









1、并行流水线
并行算法虽然可以充分发挥多核CPU的性能,但并非所有的运算都可以改造成并行的形式。那么什么样的运算是无法并行的呢?简单来说,执行过程中有数据相关性的运算都是无法完美并行的。
假如程序中现在有两个数,B和C,计算(B+C)×B/2,这个运算过程就是无法并行的。原因是,如果B+C没有执行完成,则永远算不出(B+C)×B,这就是数据相关性。如果线程执行时所需的数据存在这种依赖关系,那么就没有办法将它们完美地并行化。下图诠释了这个道理:
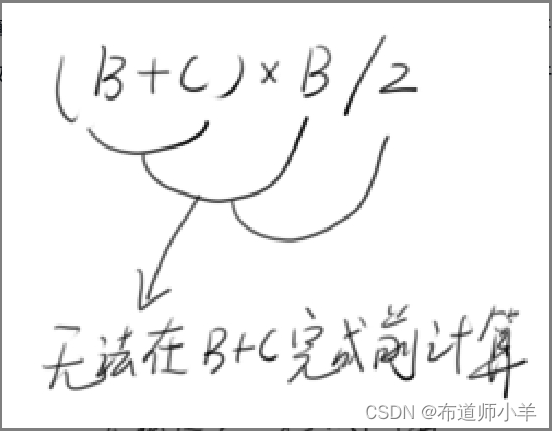
遇到这种情况时,有没有什么补救措施呢?答案是肯定的,那就是借鉴日常生产中的流水线思想。
比如,现在要生产一批小玩偶。小玩偶的制作分为四个步骤:第一,组装身体;第二,在身体上安装四肢和头部;第三,给组装完成的玩偶穿上一件漂亮的衣服;第四,包装出货。为了加快制作进度,我们不可能叫四个人同时加工一个玩具,因为这四个步骤有着严重的依赖关系。如果没有身体,就没有地方安装四肢;如果没有组装完成,就不能穿衣服;如果没有穿上衣服,就不能包装发货。因此,找四个人来做一个玩偶是毫无意义的。
但是,如果你现在要制作的不是一个玩偶,而是一万个玩偶,情况就不同了。你可以找四个人,第一个人只负责组装身体,完成后交给第二个人;第二个人只负责安装头部和四肢,完成后交第三人;第三人只负责穿衣服,完成后交第四人;第四人只负责包装发货。这样所有人都可以一起工作,共同完成任务,而整个时间周期也能缩短到原来的1/4左右,这就是流水线的思想。一旦流水线满载,每次只需要一步(假设一个玩偶需要四步)就可以产生一个玩偶,如下图所示:
