







1、MV-LSTM模型
(1)简介:
在论文A Deep Architecture for Semantic Matching with Multiple Positional Sentence Representations(Shengxian Wan∗ , Yanyan Lan† , Jiafeng Guo† , Jun Xu† , Liang Pang∗ , and Xueqi Cheng†)中提到,作者提出了一种基于双向LSTM网络的多语义模型。该模型能够更有效率的提取句子中的重要特征,并在实验中取得了不错的效果。这篇论文采用双向LSTM处理两个句子,然后对LSTM隐藏层的输出进行两两计算匹配度,作者认为这是一个Multi-View(MV)的过程,能够考察每个单词在不同语境下的含义。同时用双向LSTM处理句子,相当于用变长的窗口逐步的解读句子,实现多颗粒度考察句子的效果
(2)模型解决的问题:
在旧有的一些模型方法中,可能会出现以下的这种情况:
,以QA为例
Q:世界杯的前三名是哪几只队伍?
A1: 德国是世界杯冠军
A2: 欧洲杯的前三名是西班牙,荷兰,德国
从这两个回答中可以看到,A1把重点放在了‘世界杯’上,而A2则把重点放在了‘前三名‘上。这说明需要有一个模型能记住长距离上的特征,因此就可以考虑LSTM模型,可是单纯用LSTM会使得输出受到句尾的影响较大(这是由LSTM的结构决定的),所以作者选用了双向LSTM来解决这个问题,因为使用双向LSTM能获得更全面的句子信息。
(3)模型结构:
该模型首先将问题句子和答案句子分别用Bi-LSTM(bidirectional long short term memory)计算两个句子每个位置的向量表达,两个句子的不同位置进行交互形成新的矩阵和张量,然后接k-Max采样层和多层感知机进行降维。最后输出两个句子的相似度。(图一)
Bi-LSTM是将句子序列正向输入一次LSTM,然后再反向输入一次LSTM。这样每个时刻都有两个向量表达,分别是前向的和反向的最重要的是每一个时刻的向量表达都包含了整个句子的信息。Bi-LSTM中每个时刻的向量表达就是两个LSTM向量的拼接,即首先,将问题句子和答案句子输入到Bi-LSTM中,得到每个时刻的向量表达。然后将两个句子的各个时刻的向量进行交互,利用张量函数生成交互张量。张量函数是把两个向量映射成一个向量,公式如下:
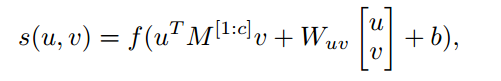
其中,u,v分别代表两个向量,Wi,i∈[1,…,c]是张量的一个切片。Wuv和b是线性变换的参数。f是非线性函数。经过张量函数变换后的结果是一个向量。
接来下利用k-Max采样从交互张量的每一个切片中选择出k个最大的值,然后将所有切片的值拼接成一个向量。最后需要用多层感知机将高维的向量降到一维的标量,这个标量经过线性变换后就是两个句子的相似度得分。公式如下:
![]()
其中,Wr和Ws是参数矩阵,br和bs是相应的偏置向量。

(4)模型优点:
这篇论文有3个创新点:1、使用了当时比较新型的双向LSTM模型,这种模型能考虑到句子的时序关系,能捕捉到长距离的单词依赖,而且采用双向的模型,能够减轻这种有顺序的模型权重偏向句末的问题。2、用Interaction tensor计算句子之间的两两匹配度,从多个角度解读句子。3、匹配计算公式采用了带参数的计算公式。
2、ARC-II模型
(1)基于CNN的句子建模
本次实验模型Arc-II原理来源于match-zoo所给论文。这篇论文主要针对的是句子匹配(Sentence Matching)的问题,但是基础问题是句子建模。首先,文中提出了一种基于CNN的句子建模网络。

图中灰色的部分表示对于长度较短的句子,其后面不足的部分填充的全是0值(Zero Padding)。可以看出,模型解决不同长度句子输入的方法是规定一个最大的可输入句子长度,然后长度不够的部分进行0值的填充;图中的卷积计算和传统的CNN卷积计算无异,而池化则是使用Max-Pooling。
下图示意性地说明了卷积结构的作用,作者认为卷积的作用是从句子中提取出局部的语义组合信息,而多张Feature Map则是从多种角度进行提取,也就是保证提取的语义组合的多样性;而池化的作用是对多种语义组合进行选择,过滤掉一些置信度低的组合(可能这样的组合语义上并无意义)。

