







目录
1.数据导出的关键代码路径
数据导出器的顶层接口:io.camunda.zeebe.exporter.api.Exporter
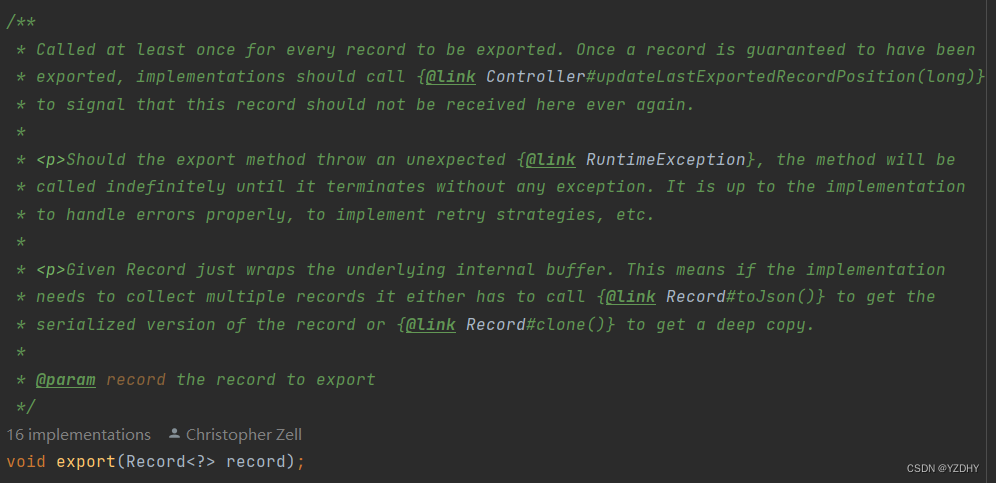
1.1 exporter的配置加载:
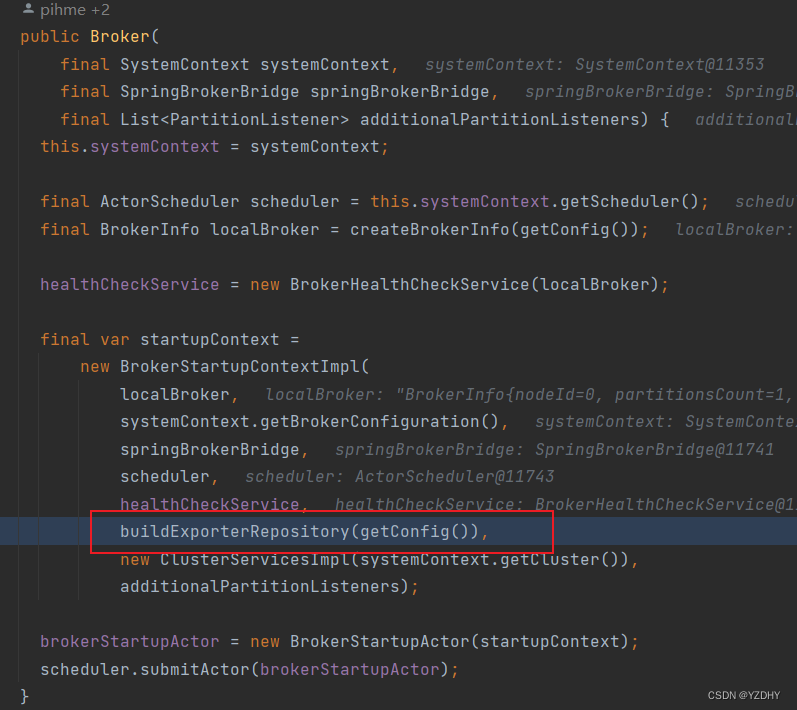
io.camunda.zeebe.broker.Broker#buildExporterRepository
取出exporters的配置,并遍历加载数据
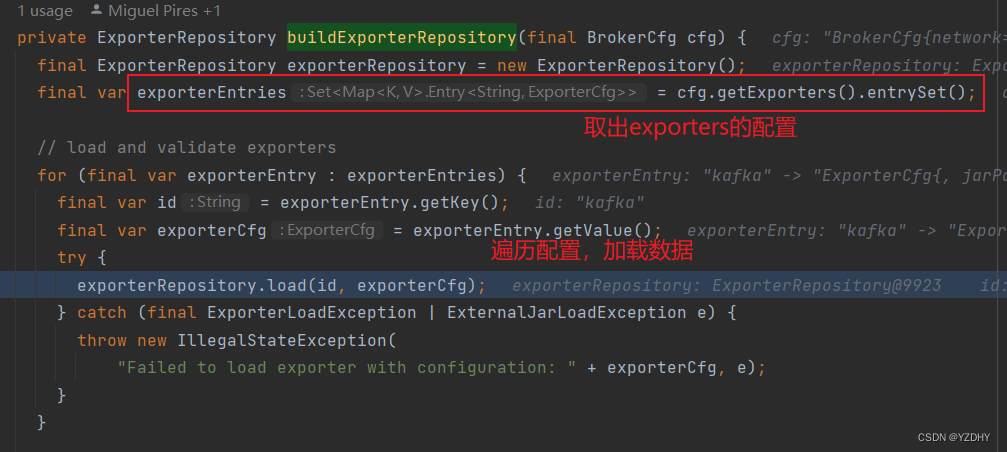
最终调用 io.camunda.zeebe.broker.exporter.repo.ExporterRepository#validate 做实例创建、配置校验
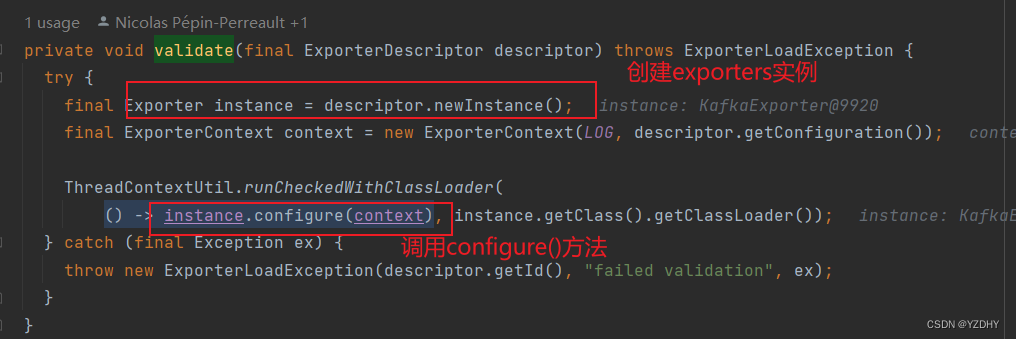
1.2 exporters的实例化
io.camunda.zeebe.broker.exporter.stream.ExporterDirector#ExporterDirector
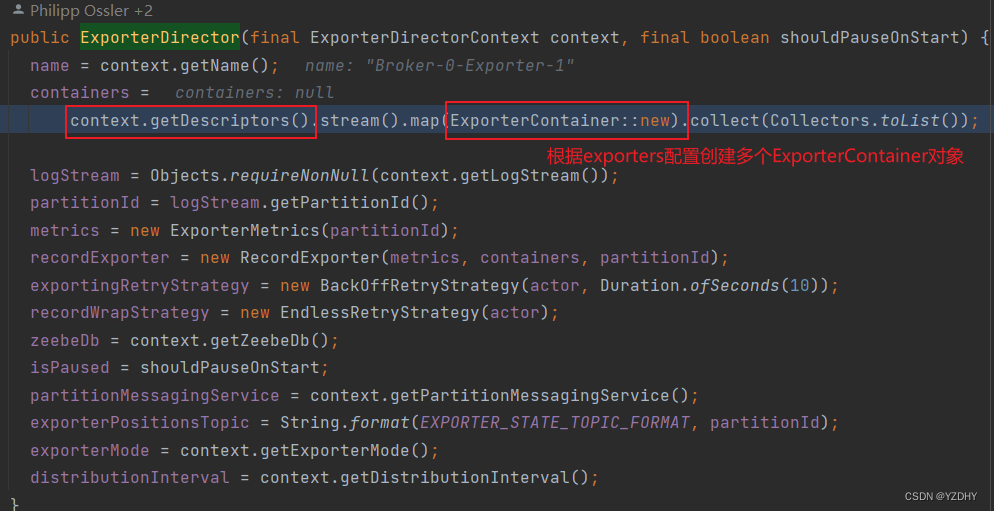
