







 本文详细剖析了Java并行流中`reduce`操作的源码实现,特别关注了`Collection#parallelStream`和`ReduceOp#evaluateParallel`方法,揭示了其底层依赖的Fork/Join框架的工作原理。
本文详细剖析了Java并行流中`reduce`操作的源码实现,特别关注了`Collection#parallelStream`和`ReduceOp#evaluateParallel`方法,揭示了其底层依赖的Fork/Join框架的工作原理。
以求和为例,进行并行流的源码分析
并行流求和示例
求和的方式有很多种
第一种 long sum = LongStream.rangeClosed(1, 10).parallel().sum();
第二种 long sum = LongStream.rangeClosed(1, 10).parallel().reduce(0, Long::sum);
第三种 long sum = list.parallelStream().reduce(Long::sum).get();
源码分析
以第三种为例, Collection#parallelStream
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
default Stream<E> parallelStream() {
return StreamSupport.stream(spliterator(), true);
}
StreamSupport#stream 并行流和顺序流的区别就在于参数 parallel, 改参数最终对应的是AbstractPipeline#parallel属性。
public static <T> Stream<T> stream(Spliterator<T> spliterator, boolean parallel) {
Objects.requireNonNull(spliterator);
return new ReferencePipeline.Head<>(spliterator,
StreamOpFlag.fromCharacteristics(spliterator),
parallel);
}
再看reduce方法。
Stream#reduce --> ReferencePipeline#reduce --> AbstractPipeline#evaluate
final <R> R evaluate(TerminalOp<E_OUT, R> terminalOp) {
assert getOutputShape() == terminalOp.inputShape();
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
// 根据parallel属性选择走并行还是顺序操作
return isParallel()
? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags()))
: terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));
}
下面直接看并行操作
TerminalOp#evaluateParallel 这里是默认方法实现, 默认实现还是走的是顺序。
default <P_IN> R evaluateParallel(PipelineHelper<E_IN> helper,
Spliterator<P_IN> spliterator) {
if (Tripwire.ENABLED)
Tripwire.trip(getClass(), "{0} triggering TerminalOp.evaluateParallel serial default");
return evaluateSequential(helper, spliterator);
}
我们这里的TerminalOp是实际是ReduceOp, 重写了方法。
// 顺序
@Override
public <P_IN> R evaluateSequential(PipelineHelper<T> helper,
Spliterator<P_IN> spliterator) {
return helper.wrapAndCopyInto(makeSink(), spliterator).get();
}
// 并行
@Override
public <P_IN> R evaluateParallel(PipelineHelper<T> helper,
Spliterator<P_IN> spliterator) {
return new ReduceTask<>(this, helper, spliterator).invoke().get();
}
可以看到并行流走的是ReduceTask。从UML图可以看到继承了AbstractTask 从而也继承了ForkJoinTask,这也印证了并行流的底层是依赖了Fork/Join框架。

