








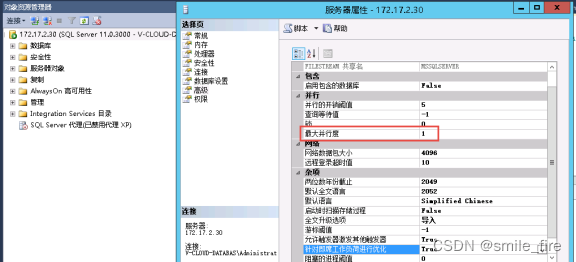
--调整最大并行度,建议修改为1,也可在数据库直接执行,修改方法如下:
sp_configure 'show advanced options', 1;
GO
RECONFIGURE WITH OVERRIDE;
GO
sp_configure 'max degree of parallelism', 1;
GO
RECONFIGURE WITH OVERRIDE;
GO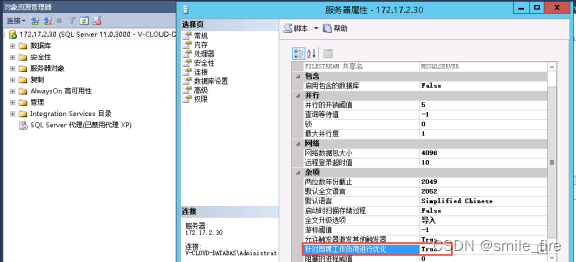
--调整针对即席工作负荷进行优化=True,也可在数据库直接执行,修改方法如下:
sp_configure 'show advanced options', 1;
GO
RECONFIGURE WITH OVERRIDE;
GO
sp_configure 'Optimize for Ad hoc Workloads', 1;
GO
RECONFIGURE WITH OVERRIDE;
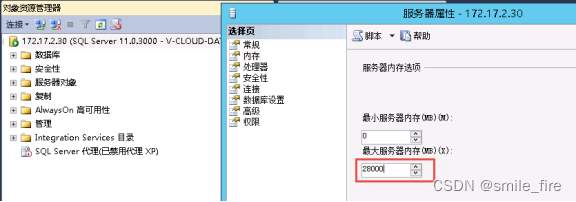
GO建议最大内存配置为物理内存-4GB(预留4GB内存给数据库服务器所在的操作系统使用,如下图数据库服务器物理内存有32G,这里我们设置为28000MB就好了)
路径:Windows设置-安全设置-本地策略-用户权限分配-锁定内存页
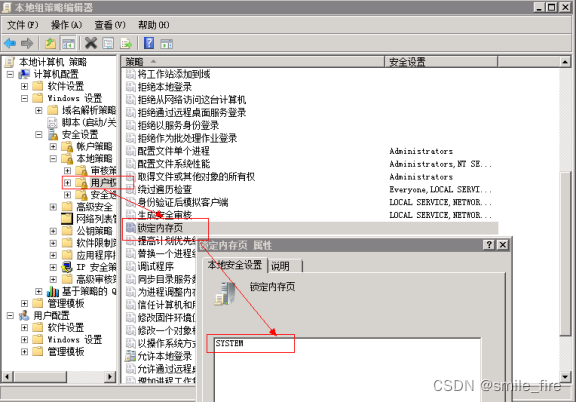

操作步骤:
注意,客户环境下按照下面的顺序进行执行:
- 停止操作系统服务下面的K3CloudJobProcess和K3CloudManage服务;
- 停止IIS服务;
- 在数据库服务器按附1执行修改语句,检查无误后,执行;
- 重新启动IIS;
- 启动K3CloudJobProcess和K3CloudManage服务。
附1:
下面是执行修改的SQL语句:
--开启read_committed_snapshot隔离级别的方法,推荐值是1:
--打开SQL Server Management Studio,创建一个查询,然后执行下面的语句,
--查看数据库对应的is_read_committed_snapshot_on是否为0,如果为0,做第2步。
--请自行替换name字段值。
select name,is_read_committed_snapshot_on from sys.databases where name = 'AIS20140912092851'--执行下面的SQL,开启读快照隔离级别。注意,执行的时候最好不要有人在使用数据库,
--否则由于KILL进程会导致客户端操作失败。
--请自行替换dbname字段值。
use master
declare @dbname as sysname
declare @sql varchar(max)
--@dbname='test' 为金蝶云星空对应的数据库名
set @dbname='AIS20140912092851'
set @sql=''
select @sql=@sql+' kill '+cast(spid as varchar)+';' from master..sysprocesses where dbid=db_id(@dbname);
set @sql=@sql+'alter database '+@dbname+' set read_committed_snapshot on ' ;
exec(@sql);--再次执行步骤1,如果对于那个数据库is_read_committed_snapshot_on的值为1,表示成功启用读快照隔离级别
使用云报告生成,查看数据库表索引碎片超过30%的表的数量,如果该值大于100,说明索引碎片较高,需要管理员根据情况进行处理。