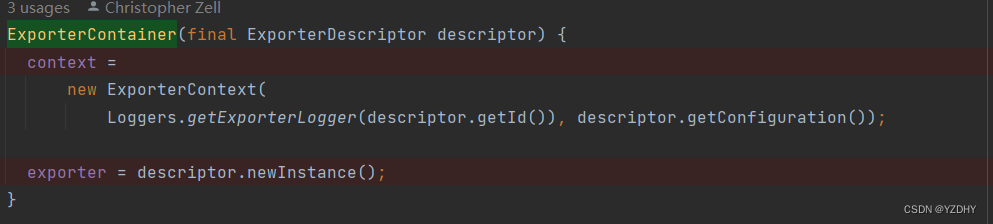
根据配置创建对应的context 和 exporter ;注意此处是循环创建,即配置多个exporters,则创建多个ExporterContainer
初始化 container,即调用exporter的configure() 方法 io.camunda.zeebe.broker.exporter.stream.ExporterDirector#initContainers
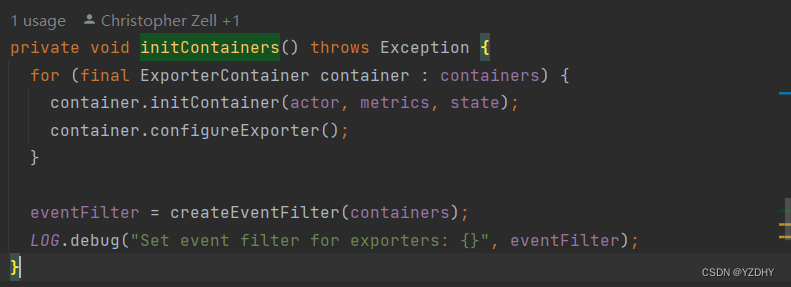
1.3 导出数据
创建了exporter之后如何执行数据的导出呢?
数据导出的调用链为:
——>io.camunda.zeebe.broker.exporter.stream.ExporterDirector#onActorStarted
——>io.camunda.zeebe.broker.exporter.stream.ExporterDirector#startActiveExportingMode
——>io.camunda.zeebe.broker.exporter.stream.ExporterDirector#readNextEvent