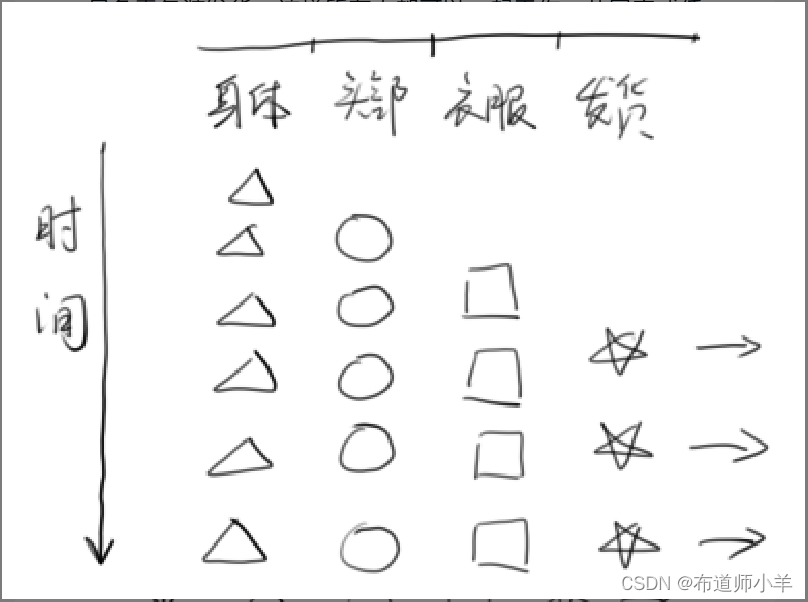
类似的思想可以借鉴到程序开发中。即使(B+C)×B/2无法并行,但是如果你需要计算一大堆B和C的值,你依然可以将它流水化。首先将计算过程拆分为三个步骤:
- P1:A=B+C
- P2:D=A×B
- P3:D=D/2
上述步骤中的P1、P2和P3均在单独的线程中计算,并且每个线程只负责自己的工作。此时,P3的计算结果就是最终需要的答案。
P1接收B和C的值并求和,将结果输入给P2。P2求乘积后输入给P3。P3将D除以2得到最终值。一旦这条流水线建立,只需要一个计算步骤就可以得到(B+C)×B/2的结果。
为了实现这个功能,我们需要定义一个在线程间携带结果进行信息交换的载体:

P1计算的是加法:
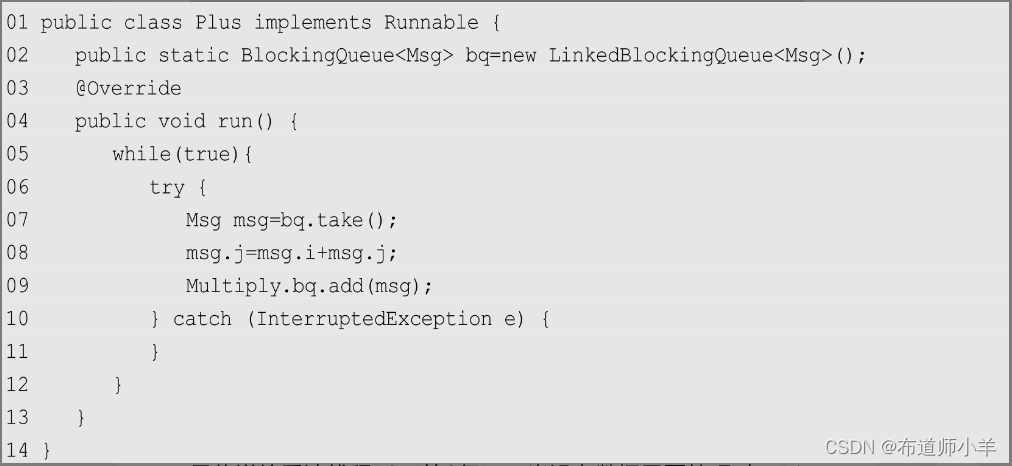
上述代码中,P1取得封装了两个操作数的Msg,并求和,将结果传递给乘法线程P2(第9行)。当没有数据需要处理时,P1等待。
P2计算的是乘法:

和P1类似,P2计算相乘结果后,将中间结果传递给除法线程P3。
P3计算的是除法:
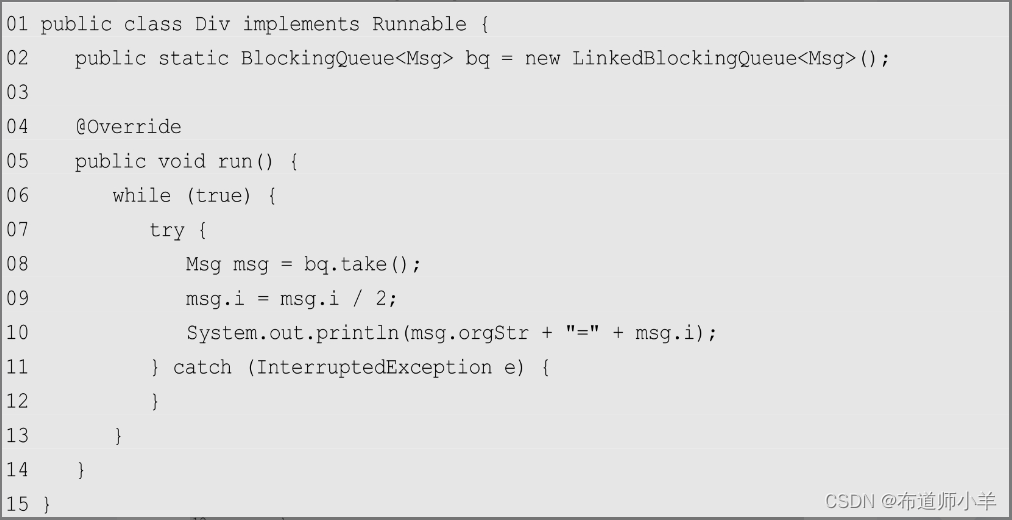
P3将收到的P2的结果除以2后输出最终的结果。
最后是提交任务的主线程,这里我们提交100万个请求,让线程组进行计算:

