其调用的过程:
FileSystem fs = FileSystem.newFileSystem(Paths.get(zipname),null);
将建立一个文件系统,它包含ZIP文档中的所有文件。从ZIP的文档中复制出文件也比较方便:
Files.copy(fs.getPath(sourceName),target);
其中的fs.getPath对于任意文件系统来说都与Paths.get类似。
java.nio.file.FileSystems
static FileSystem newFileSystem(Path path,ClassLoader loader)
// 对所安装的文件系统提供者进行迭代,并且如果loader不为Null,那么
// 就还会迭代给定的类加载器能够加载的文件系统,返回由第一个可以接受路径
// 的文件系统提供者创建文件系统。
java.nio.file.FileSystem
static Path getPath(String first,String ... more)
// 将给定的字符串连接起来创建一个路径
内存映射文件
大多数操作系统都可以利用虚拟内存实现来将一个文件或者文件的一部分“映射”到内存中。这个文件就可以被当作内存数组一样地访问,这比传统的文件操作要快得多。
内存映射文件的性能

java.nio包使得内存映射变得十分简单,下面就是我们需要做的。
首先,从文件中获得一个通道,通道是用于磁盘文件的一种抽象,它使我们可以访问诸如内存映射,文件加锁机制以及文件间快速数据传递等操作系统特性。
FileChannel channel = FileChannel.open(path,options);
然后,通过调用FileChannel类的map方法从这个通道中获得一个ByteBuffer。你可以指定想要的文件区域与映射模式,支持的模式有三种:
- FileChannel.MapMode.READ_ONLY:所产生的缓冲区是只读的,任何对该缓冲区写入的尝试都会导致ReadOnlyBufferException异常。
- FileChannel.MapMode.READ_WRITE:所产生的缓冲区是可写的,任何修改都会在某个时候写会到文件中。
- FileChannel.MapMode.PRIVATE:所产生的缓冲区是可写的,但是任何修改对这个缓冲区来说都是私有的,不会传播到文件中。
一旦有了缓冲区,就可以使用ByteBuffer类和Buffer超类的方法读写数据了。
可以像下面一样顺序遍历缓冲区中的所有字节:
while(buffer.hasRemaining()){
byte b = buffer.get();
...
}
或者像下面这样进行随机访问:
for(int i = 0; i < buffer.limit(); i++){
byte b = buffer.get(i);
}
缓冲区数据结构
缓冲区是由具有相同类型的数值构成的数组,Buffer类是一个抽象类,它具有众多的子类,包括ByteBuffer、CharBuffer、DoubleBuffer、IntBuffer、LongBuffer和ShortBuffer.
在实践中,最常用的将是ByteBuffer和CharBuffer。每个缓冲区都具有:
- 一个容量,它永远不能改变
- 一个读写位置,下一个值将在此进行读写。
- 一个界限,超过它进行读写时没有意义的
- 一个可选的标记,用于重复一个读入或写出的操作。
这些值满足下面的条件:
0≤标记≤读写位置≤界限≤容量
使用缓存区的主要目的是执行"写,然后读入"循环。假设我们有一个缓存区,在一开始,它的位置为0,界限等于容量。我们不断地调用put将值添加到这个缓冲区中,当我们耗尽所有的数据或者写出的数量达到容量大小时,就该切换到读入操作了。

要获取缓冲区,可以调用诸如ByteBuffer.allocate或ByteBuffer.wrap这样的静态方法。
然后,可以用来自某个通道的数据填充缓冲区,或者将缓冲区内容写出到通道中。
ByteBuffer buffer = ByteBuffer.allocate(RECORD_SIZE);
channel.read(buffer);
channel.position(newpos);
buffer.flip();
channel.write(buffer);
API
java.nio.buffer
Buffer clear()
// 通过将位置复位到0,并将界限设置都容量,使这个缓冲区为写出做好准备。
// 返回this
Buffer flip()
// 通过将界限设置到位置,并将位置复位到0,是这个缓冲区为读入做好准备。
// 返回this.