readNextEvent()方法通过 logStreamReader 读取当前事件
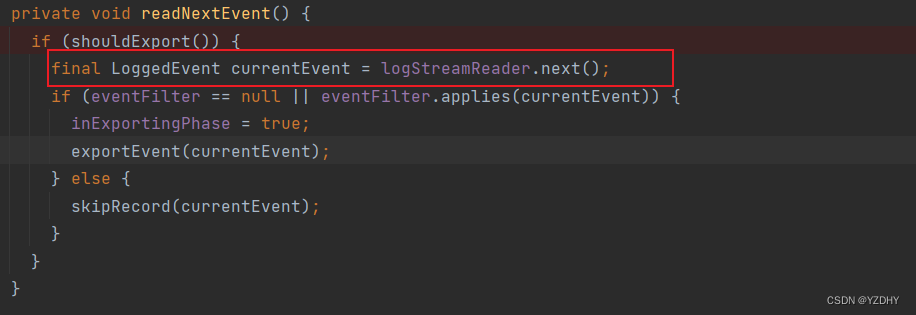
——>io.camunda.zeebe.broker.exporter.stream.ExporterDirector#exportEvent
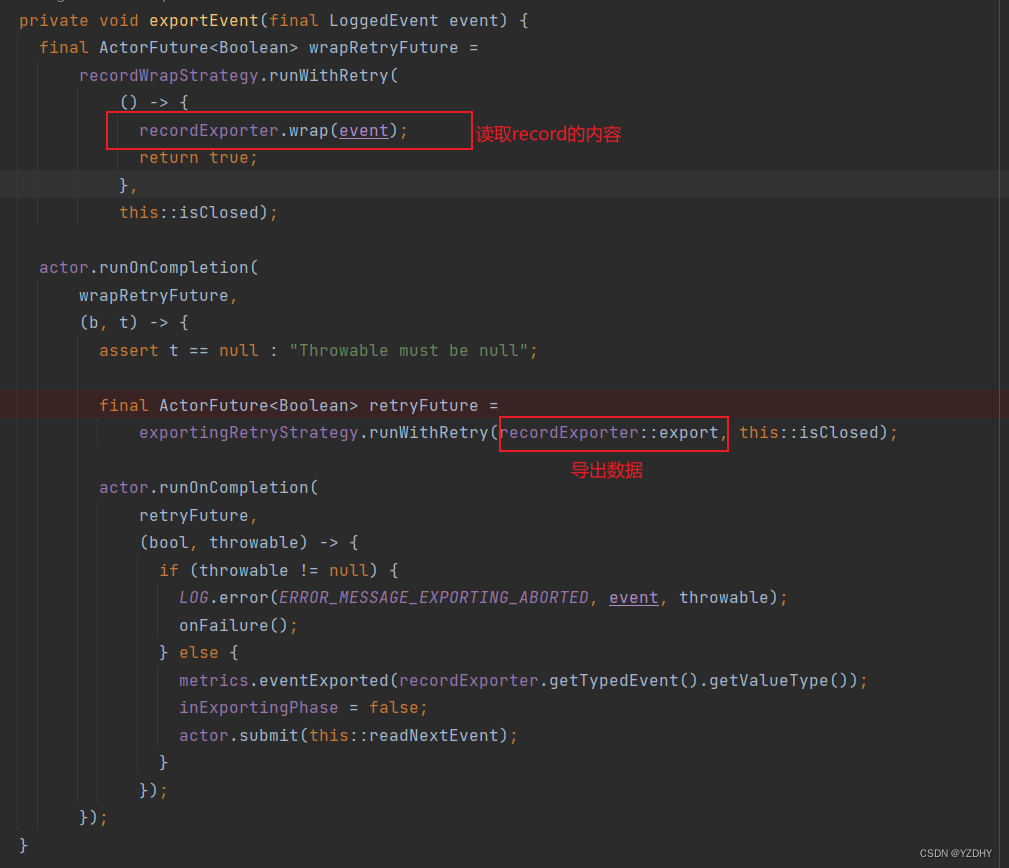
——>io.camunda.zeebe.broker.exporter.stream.ExporterDirector.RecordExporter#export
具体的record的数拼接、导出都是委托 recordExporter 实现的
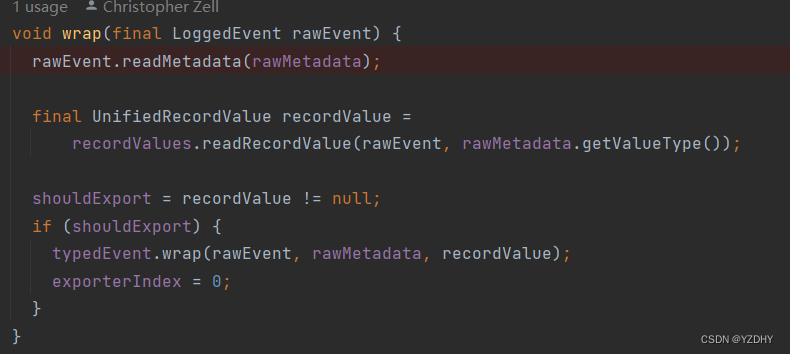
recordExporter.wrap(event); 读取record数据,组装数据到 typedEvent字段
recordExporter.export() 导出数据,最后导出的也是 typedEvent字段
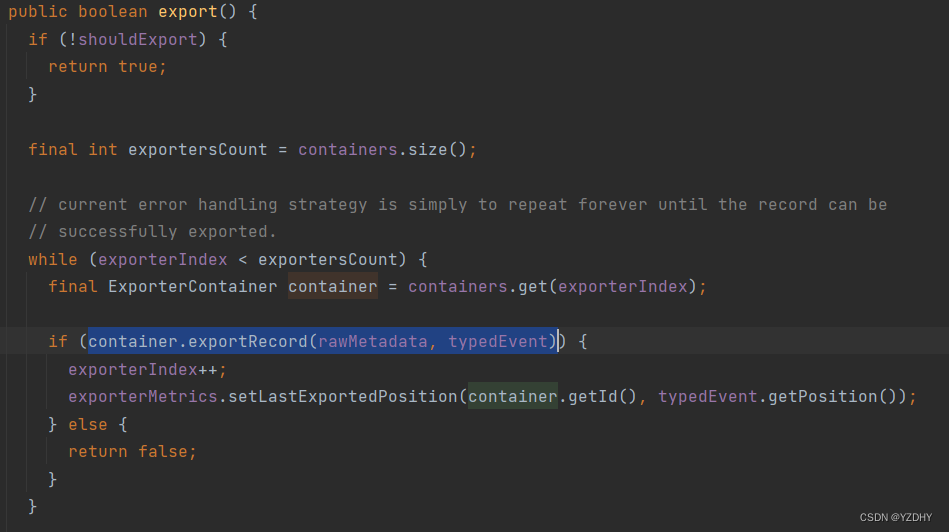