上述代码第13行将数据提交给P1加法线程,开启流水线的计算。在多核或者分布式场景中,这种设计思路可以有效地将有依赖关系的操作分配在不同的线程中进行计算,尽可能利用多核的优势。
2、并行搜索
搜索几乎是每一个软件都必不可少的功能。对于有序数据,通常可以采用二分查找法。对于无序数据,则只能挨个查找。本节将讨论有关并行的无序数组的搜索实现。
给定一个数组,我们要查找满足条件的元素。对于串行程序来说,只要遍历一下数组就可以得到结果。但如果要使用并行方式,则需要额外增加一些线程间的通信机制,使各个线程可以有效运行。
一种简单的策略就是将原始数据集合按照期望的线程数进行分割。如果我们计划使用两个线程搜索,那么就可以把一个数组或集合分割成两个。每个线程各自独立搜索,当其中有一个线程找到数据后,立即返回结果即可。
现在假设有一个整型数组,我们需要查找数组内的元素:

定义线程池、线程数量及存放结果的变量result。在result中,我们会保存符合条件的元素在arr数组中的下标,默认为-1,表示没有找到给定元素:

并行搜索会要求每个线程查找arr中的一段,因此,搜索函数必须指定线程需要搜索的起始位置和结束位置:
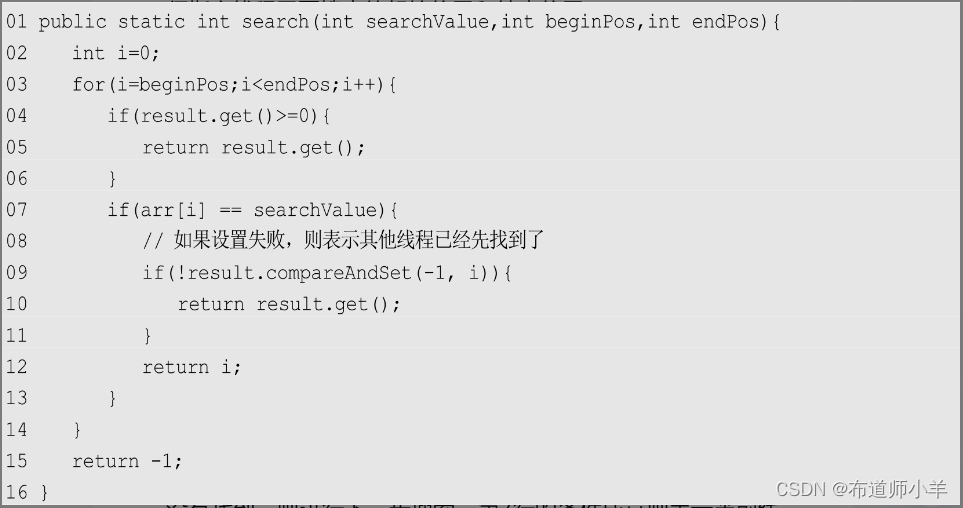
上述代码第4行,首先通过result判断是否已经有其他线程找到了需要的结果。如果已经找到,则立即返回并不再查找。如果没有找到,则进行下一步搜索。第7行的条件成立则表示当前线程找到了需要的数据,那么就会将结果保存到result变量中。这里使用CAS操作,如果设置失败,则表示其他线程已经先找到了结果。因此,可以无视失败的情况,找到结果后返回即可。