Buffer rewind()
// 通过将读写位置复位到0,并保持界限不变,使这个缓冲区为重新读入相同
// 的值做好准备。返回this.
Buffer remark()
// 将这个缓冲区的标记设置到读写位置,返回this.
Buffer reset()
// 将这个缓冲区的位置设置到标记,从而允许被标记的部分再次被读入或写出
// 返回this
int remaining()
// 返回剩余可读入或可写出的值的数量,即界限与位置之间的差异。
int position()
void position(int newValue)
// 返回这个缓冲区的位置
int capacity()
// 返回这个缓冲区的容量
正则表达式
正则表达式用于指定字符串的模式,可以在任何需要定位匹配某种特定模式的字符串的情况下使用正则表达式。
正则表达式语法
下面是一个简单的示例,正则表达式:
[Jj]ava.+
上面的式子将匹配下列形式的所有字符串:
- 第一个字母是J或j.
- 接下来的三个字母是ava.
- 字符串的其余部分由一个或多个任意的字符构成。
如,字符串"javanese"就匹配这个特定的正则表达式,但字符串"Core Java"就不匹配。
-
字符类是一个括在括号中的可选择的字符集,如[Jj]、[0-9]、[A-Za-z]或[0-9].这里"-"表示是一个范围(表示落在这两个边界范围之内的字符),而表示补集(除了指定字符之外的所有字符)。
-
如果字符类中包含"-",那么它必须是第一项或最后一项;如果要包含"[",那么它必须是第一项;如果要包含"^",那么它可以是除开始位置之外的任何位置。其中,你只需要转义"[“和”"。
-
下表是正则表达式语法:
\ 将下一字符标记为特殊字符、文本、反向引用或八进制转义符。例如, n匹配字符 n。\n 匹配换行符。序列 \\ 匹配 \ ,\( 匹配 (。 ^ 匹配输入字符串开始的位置。如果设置了 RegExp 对象的 Multiline 属性,^ 还会与"\n"或"\r"之后的位置匹配。 $ 匹配输入字符串结尾的位置。如果设置了 RegExp 对象的 Multiline 属性,$ 还会与"\n"或"\r"之前的位置匹配。 * 零次或多次匹配前面的字符或子表达式。例如,zo* 匹配"z"和"zoo"。* 等效于 {0,}。 + 一次或多次匹配前面的字符或子表达式。例如,"zo+"与"zo"和"zoo"匹配,但与"z"不匹配。+ 等效于 {1,}。 ? 零次或一次匹配前面的字符或子表达式。例如,"do(es)?“匹配"do"或"does"中的"do”。? 等效于 {0,1}。 {n} n 是非负整数。正好匹配 n 次。例如,"o{2}"与"Bob"中的"o"不匹配,但与"food"中的两个"o"匹配。 {n,} n 是非负整数。至少匹配 n 次。例如,"o{2,}“不匹配"Bob"中的"o”,而匹配"foooood"中的所有 o。"o{1,}“等效于"o+”。"o{0,}“等效于"o*”。 {n,m} m 和 n 是非负整数,其中 n <= m。匹配至少 n 次,至多 m 次。例如,"o{1,3}"匹配"fooooood"中的头三个 o。‘o{0,1}’ 等效于 ‘o?’。注意:您不能将空格插入逗号和数字之间。 ? 当此字符紧随任何其他限定符(*、+、?、{n}、{n,}、{n,m})之后时,匹配模式是"非贪心的"。"非贪心的"模式匹配搜索到的、尽可能短的字符串,而默认的"贪心的"模式匹配搜索到的、尽可能长的字符串。例如,在字符串"oooo"中,"o+?“只匹配单个"o”,而"o+“匹配所有"o”。 . 匹配除"\r\n"之外的任何单个字符。若要匹配包括"\r\n"在内的任意字符,请使用诸如"[\s\S]"之类的模式。 (pattern) 匹配 pattern 并捕获该匹配的子表达式。可以使用 $0…$9 属性从结果"匹配"集合中检索捕获的匹配。若要匹配括号字符 ( ),请使用"(“或者”)"。 (?:pattern) 匹配 pattern 但不捕获该匹配的子表达式,即它是一个非捕获匹配,不存储供以后使用的匹配。这对于用"or"字符 (|) 组合模式部件的情况很有用。例如,'industr(?:y|ies) 是比 ‘industry|industries’ 更经济的表达式。 (?=pattern) 执行正向预测先行搜索的子表达式,该表达式匹配处于匹配 pattern 的字符串的起始点的字符串。它是一个非捕获匹配,即不能捕获供以后使用的匹配。