——>io.camunda.zeebe.broker.exporter.stream.ExporterContainer#exportRecord
——>io.camunda.zeebe.broker.exporter.stream.ExporterContainer#export
——>io.camunda.zeebe.exporter.api.Exporter#export
Exporter#export 调用的就是各个具体的实现了,若需要自定义exporter,主要的逻辑就写在改方法中。
2.导出的数据类型:
导出的数据被抽象为Record (io.camunda.zeebe.protocol.record.Record),
zeebe中record 通过枚举定义了不同的类型 :io.camunda.zeebe.protocol.record.ValueType
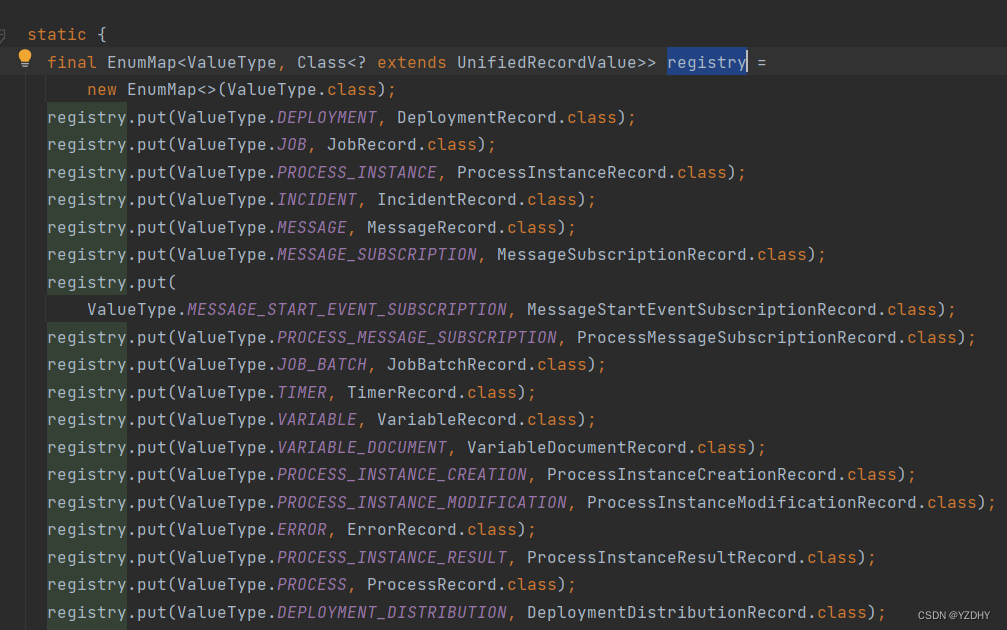
不同的valueType对应着不同的record实现,映射关系管理在 io.camunda.zeebe.stream.impl.TypedEventRegistry
2.1.数据导出到ES的数据
ES的索引命名规则:
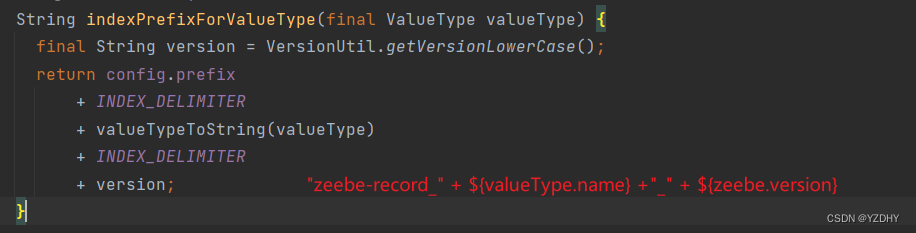
io.camunda.zeebe.exporter.RecordIndexRouter#indexFor
io.camunda.zeebe.exporter.RecordIndexRouter#indexPrefixForValueType

3.record的数据来源
主节点将request发送至对应的follower方法是 LeaderAppender#appendEntries(io.atomix.raft.cluster.impl.RaftMemberContext)
之后调用链为:
LeaderAppender#sendAppendRequest
——> LeaderAppender#handleAppendResponse
——> LeaderAppender#handleAppendResponseOk
——> LeaderAppender#commitEntries
——>RaftContext#setCommitIndex
此时会调用 notifyCommitListeners(commitIndex) 通知所有的listener