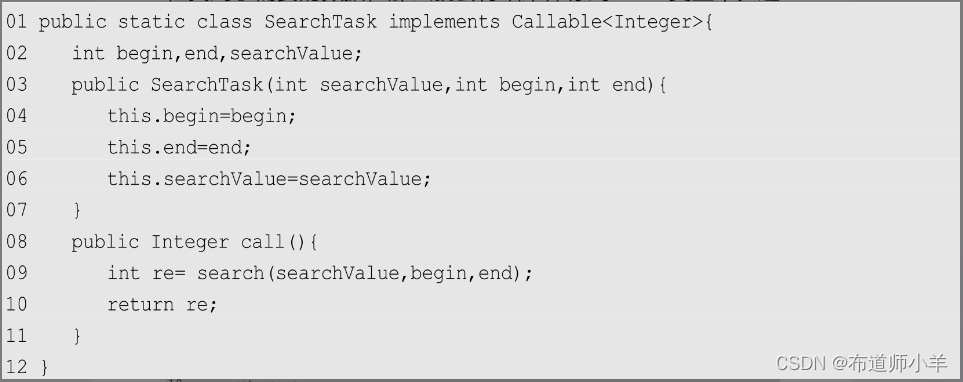
定义一个线程进行查找,它会调用前面的pSearch()方法:
最后是pSearch()方法,它是并行查找函数,根据线程数量对arr数组进行划分,并建立对应的任务提交给线程池处理:
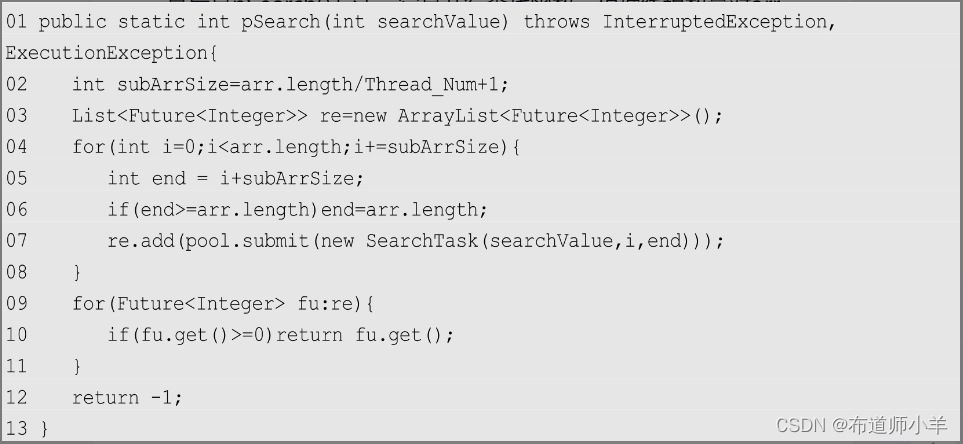
上述代码中使用了JDK内置的Future模式,其中第4~8行将原始数组arr划分为若干段,并根据划分结果建立子任务。每一个子任务都会返回一个Future对象,通过Future对象可以获得线程组得到的最终结果。在这里,由于线程之间通过result共享彼此的信息,只要一个线程成功返回后,其他线程都会立即返回。因此,不会出现由于排在前面的任务长时间无法结束而导致无法立即获取搜索结果的情况。
3、并行排序
排序是一项常用的操作。应用程序在运行时,可能无时无刻不在进行排序操作。排序的算法有很多,但这里并不打算一一介绍它们。大部分排序算法,都是串行执行的。当排序元素很多时,若使用并行算法代替串行算法,显然可以更有效地利用CPU。但将串行算法改造成并行算法并非易事,甚至会极大地增加原有算法的复杂度。这里将介绍几种相对简单但是也足以让人眼前一亮的平行排序算法。
3.1、分离数据相关性:奇偶交换排序
