






一、伪分布式hadoop
详情请见:hadoop伪分布式安装-CSDN博客
二、spark
1.将spark安装包上传到linux虚拟机的/opt目录下
2.将spark安装包解压到/usr/local
![]()
3.进入解压后的spark安装目录的/conf目录下,复制spark-env.sh.template文件并重命名为spark-env.sh

4.配置环境变量
![]()
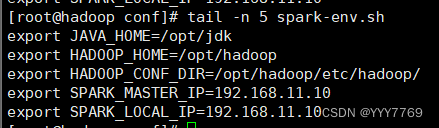
5.启动spark集群
切换到spark安装目录的/sbin目录下

6.验证
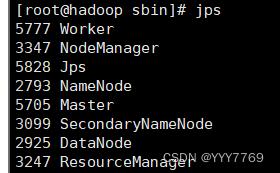
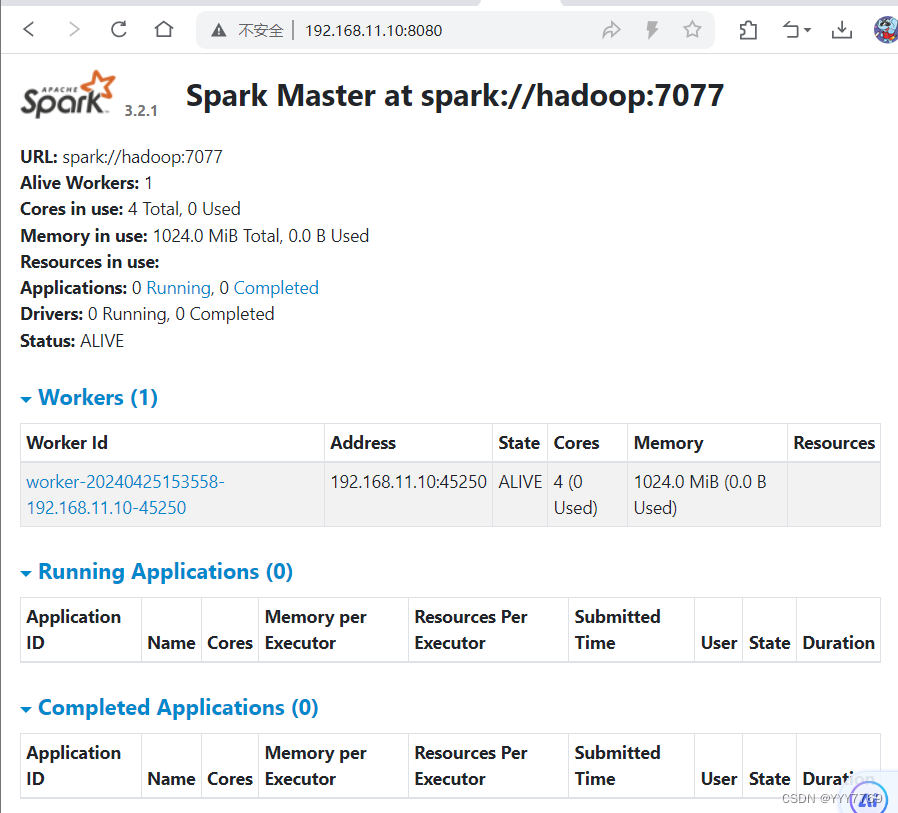
看见worker和master就说明spark集群启动成功
spark-shell

三、scala
1.将scala安装包上传到linux虚拟机的/opt目录下
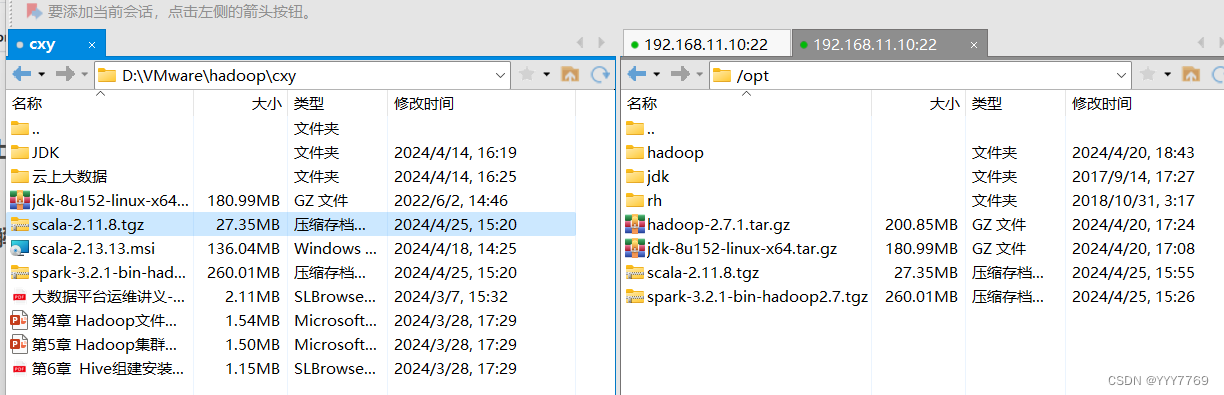
2.将spark安装包解压到/usr/local
![]()
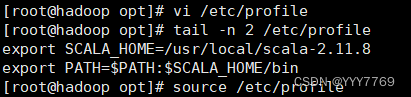
3.配置环境变量
使profile文件更新生效
4.验证
















 947
947

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









