






这篇文章主要介绍了学了python的心得体会200字,具有一定借鉴价值,需要的朋友可以参考下。希望大家阅读完这篇文章后大有收获,下面让小编带着大家一起了解一下。

Source code download: 本文相关源码
还没有接触Python时,我以为这门语言会和C++有着天壤之别,但当我真正开始接触它时,才发现,Python与C++非常相似却又非常不同,刚上手时,Python给我的第一感受就是舒服,自我感觉它比C++更容易上手,虽然之前一直在学习C++,但却没有一点不适应,Python给我的感觉就是非常的简洁,且跑出来的程序还非常高效与完整,正对应了“Python之禅”里的
"Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense."
Python的方方面面提起了我的学习兴趣,是我不停地向往深处学习,去感受Python更多的魅力,同时提升自己的能力,让自己变强。
学习Python第一周:
凭借着C++的基础,第一周的学习非常顺利,面对去年打了一学期的分支与循环,码起代码来得心应手,练习题也是毫无压力,但到后面我逐渐想到了一个问题,Python和C++终究是两种语言,我不能单凭靠着C++的编程逻辑来做Python,于是到后面开始逐渐向Python的编程逻辑靠拢,使用Python特有的知识来完成作业与练习Python Turtle绘制树。
第一天学习时,变量的类型令我眼前一亮:
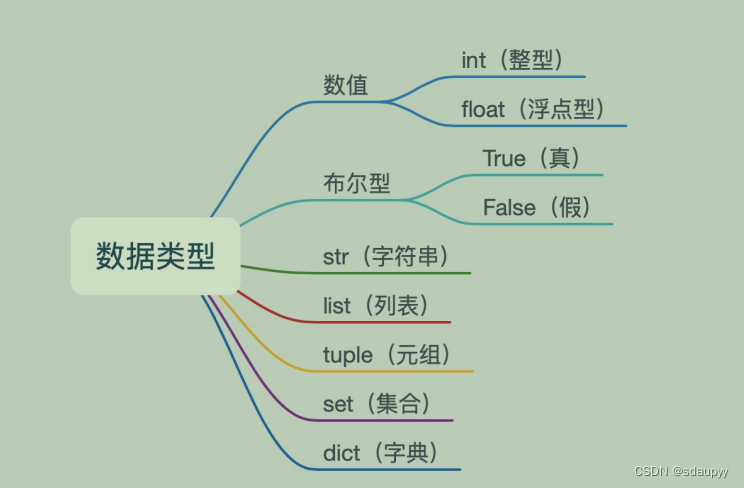
还有变量类型的转换:(红色表示的是最基础要用到的)
list1 = ['chuan', 'zhi', 'bo', 'ke']
t1 = ('aa', 'b', 'cc', 'ddd')
# 结果:chuan_zhi_bo_ke
print('_'.join(list1))
# 结果:aa...b...cc...ddd
print('...'.join(t1))j=1
i=1
while j<=5:
while i:
a=(2*i-1)*'*'
print(a.center(9,' '))
break
i+=1
j+=1
3.判断:
startswith():检查字符串是否是以指定⼦串开头,是则返回 True,否则返回 False。如果设 置开始和结束位置下标(可省略),则在指定范围内检查。 字符串序列.startswith(⼦串, 开始位置下标, 结束位置下标)
endswith()::检查字符串是否是以指定⼦串结尾,
isalpha():如果字符串⾄少有⼀个字符并且所有字符都是字⺟则返回 True, 否则返回 False。isdigit():如果字符串只包含数字则返回 True 否则返回 False。
isalnum():如果字符串⾄少有⼀个字符并且所有字符都是字⺟或数字则返 回 True,否则返回 False。
def cai():
print('--------------------')
print('1.添加联系人')
print('2.删除联系人')
print('3.查找联系人')
print('4.修改联系人信息')
print('5.显示全部联系人')
print('6.退出系统')
print(20*'-')
info=[]
def add():
name=input('请输入姓名:')
id=input('请输入id:')
tel=input('请输入电话:')
global info
for i in info:
if name==i['name']:
print('已有该联系人。')
return
info_zi={}
info_zi['name']=name
info_zi['id']=id
info_zi['tel']=tel
info.append(info_zi)
print(info)
def del_info():
name=input('请输入姓名:')
global info
for i in info :
if name == i['name']:
info.remove(i)
else: print('查无此人。')
print(info)
def finding():
name=input('请输入你要查找人的姓名:')
global info
for i in info :
if name==i['name']:
print(f"这个人的姓名是{i['name']},id是{i['id']},电话是{i['tel']}")
break
else:
print('查无此人。')
def change():
name=input('请输入你要修改的联系人姓名:')
global info
for i in info:
if name==i['name']:
i['tel']=input('请输入新的手机号:')
break
else:
print('查无此人。')
print(info)
def all():
global info
print('姓名\t学号\t电话')
for i in info:
print(f"{i['name']}\t{i['id']}\t{i['tel']}")
while 1:
cai()
a=int(input('请选择功能:'))
if a == 1:
add()
elif a==2:
del_info()
elif a==3:
finding()
elif a==4:
change()
elif a==5:
all()
elif a==6:
y=input('您确定要退出吗?yes or no:')
if y=='yes':
break
else:
print('格式错误,请重新输入。')
以及还有个小知识点,就是help(函数名),它用于查看函数的说明文档,写多行代码时能起很大方便。除此之外,也可以嵌套使用。
再进一步研究函数,会有位置参数、关键字参数、缺省参数、不定长参数(*args、**kwargs)、拆包和交换变量值,除此之外,还有函数的引用,由此可知:
---------------------------