在介绍奇偶排序前,首先让我们看一下熟悉的冒泡排序。在这里,假设我们需要将数组从小到大排序。冒泡排序的操作类似水中的气泡上浮,在冒泡排序的执行过程中,如果数字较小,它就会逐步被交换到前面去,相反,大的数字则会下沉,交换到数组的末尾。
冒泡排序的一般算法如下:
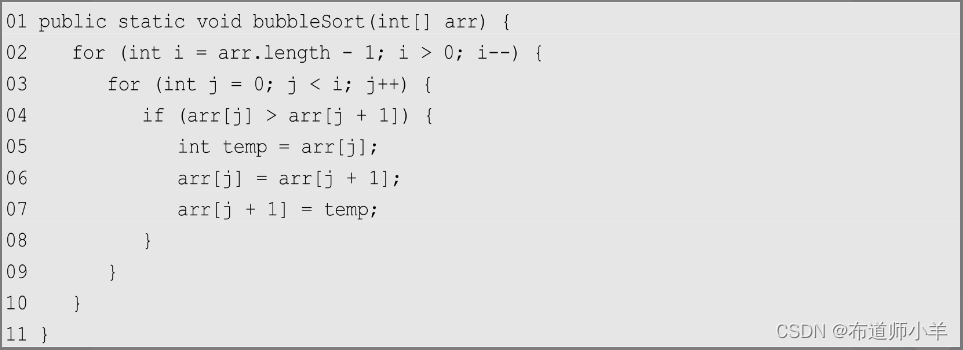
下图展示了冒泡排序的迭代过程:

可以看到,在每次迭代的交换过程中,由于每次交换的两个元素存在数据冲突,对于每个元素,它既可能与前面的元素交换,也可能和后面的元素交换,因此很难直接改造成并行算法。
如果能够解开这种数据的相关性,就可以比较容易地使用并行算法来实现类似的排序。奇偶交换排序就是基于这种思想的。
对于奇偶交换排序来说,它将排序过程分为两个阶段,奇交换和偶交换。奇交换总是比较奇数索引及其相邻的后续元素,而偶交换总是比较偶数索引及其相邻的后续元素。并且,奇交换和偶交换会成对出现,这样才能保证比较和交换涉及数组中的每一个元素。
奇偶交换的迭代示意图如下图所示:

从上图可以看到,由于将整个比较交换独立分割为奇阶段和偶阶段,使得在每一个阶段内,所有的比较和交换是没有数据相关性的,因此每一次比较和交换都可以独立执行,也就可以并行化了。
下面是奇偶交换排序的串行实现:
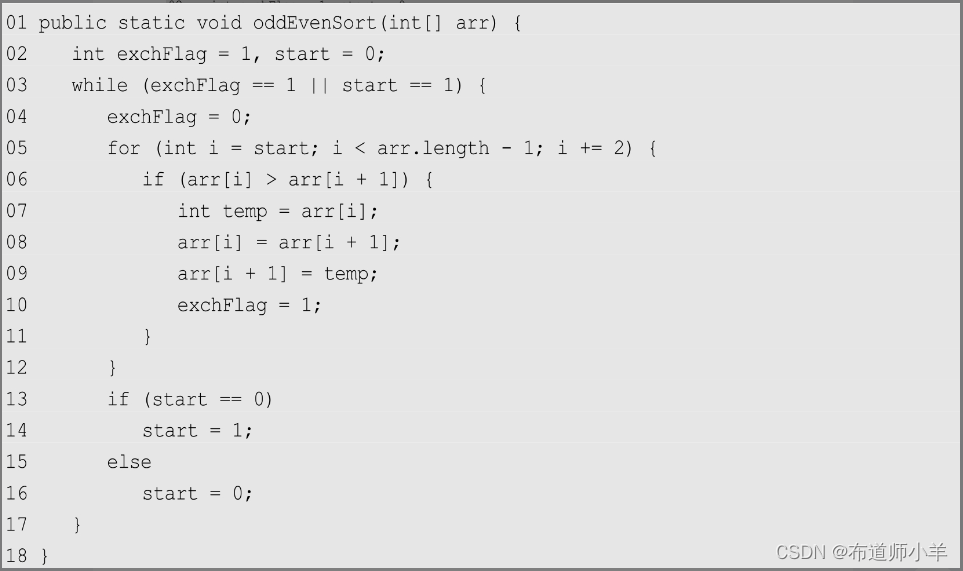
其中,exchFlag用来记录当前迭代是否发生了数据交换,而start用来表示是奇交换还是偶交换。初始时,start为0,表示进行偶交换,每次迭代结束后,切换start的状态。如果上一次比较交换发生了数据交换,或者当前正在进行的是奇交换,循环就不会停止,直到程序不再发生交换并且当前进行的是偶交换为止(表示奇偶交换已经成对出现)。