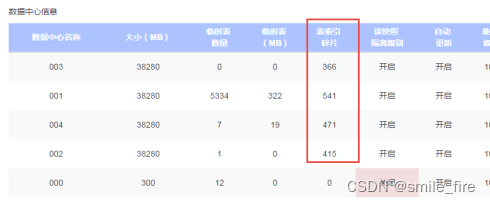
我们也可以根据一些比较重要的表的表索引碎片大于30%
比如:物料T_BD_Material,使用命令
dbcc ShowContig(‘T_BD_Material’),查看逻辑扫描碎片的百分比:

逻辑扫描碎片=35.85%大于30%,我们认为该数据库的索引碎片较多,影响到查询性能,建议重建索引和更新统计信息。
对数据查询速度要求较高,并且数据新增、删除、更新频繁,建议每天凌晨时分业务不繁忙的时候(比如凌晨3点),定期重建一次索引。
定时自动执行的方法:
方法一:使用金蝶云星空计划任务定期执行重建索引和更新统计信息。
详情可参考:
金蝶云社区|专业的产业互联网社区|财务金融企业信息化|IT精英人脉社群-金蝶云社区官网
执行定期重建索引和更新统计信息的后台计划任务未执行,原因排查:
第一步: 登录管理中心,检查数据中心是否勾选了 "允许执行计划任务"
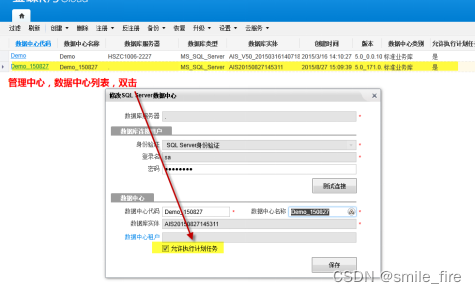
第二步:查看金蝶云星空服务器,K3CloudJobProcess服务是否启用
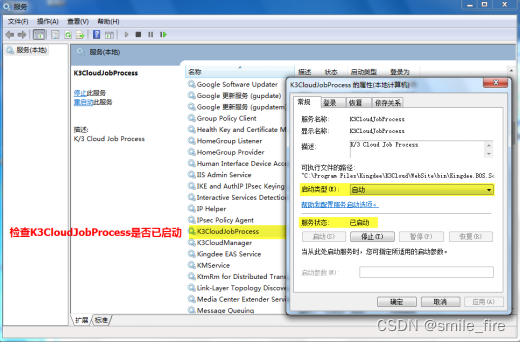
第三步:确认重建索引和更新统计信息的执行计划设置是否正确?
开始时间:必须在今天之前
结束时间:必须在今天以后
任务状态:必须是准备状态
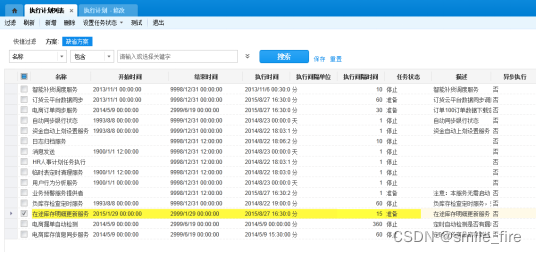
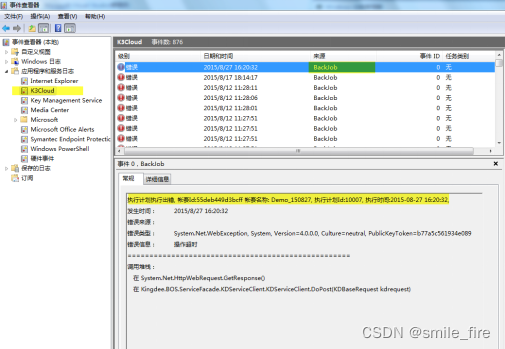
第四步:检查Windows系统日志,查看执行计划是否有出错
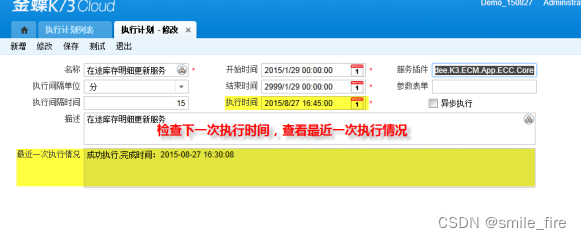
第五步:检查重建索引和更新统计信息的执行计划最近一次执行情况
如果执行时间已经刷新,且记录了最近一次执行情况,则说明执行计划能正常调用
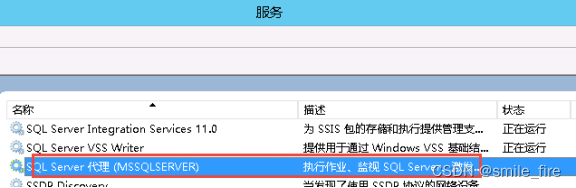
方法二:使用SQL Server的维护计划向导新建一个重新生成索引的维护任务。