简单来说,首先分别单独地对两个句子进行建模(使用上文中的句子模型),从而得到两个相同且固定长度的向量,向量表示句子经过建模后抽象得来的特征信息;然后,将这两个向量作为一个多层感知机(MLP)的输入,最后计算匹配的分数。
这个模型比较简单,但是有一个较大的缺点:两个句子在建模过程中是完全独立的,没有任何交互行为,一直到最后生成抽象的向量表示后才有交互行为(一起作为下一个模型的输入),这样做使得句子在抽象建模的过程中会丧失很多语义细节,同时过早地失去了句子间语义交互计算的机会。因此,推出了第二种模型结构。
(2)ARC-II
Arc-II模型以CNN为基础:
模型结构如下图:

第一层中,首先取一个固定的卷积窗口k1k1,然后遍历 SxSx 和 SySy 中所有组合的二维矩阵进行卷积,每一个二维矩阵输出一个值(文中把这个称作为一维卷积,因为实际上是把组合中所有词语的vector排成一行进行的卷积计算),构成Layer-2。下面给出数学形式化表述:
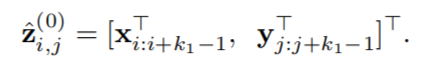
从而得到Layer-2,然后进行2×2的Max-pooling:

- 后续的卷积层
后续的卷积层均是传统的二维卷积操作,形式化表述如下:

- 二维卷积结果后的Pooling层
与第一层卷积层后的简单Max-Pooling方式不同,后续的卷积层的Pooling是一种动态Pooling方法'
3、两个不同数据集上模型的实验与结果对比分析(MV-LSTM,ARC-II)
1、MV-LSTM模型
(1)数据集:matchzoo-data-nlpir-100
- 经二十轮自动调参得到的最优参数如下:


LSTM模块的嵌入层输出的维度为6,单元数选择为32(最大匹配32字符),单元内的dropout底线为0.2.后续步骤中k-max 采样方法的K值为10(每一个张量切片中取前10个最大的特征值),最后使用MLP降维时所用的参数是:使用relu作为激活函数,构建3个隐藏层,每层含128个单元,最后输出64个单元的向量。
- 在一定的epoch下调整batch_size,得到最优batch_size=5.

c. 在最优的batch_size下测试epoch的影响,分别计算出epoch = 20,40,60,80,100,120,140,160,180,200,220 的 precision(精确率),accuracy(准确率),recall(召回率)及F1_score,并画图比较,选出最好结果,得到最优的epoch=60。比较图如下:

d. 测试最优的模型,batch_size=5,epoch=60,取20个测试样本,画出真实值与预测值对比图,分别计算出 precision(精确率),accuracy(准确率),recall(召回率)及F1_score


分别是 precision(精确率),accuracy(准确率),recall(召回率)及F1_score
(2) 数据集:SUS数据集
a. 经二十轮自动调参得到的最优参数如下:


b. 在一定的epoch下调整batch_size,得到最优batch_size=4.
c. 在最优的batch_size下测试epoch的影响,分别计算出epoch = 10,20,30,40,50,60,70,80,90,100 的 precision(精确率),accuracy(准确率),recall(召回率)及F1_score,并画图比较,选出最好结果,得到最优的epoch=90。比较图如下:

d. 测试最优的模型,batch_size=4,epoch=90,取50个测试样本,画出真实值与预测值对比图,分别计算出 precision(精确率),accuracy(准确率),recall(召回率)及F1_score


(precision(精确率),accuracy(准确率),recall(召回率)及F1_score)
2、ARC-II模型
(1)数据集:matchzoo-data-nlpir-100
a. 经二十轮自动调参得到的最优参数如下:

b. 在一定的epoch下调整batch_size,得到最优batch_size=2

c. 在最优的batch_size下测试epoch的影响,分别计算出epoch = 20,40,60,80,100,120,140,160,180,200,220 的 precision(精确率),accuracy(准确率),recall(召回率)及F1_score,并画图比较,选出最好结果,得到最优的epoch=160。比较图如下:

d. 测试最优的模型,batch_size=2,epoch=160,取20个测试样本,画出真实值与预测值对比图,分别计算出 precision(精确率),accuracy(准确率),recall(召回率)及F1_score


(precision(精确率),accuracy(准确率),recall(召回率)及F1_score)
(2)数据集:SUS数据集
a. 经二十轮自动调参得到的最优参数如下:


b. 在一定的epoch下调整batch_size,得到最优batch_size=4.
c. 在最优的batch_size下测试epoch的影响,分别计算出epoch = 10,20,30,40,50,60,70,80,90,100 的 precision(精确率),accuracy(准确率),recall(召回率)及F1_score,并画图比较,选出最好结果,得到最优的epoch=20。比较图如下:

d. 测试最优的模型,batch_size=4,epoch=20,取50个测试样本,画出真实值与预测值对比图,分别计算出 precision(精确率),accuracy(准确率),recall(召回率)及F1_score


(precision(精确率),accuracy(准确率),recall(召回率)及F1_score)















 4881
4881











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