例如,‘Windows (?=95|98|NT|2000)’ 匹配"Windows 2000"中的"Windows",但不匹配"Windows 3.1"中的"Windows"。预测先行不占用字符,即发生匹配后,下一匹配的搜索紧随上一匹配之后,而不是在组成预测先行的字符后。 (?!pattern) 执行反向预测先行搜索的子表达式,该表达式匹配不处于匹配 pattern 的字符串的起始点的搜索字符串。它是一个非捕获匹配,即不能捕获供以后使用的匹配。例如,‘Windows (?!95|98|NT|2000)’ 匹配"Windows 3.1"中的 “Windows”,但不匹配"Windows 2000"中的"Windows"。预测先行不占用字符,即发生匹配后,下一匹配的搜索紧随上一匹配之后,而不是在组成预测先行的字符后。 x|y 匹配 x 或 y。例如,‘z|food’ 匹配"z"或"food"。’(z|f)ood’ 匹配"zood"或"food"。 [xyz] 字符集。匹配包含的任一字符。例如,"[abc]“匹配"plain"中的"a”。 [^xyz] 反向字符集。匹配未包含的任何字符。例如,"[^abc]“匹配"plain"中"p”,“l”,“i”,“n”。 [a-z] 字符范围。匹配指定范围内的任何字符。例如,"[a-z]"匹配"a"到"z"范围内的任何小写字母。 [^a-z] 反向范围字符。匹配不在指定的范围内的任何字符。例如,"[^a-z]"匹配任何不在"a"到"z"范围内的任何字符。 \b 匹配一个字边界,即字与空格间的位置。例如,“er\b"匹配"never"中的"er”,但不匹配"verb"中的"er"。 \B 非字边界匹配。“er\B"匹配"verb"中的"er”,但不匹配"never"中的"er"。 \cx 匹配 x 指示的控制字符。例如,\cM 匹配 Control-M 或回车符。x 的值必须在 A-Z 或 a-z 之间。如果不是这样,则假定 c 就是"c"字符本身。 \d 数字字符匹配。等效于 [0-9]。 \D 非数字字符匹配。等效于 [^0-9]。 \f 换页符匹配。等效于 \x0c 和 \cL。 \n 换行符匹配。等效于 \x0a 和 \cJ。 \r 匹配一个回车符。等效于 \x0d 和 \cM。 \s 匹配任何空白字符,包括空格、制表符、换页符等。与 [ \f\n\r\t\v] 等效。 \S 匹配任何非空白字符。与 [^ \f\n\r\t\v] 等效。 \t 制表符匹配。与 \x09 和 \cI 等效。 \v 垂直制表符匹配。与 \x0b 和 \cK 等效。 \w 匹配任何字类字符,包括下划线。与"[A-Za-z0-9_]"等效。 \W 与任何非单词字符匹配。与"[^A-Za-z0-9_]"等效。 \xn 匹配 n,此处的 n 是一个十六进制转义码。十六进制转义码必须正好是两位数长。例如,"\x41"匹配"A"。"\x041"与"\x04"&"1"等效。允许在正则表达式中使用 ASCII 代码。 *num* 匹配 num,此处的 num 是一个正整数。到捕获匹配的反向引用。例如,"(.)\1"匹配两个连续的相同字符。 *n* 标识一个八进制转义码或反向引用。如果 *n* 前面至少有 n 个捕获子表达式,那么 n 是反向引用。否则,如果 n 是八进制数 (0-7),那么 n 是八进制转义码。 *nm* 标识一个八进制转义码或反向引用。如果 *nm* 前面至少有 nm 个捕获子表达式,那么 nm 是反向引用。如果 *nm* 前面至少有 n 个捕获,则 n 是反向引用,后面跟有字符 m。如果两种前面的情况都不存在,则 *nm* 匹配八进制值 nm,其中 n 和 m 是八进制数字 (0-7)。 \nml 当 n 是八进制数 (0-3),m 和 l 是八进制数 (0-7) 时,匹配八进制转义码 nml。 \un 匹配 n,其中 n 是以四位十六进制数表示的 Unicode 字符。例如,\u00A9 匹配版权符号 (©)。
匹配字符串
正则表达式的最简单用法就是测试某个特定的字符串是否与它匹配。
首先用正则表达式的字符串构建一个Pattern对象。然后从这个模式中获得一个Matcher,并调用它的matches方法:
Pattern pattern = Pattern.complile(patternString);
Mathcer matcher = pattern.matcher(input);
if(matcher.matches())...