继续跟踪invoke方法。 走的是ForkJoinTask#invoke
public final V invoke() {
int s;
// 执行,Done状态 1 << 31,int类型小于0 其它状态都需要awaitDone
if ((s = doExec()) >= 0)
s = awaitDone(null, true, false, false, 0L);
if ((s & ABNORMAL) != 0)
reportException(s);
// 从AbstractTask的属性localResult中获取值
return getRawResult();
}
final int doExec() {
int s; boolean completed;
if ((s = status) >= 0) {
try {
// 执行
completed = exec();
} catch (Throwable rex) {
s = trySetException(rex);
completed = false;
}
// 完成状态 setDone
if (completed)
s = setDone();
}
return s;
}
其中exec方法在CountedCompleter#exec实现了
protected final boolean exec() {
compute();
return false;
}
下面就是Fork/Join任务执行的核心方法compute, 在AbstractTask中进行处理。我们自己在写Fork/Join任务的时候也是要重写这个compute方法。
public void compute() {
Spliterator<P_IN> rs = spliterator, ls; // right, left spliterators
// 预估分片中数据量
long sizeEstimate = rs.estimateSize();
// 根据预估的数据量计算最小单元阈值
long sizeThreshold = getTargetSize(sizeEstimate);
boolean forkRight = false;
@SuppressWarnings("unchecked") K task = (K) this;
// 当前分片数量 > 阈值 && 分片
while (sizeEstimate > sizeThreshold && (ls = rs.trySplit()) != null) {
K leftChild, rightChild, taskToFork;
// 拆分左任务和右任务
task.leftChild = leftChild = task.makeChild(ls);
task.rightChild = rightChild = task.makeChild(rs);
// 维护挂起子任务的pending
task.setPendingCount(1);
// 交替左右fork 可以优化拆分算法导致数据分片不均性能变差的情况
if (forkRight) {
forkRight = false;
rs = ls;
task = leftChild;
taskToFork = rightChild;
}
else {
forkRight = true;
// 一半任务继续执行
task = rightChild;
// 一半任务加入队列
taskToFork = leftChild;
}
// fork, 等待线程池处理
taskToFork.fork();
sizeEstimate = rs.estimateSize();
}
// 当任务已经分解到足够小的时候退出循环,尝试进行结束。
// doLeaf方法,串行完成最小计算单元的任务,并将结果设置到当前任务的localResult中
task.setLocalResult(task.doLeaf());
// 合并左右任务结果等操作
task.tryComplete();
}
其中 AbstractTask#getTargetSize 计算最小单元阈值。
private static final int LEAF_TARGET = ForkJoinPool.getCommonPoolParallelism() << 2;
public static long suggestTargetSize(long sizeEstimate) {
long est = sizeEstimate / getLeafTarget();
return est > 0L ? est : 1L;
}
public static int getLeafTarget() {
Thread t = Thread.currentThread();
if (t instanceof ForkJoinWorkerThread) {
return ((ForkJoinWorkerThread) t).getPool().getParallelism() << 2;
}
else {