打开用open(name,mode),其中mode就是上面表格中各种,,mode
写用write() #对象对象.write('内容')
读 用read()、readlines()、readline()
以及seek():⽂件对象.seek(偏移量, 起始位置)
关闭就用close()
接下来,就是比较头疼的文件备份:
# 1. 用户输入目标文件 sound.txt.mp3
old_name = input('请输入您要备份的文件名:')
# print(old_name)
# print(type(old_name))
# 2. 规划备份文件的名字
# 2.1 提取后缀 -- 找到名字中的点 -- 名字和后缀分离--最右侧的点才是后缀的点 -- 字符串查找某个子串rfind
index = old_name.rfind('.')
# print(index)
# 4. 思考:有效文件才备份 .txt
if index > 0:
# 提取后缀
postfix = old_name[index:]
# 2.2 组织新名字 = 原名字 + [备份] + 后缀
# 原名字就是字符串中的一部分子串 -- 切片[开始:结束:步长]
# print(old_name[:index])
# print(old_name[index:])
# new_name = old_name[:index] + '[备份]' + old_name[index:]
new_name = old_name[:index] + '[备份]' + postfix
print(new_name)
# 3. 备份文件写入数据(数据和原文件一样)
# 3.1 打开 原文件 和 备份文件
old_f = open(old_name, 'rb')
new_f = open(new_name, 'wb')
# 3.2 原文件读取,备份文件写入
# 如果不确定目标文件大小,循环读取写入,当读取出来的数据没有了终止循环
while True:
con = old_f.read(1024)
if len(con) == 0:
# 表示读取完成了
break
new_f.write(con)
# 3.3 关闭文件
old_f.close()
new_f.close()当中,还有个重要的os模板
# 1. 定义类:初始化属性、被烤和添加调料的方法、显示对象信息的str
class SweetPotato():
def __init__(self):
# 被烤的时间
self.cook_time = 0
# 烤的状态
self.cook_state = '生的'
# 调料列表
self.condiments = []
def cook(self, time):
"""烤地瓜方法"""
# 1. 先计算地瓜整体烤过的时间
self.cook_time += time
# 2. 用整体烤过的时间再判断地瓜的状态
if 0 <= self.cook_time < 3:
# 生的
self.cook_state = '生的'
elif 3 <= self.cook_time < 5:
# 半生不熟
self.cook_state = '半生不熟'
elif 5 <= self.cook_time < 8:
# 熟了
self.cook_state = '熟了'
elif self.cook_time >= 8:
# 烤糊了
self.cook_state = '烤糊了'
def add_condiments(self, condiment):
# 用户意愿的调料追加到调料列表
self.condiments.append(condiment)
def __str__(self):
return f'这个地瓜的被烤过的时间是{self.cook_time}, 状态是{self.cook_state}, 调料有{self.condiments}'
# 2. 创建对象并调用对应的实例方法
digua1 = SweetPotato()
print(digua1)
digua1.cook(2)
digua1.add_condiments('辣椒面儿')
print(digua1)
digua1.cook(2)
digua1.add_condiments('酱油')
print(digua1)
结果:
这个地瓜的被烤过的时间是0, 状态是生的, 调料有[]
这个地瓜的被烤过的时间是2, 状态是生的, 调料有['辣椒面儿']
这个地瓜的被烤过的时间是4, 状态是半生不熟, 调料有['辣椒面儿', '酱油']-----------------------------------------------那么,第二周的学习就到这了-------------------------------------------
-----------------------------------------------------------第三周-------------------------------------------------------------
相对于第二周,第三周是对第二周更深的研究与学习,更加丰富了,例如继承、类方法、异常、模块与包。
继承:有单继承和多继承;
⼦类和⽗类具有同名属性和⽅法,默认使⽤⼦类的同名属性和⽅法。
当然,可以用get_xx来获取私有值,用set_xx来修改私有值。
类属性与类方法:
首先先了解一下多态,多态指的是⼀类事物有多种形态,(⼀个抽象类有多个⼦类,因⽽多态的概念依赖于继承)。