上述代码虽然是串行代码,但是已经可以很方便地改造成并行模式了:
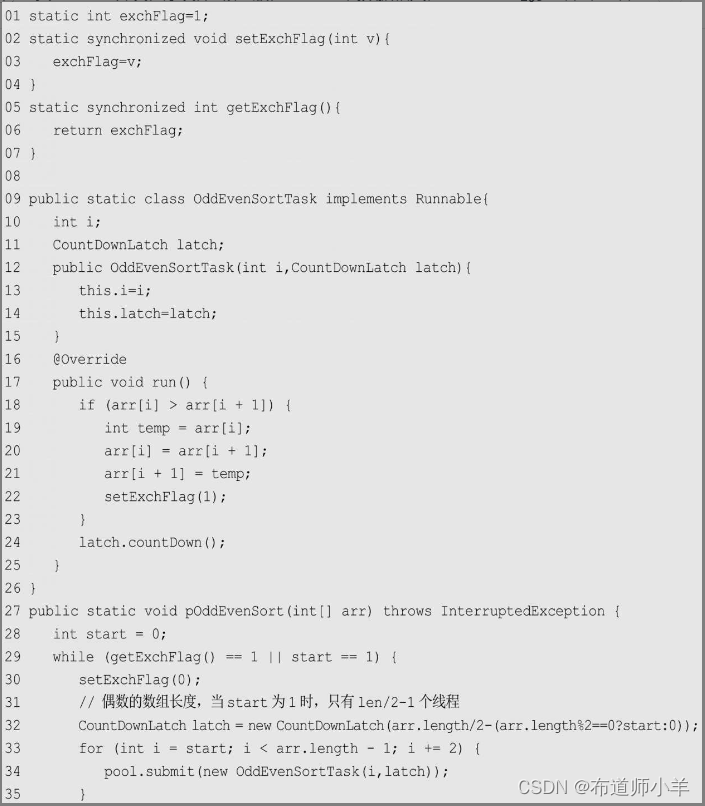
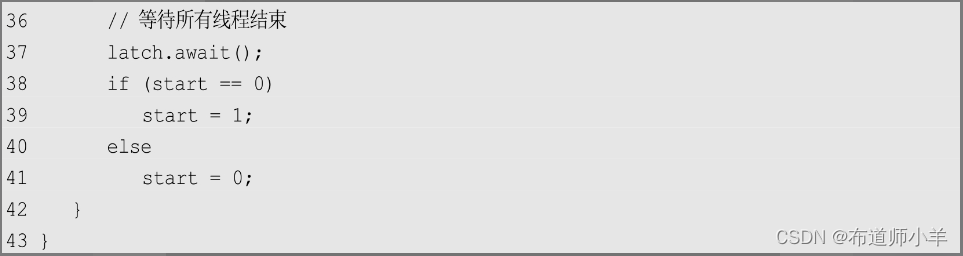
上述代码第9行定义了奇偶排序的任务类,该任务类的主要工作是数据比较和必要的交换(第18~23行)。并行排序的主体是pOddEvenSort()方法,它使用CountDownLatch记录线程数量,对于每一次迭代,使用单独的线程对每一次元素比较和交换进行操作。在下一次迭代开始前,必须等待上一次迭代所有线程执行完成。
3.2、改进的插入排序:希尔排序
插入排序也是一种很常用的排序算法。它的基本思想是:一个未排序的数组(当然也可以是链表)可以分为两个部分,前半部分是已经排序的,后半部分是未排序的。在排序时,只需要在未排序的部分中选择一个元素,将其插入前面有序的数组中即可。最终,未排序的部分会越来越少,直到为0,排序就完成了。初始时,可以假设已排序部分就是第一个元素。
插入排序示意图如下图所示:

插入排序的实现如下所示:

上述代码第6行提取准备插入的元素(也就是未排序序列中的第一个元素),然后在已排序队列中找到这个元素的插入位置(第8~10行)插入(第13行)即可。
简单的插入排序是很难并行化的。因为这一次的数据插入依赖于上一次得到的有序序列,所以多个步骤之间无法并行。为此,我们可以对插入排序进行扩展,这就是希尔排序。