最终会通知所有的recordAwaiter ( 核心方法):io.camunda.zeebe.logstreams.impl.log.LogStreamImpl#notifyRecordAwaiters

awaiter的实现就是broker的几个关键流程:
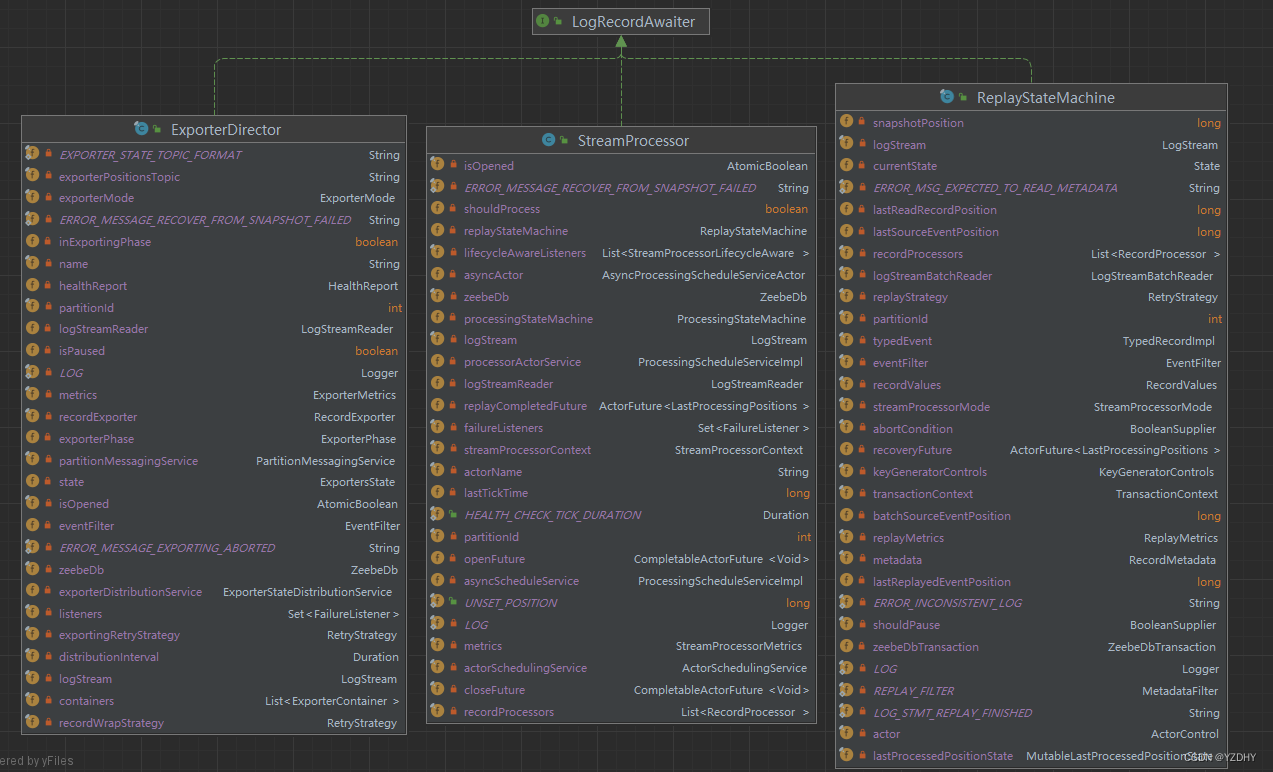
读取的record分别交给三个执行器处理:StreamProcessor、ExporterDirector、ReplayStateMachine执行,其中 ExporterDirector 就衔接到上述1.3节;
record的数据又是从哪里来的呢?进一步分析可以发现,是读取的log文件,具体参见下节
3.1 LogStreamReaderImpl
io.camunda.zeebe.broker.exporter.stream.ExporterDirector#onRecordAvailable
该方法就是由 LogStreamImpl#notifyRecordAwaiters 触发
——>io.camunda.zeebe.broker.exporter.stream.ExporterDirector#readNextEvent
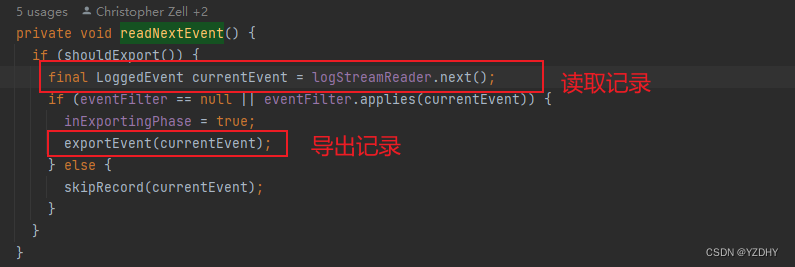