// LEAF_TARGET = ForkJoinPool.getCommonPoolParallelism() << 2;
// 机器8c, 7 * 4 = 28
return LEAF_TARGET;
}
}
ArrayList.ArrayListSpliterator#trySplit 通过二分法进行拆分
public ArrayListSpliterator trySplit() {
int hi = getFence(), lo = index, mid = (lo + hi) >>> 1;
return (lo >= mid) ? null : // divide range in half unless too small
new ArrayListSpliterator(lo, index = mid, expectedModCount);
}
ReduceOps.ReduceTask#makeChild 方法得到的子任务中spliterator 就是上面二分的spliterator
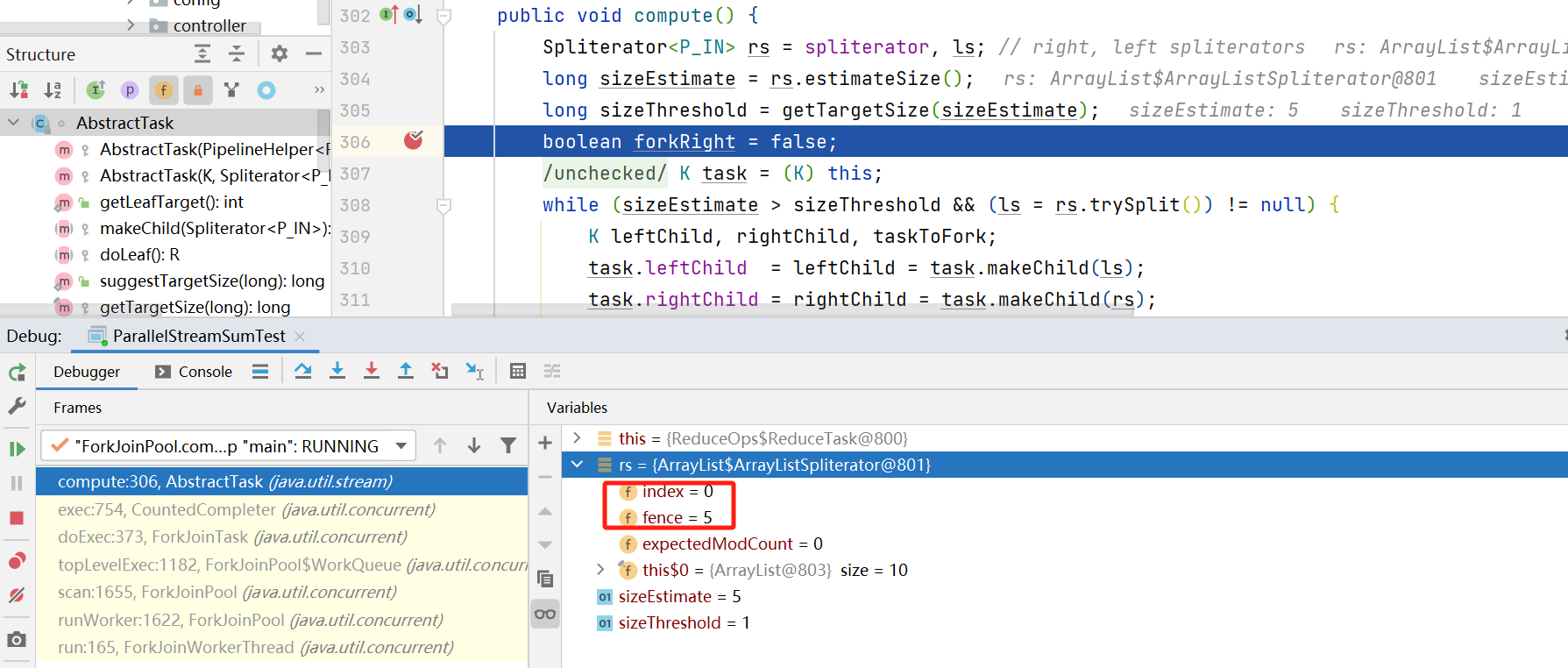
比如第一次循环
task.leftChild 中 index 0 fence 5
task.rightChild 中 index 5 fence 10
protected ReduceTask<P_IN, P_OUT, R, S> makeChild(Spliterator<P_IN> spliterator) {
return new ReduceTask<>(this, spliterator);
}
每次选一半的task进行fork,放入任务队列,然后另一半task接着进行拆分
- task:下次循环接着拆分的
- tasksToFork:进行fork放入队列的
在tasksToFork.fork方法放入队列后, 当取到该任务时,还会再次调用compute方法继续进行拆分。 这里就是Fork/Join相关的技术实现。如下图所见, 这里第一次循环的leftChild又一次走进来compute方法。
大致的调用链路如下:
- 加入队列, 创建线程
ForkJoinPool#externalPush --> ForkJoinPool#signalWork --> ForkJoinPool#createWorker --> ForkJoinWorkerThread.start
- 线程运行
ForkJoinWorkerThread#run --> ForkJoinWorkerThread#runWorker --> ForkJoinPool#scan --> ForkJoinPool.WorkQueue#topLevelExec --> ForkJoinTask#doExec --> CountedCompleter#exec --> AbstractTask#compute
ReduceOps.ReduceTask#doLeaf 串行完成叶子任务的计算
@Override
protected S doLeaf() {
return helper.wrapAndCopyInto(op.makeSink(), spliterator);
}
CountedCompleter#tryComplete 合并结果
public final void tryComplete() {
CountedCompleter<?> a = this, s = a;
for (int c;;) {
// pending为0 , 任务完成
if ((c = a.pending) == 0) {
a.onCompletion(s);
if ((a = (s = a).completer) == null) {
s.quietlyComplete();
return;
}
}
// 如果挂起计数为非0,则递减计数
else if (a.weakCompareAndSetPendingCount(c, c - 1))
return;
}
}
ReduceOps.ReduceTask#onCompletion
@Override
public void onCompletion(CountedCompleter<?> caller) {
// 如果该任务是中间节点会将左右子节点的结果进行合并
if (!isLeaf()) {
// 左任务结果
S leftResult = leftChild.getLocalResult();
// 左任务结果 合并(sum方法此处为 +) 右任务结果
leftResult.combine(rightChild.getLocalResult());
setLocalResult(leftResult);
}
// GC spliterator, left and right child
// 左右任务都置空
super.onCompletion(caller);
}
【本文完】















 333
333











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