希尔排序将整个数组根据间隔h分割为若干个子数组,它们相互穿插在一起,每一次排序时,分别对每一个子数组进行排序。当h为3时,希尔排序将整个数组分为交织在一起的三个子数组,如下图所示:
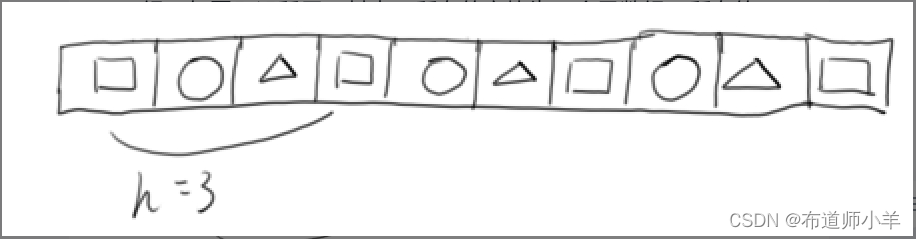
其中,所有的方块为一个子数组,所有的圆形和所有的三角形分别组成另外两个子数组。每次排序时,总是交换间隔为h的两个元素。
在每一组排序完成后,可以递减h的值,进行下一轮更加精细的排序。直到h为1,此时等价于一次插入排序。
希尔排序的一个主要优点是,即使一个较小的元素在数组的末尾,由于每次元素移动都以h为间隔进行,因此数组末尾的小元素可以在很少的交换次数下,就被置换到最接近元素最终位置的地方。
下面是希尔排序的串行实现:

上述代码第4~6行计算一个合适的h值,接着正式进行希尔排序。第8行的for循环进行间隔为h的插入排序,每次排序结束后,递减h的值(第20行)。直到h为1,退化为插入排序。
很显然,希尔排序每次都针对不同的子数组进行排序,各个子数组之间是完全独立的。因此,很容易改写成并行程序:

上述代码中ShellSortTask为并行任务。ShellSortTask的作用是根据给定的起始位置和h对子数组进行排序,因此可以完全并行化。
为控制线程数量,这里定义并行主函数pShellSort()在h大于或等于4时使用并行线程(第40行),否则退化为传统的插入排序。
每次计算后,递减h的值(第58行)。
4、并行算法:矩阵乘法