导出逻辑的主流程读取record的方法为:io.camunda.zeebe.logstreams.impl.log.LogStreamReaderImpl#next
通过LogStreamReaderImpl 取数的逻辑分两步:
1.判断是否有可读数据 : io.camunda.zeebe.logstreams.impl.log.LogStreamReaderImpl#hasNext
2.读数: io.camunda.zeebe.logstreams.impl.log.LogStreamReaderImpl#next
调用hasNext() 方法时,会调用 io.camunda.zeebe.logstreams.impl.log.LogStreamReaderImpl#readNextBlock

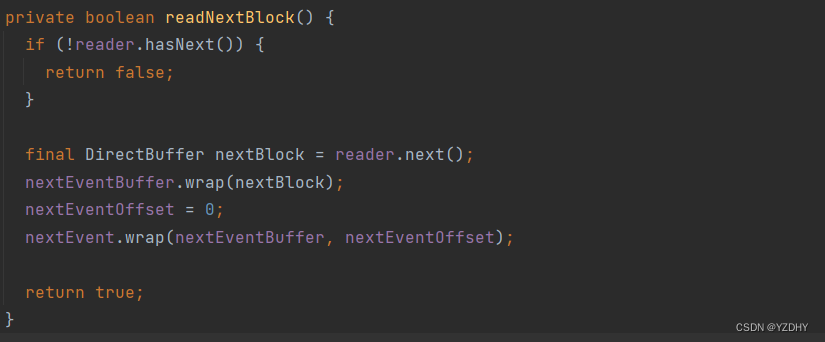
此时是委托 委托 io.camunda.zeebe.logstreams.storage.LogStorageReader 将数据(buffer)读取到 nextEventBuffer 、 nextEvent对象中,之后的next()方法,将nextEventBuffer中的数据存入currentEventBuffer中,currentEvent引用的数据内容随之变化