找出多个匹配
通常,你希望用正则表达式来匹配全部输入,而只是想找出输入中一个或多个匹配的子字符串。这时可以使用Matcher类find方法来查找匹配内容,如果返回true,再使用start和end方法来查找匹配的内容,或使用不带引元的group方法来获取匹配的字符串。
while(mathcer.find()){
int start = matcher.start();
int end = matcher.end();
String match = input.group();
...
}
用分割符来分割
有时,需要将输入按照匹配的分隔符断开,而其他部分保存不变。Pattern.split 方法可以自动完成这项任务。调用此方法后可以获得一个剔除分隔符之后的字符串数组:
String input = ...;
Pattern commas = Pattern.compile("\\s*,\\S*");
String[] tokens = commas.split(input);
// "1,2,3"turn into["1","2","3"]
如果输入数据在文件中,那么需要使用扫描器:
var in = new Scanner(path,StandardCharsets.UTF_8);
in.useDelimiter("\\s*,\\S*");
Stream<String> tokens = in.tokens();
替换匹配
Matcher类的replaceAll方法将正在表达式出现的所有地方都用替换字符来替换。如,下面的指令将所有的数组序列都转换成#字符。
Pattern pattern = Pattern.compile("[0-9]+");
Matcher matcher = pattern.matcher(input);
String output = matcher.replaceAll("#");
Matcher类的方法
索引方法
索引方法提供了有用的索引值,精确表明输入字符串中在哪能找到匹配:
| 1 | **public int start()**返回以前匹配的初始索引。 |
|---|---|
| 2 | public int start(int group) 返回在以前的匹配操作期间,由给定组所捕获的子序列的初始索引 |
| 3 | **public int end()**返回最后匹配字符之后的偏移量。 |
| 4 | **public int end(int group)**返回在以前的匹配操作期间,由给定组所捕获子序列的最后字符之后的偏移量 |
代码示例:
下面是对一个单词"cat"出现在输入字符串中出现次数进行计数的例子。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegexMatches
{
private static final String REGEX = "\\bcat\\b";
private static final String INPUT =
"cat cat cat cattie cat";
public static void main( String[] args ){
Pattern p = Pattern.compile(REGEX);
Matcher m = p.matcher(INPUT); // 获取 matcher 对象
int count = 0;
while(m.find()) {
count++;
System.out.println("Match number "+count);
System.out.println("start(): "+m.start());
System.out.println("end(): "+m.end());
}
}
}
结果:
Match number 1
start(): 0
end(): 3
Match number 2
start(): 4
end(): 7
Match number 3
start(): 8
end(): 11
Match number 4
start(): 19
end(): 22
查找方法:
查找方法用来检查输入字符串并返回一个布尔值,表示是否找到该模式:
| 1 | public boolean lookingAt() 尝试将从区域开头开始的输入序列与该模式匹配。 |
|---|---|
| 2 | **public boolean find()**尝试查找与该模式匹配的输入序列的下一个子序列。 |
| 3 | **public boolean find(int start)**重置此匹配器,然后尝试查找匹配该模式、从指定索引开始的输入序列的下一个子序列。 |
| 4 | **public boolean matches()**尝试将整个区域与模式匹配 |
matches和lookingAt方法都用来尝试一个输入序列模式。它们的不同是matches要求这个序列都匹配,而lookingAt不要求。
lookingAt方法虽然不需要整句都匹配,但是需要从第一个字符开始匹配。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegexMatches
{
private static final String REGEX = "foo";
private static final String INPUT = "fooooooooooooooooo";
private static final String INPUT2 = "ooooofoooooooooooo";
private static Pattern pattern;
private static Matcher matcher;
private static Matcher matcher2;
public static void main( String[] args ){
pattern = Pattern.compile(REGEX);