Linus认为并行程序目前只有在服务端程序和图像处理领域有发展的空间。且不论这种说法是否有局限性,从中也可以看出并行对于这两个应用领域的重要性。而对于图像处理来说,矩阵运行是其中必不可少的重要数学方法。当然,除图像处理外,矩阵运算在神经网络、模式识别等领域也有着广泛的用途。在这里,我将向大家介绍矩阵运算的典型代表——矩阵乘法的并行化实现。
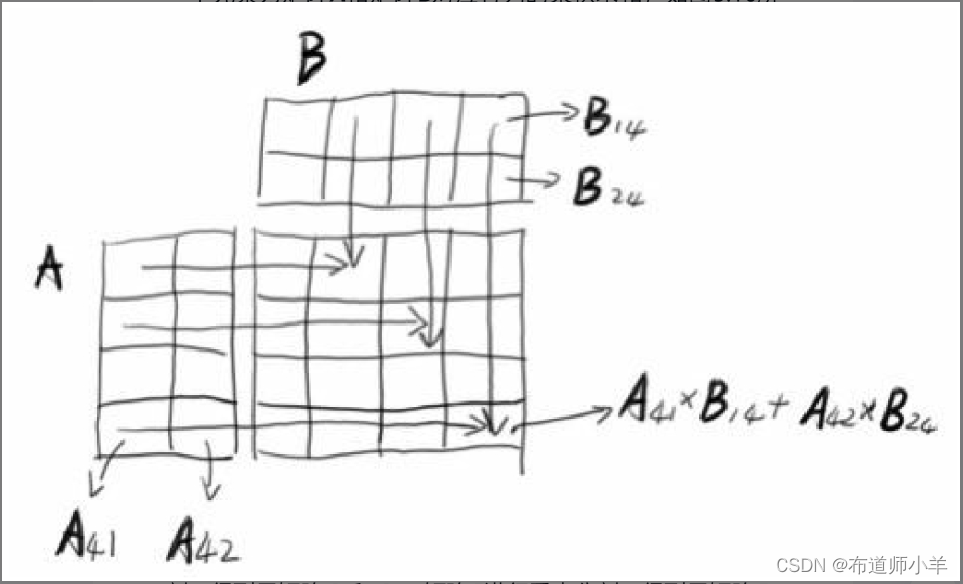
在矩阵乘法中,第一个矩阵的列数和第二个矩阵的行数必须是相同的。矩阵A和矩阵B相乘,其中矩阵A为4行2列,矩阵B为2行4列,它们相乘后,得到的是4行4列的矩阵,并且新矩阵中每一个元素为矩阵A和矩阵B对应行列的乘积求和,如下图所示:
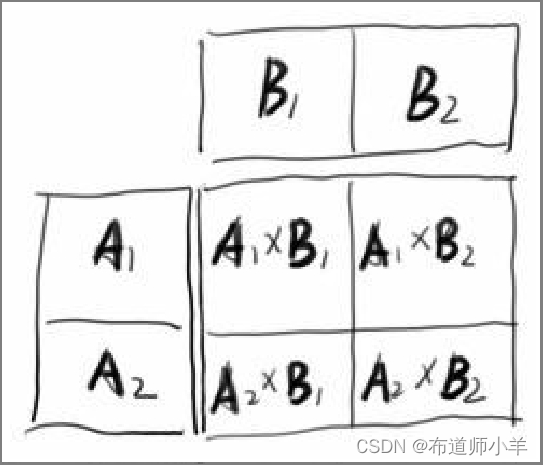
如果需要进行并行计算,一种简单的策略是将矩阵A进行水平分割,得到子矩阵A1和A2,矩阵B进行垂直分割,得到子矩阵B1和B2。此时,我们只要分别计算这些子矩阵的乘积,再将结果进行拼接就能得到原始矩阵A和B的乘积。下图展示了这种并行计算的策略:
当然,这个过程是可以反复进行的。为了计算矩阵A1×B1,我们还可以进一步将矩阵A1和矩阵B1分解,直到我们认为子矩阵的大小已经在可接受范围内。
















 823
823











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