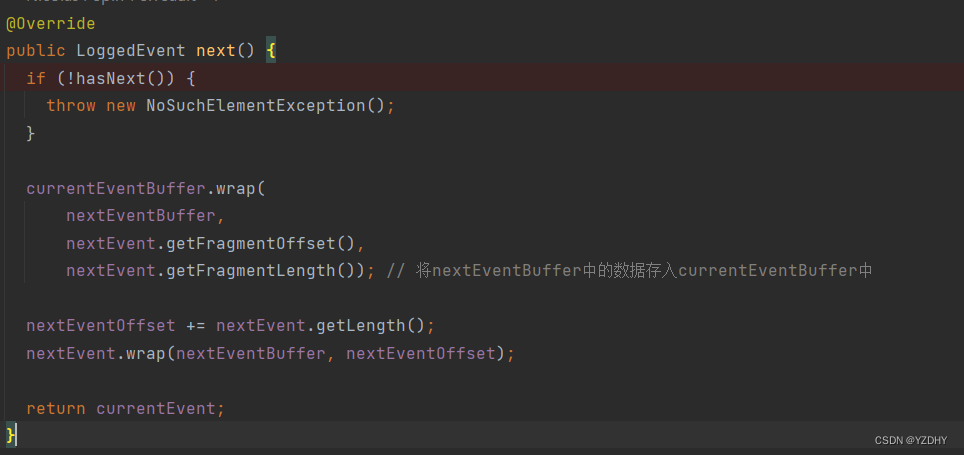
3.2 LogStorageReader
上节中调用的reader的实现为:
io.camunda.zeebe.broker.logstreams.AtomixLogStorageReader#next
创建reader : io.camunda.zeebe.broker.logstreams.AtomixLogStorage#newReader

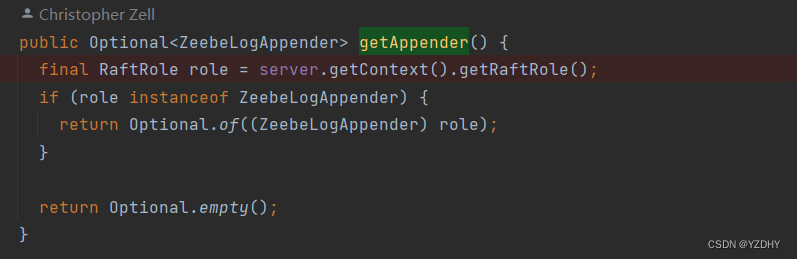
3.3 日志写入器logAppender : LeaderRole
io.atomix.raft.partition.impl.RaftPartitionServer#getAppender
基于server的一个log对象创建(待单章分析log的写入)














 147
147











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