matcher = pattern.matcher(INPUT);
matcher2 = pattern.matcher(INPUT2);
System.out.println("Current REGEX is: "+REGEX);
System.out.println("Current INPUT is: "+INPUT);
System.out.println("Current INPUT2 is: "+INPUT2);
System.out.println("lookingAt(): "+matcher.lookingAt());
System.out.println("matches(): "+matcher.matches());
System.out.println("lookingAt(): "+matcher2.lookingAt());
}
}
结果:
Current REGEX is: foo
Current INPUT is: fooooooooooooooooo
Current INPUT2 is: ooooofoooooooooooo
lookingAt(): true
matches(): false
lookingAt(): false
替换方法
替换方法是替换输入字符串里文本的方法:
| 1 | **public Matcher appendReplacement(StringBuffer sb, String replacement)**实现非终端添加和替换步骤。 |
|---|---|
| 2 | **public StringBuffer appendTail(StringBuffer sb)**实现终端添加和替换步骤。 |
| 3 | public String replaceAll(String replacement) 替换模式与给定替换字符串相匹配的输入序列的每个子序列。 |
| 4 | public String replaceFirst(String replacement) 替换模式与给定替换字符串匹配的输入序列的第一个子序列。 |
| 5 | **public static String quoteReplacement(String s)**返回指定字符串的字面替换字符串。这个方法返回一个字符串,就像传递给Matcher类的appendReplacement 方法一个字面字符串一样工作。 |
replaceFirst和replaceAll方法
replaceFirst和replaceAll方法用来替换正则表达式的文本,不同的是,replaceFirst替换首次匹配,replaceAll替换所有匹配。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegexMatches
{
private static String REGEX = "dog";
private static String INPUT = "The dog says meow. " +
"All dogs say meow.";
private static String REPLACE = "cat";
public static void main(String[] args) {
Pattern p = Pattern.compile(REGEX);
// get a matcher object
Matcher m = p.matcher(INPUT);
INPUT = m.replaceAll(REPLACE);
System.out.println(INPUT);
}
}
编译结果:
The cat says meow. All cats say meow.
换步骤。 |
| 3 | public String replaceAll(String replacement) 替换模式与给定替换字符串相匹配的输入序列的每个子序列。 |
| 4 | public String replaceFirst(String replacement) 替换模式与给定替换字符串匹配的输入序列的第一个子序列。 |
| 5 | **public static String quoteReplacement(String s)**返回指定字符串的字面替换字符串。这个方法返回一个字符串,就像传递给Matcher类的appendReplacement 方法一个字面字符串一样工作。 |
replaceFirst和replaceAll方法
replaceFirst和replaceAll方法用来替换正则表达式的文本,不同的是,replaceFirst替换首次匹配,replaceAll替换所有匹配。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegexMatches
{
private static String REGEX = "dog";
private static String INPUT = "The dog says meow. " +
"All dogs say meow.";
private static String REPLACE = "cat";
public static void main(String[] args) {
Pattern p = Pattern.compile(REGEX);
// get a matcher object
Matcher m = p.matcher(INPUT);
INPUT = m.replaceAll(REPLACE);
System.out.println(INPUT);
}
}
编译结果:
The cat says meow. All cats say meow.















 671
671











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