维护计划执行需要把SQLServerAgent服务启动起来。
手工执行办法:
方法一:登录管理中心,使用数据中心列表的升级下拉功能:数据库优化,进行索引重建和更新统计信息。这个过程可能运行较长时间,并且会导致表阻塞,影响系统性能,请在非系统频繁使用期,进行优化。
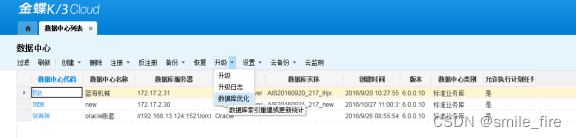
方法二:手工简单重建索引办法
--在对应的业务数据库执行下列的语句:
declare @sql varchar(max)
set @sql=''
select @sql=@sql+'dbcc dbreindex('+name+');' from sys.tables where name not like 'tm%'
exec(@sql)注意:
- 打补丁后,特别是跨度较大的补丁,建议手工重建一次;
- 请在业务空闲期执行重建索引的语句或任务;
可通过下列SQL语句查询和统计可删除的临时表数量:
--临时表数量统计
SELECT count(T.NAME) AS COUNT_DEL
FROM
SYS.TABLES T
WHERE
EXISTS (SELECT 1
FROM
T_BAS_TEMPORARYTABLENAME
WHERE
FTABLENAME = T.NAME
AND (FCREATEDATE <= getdate() - 1
OR FPROCESSTYPE = 1)) 如果临时表很多,想统计下临时表占用空间,可使用下面的语句进行统计分析:
-- 查看系统所有临时表占用的总空间
select cast(sum(a.total_pages)*8/1024 as varchar)+' MB' total
from sys.partitions p join sys.allocation_units a on p.partition_id = a.container_id
join sys.tables it on p.object_id = it.object_id
where it.name like 'TMP%'-- 查询系统中每个临时表占用的空间大小统计
select it.name, cast(sum(a.total_pages)*8 as varchar)+'KB' total
from sys.partitions p join sys.allocation_units a on p.partition_id = a.container_id
join sys.tables it on p.object_id = it.object_id
where it.name like 'tm%'
group by it.name
order by sum(a.total_pages)*8 desc--删除所有已经标记为需要删除的临时表,如果临时表太多,超过2w,不建议使用该语句删除临时表
declare @sql as varchar(max)
set @sql=''
select @sql=@sql+'drop table '+name+';' from sys.tables u
join T_BAS_TEMPORARYTABLENAME v on u.name=v.FTABLENAME and
( v.FPROCESSTYPE=1 or v.FCREATEDATE<GETDATE()-1);
exec(@sql);
delete u from T_BAS_TEMPORARYTABLENAME u where
not exists(select 1 from sys.tables where u.ftablename=name );--如果临时表太多,超过2w,建议使用SQL的定时作业来删除临时表
具体可参考:
金蝶云社区|专业的产业互联网社区|财务金融企业信息化|IT精英人脉社群-金蝶云社区官网
另外,我们可通过执行下面3个查询数量,根据查询数量的情况,来判断临时表方面的问题:
select count(*) from T_BAS_TEMPORARYTABLENAME where FPROCESSTYPE=1 or FCREATEDATE<GETDATE()-1
select count(*) from T_BAS_TEMPORARYTABLENAME
select count(*) from sys.tables t where name like 'tmp%' --如果语句1的记录很多(正常值一般1000内),那么后台删除临时表的作业肯定有一段时间没有运行;
--如果语句2的记录很多(正常值一般10000内),那么说明有临时表残留;
--如果语句3的记录很多(正常值一般10000内),并且如果语句3远大于语句2的记录数,说明很多生成的临时表没有记录到登记表中,属于异常情况,一般是二开或其他原因导致的临时表问题,如果这个记录数一直增长,那么需要手工执行删除临时表的语句。
SQLserver手工删临时表的方法(可在业务期间运行,推荐使用该方法删除临时表):
--第一步:删除登记表中的可删除的临时表登记记录
delete from T_BAS_TEMPORARYTABLENAME where FPROCESSTYPE=1 or FCREATEDATE<GETDATE()-1--第二步:删除临时表,每次删除50个临时表释放一次资源,可在业务运行期间执行语句
if object_id('temptb','table')>0 drop table temptb;
declare @sql varchar(max)
declare @icount int
declare @I int
set @sql='drop table '
set @i=1
select name,IDENTITY(int,1,1) id into temptb from sys.tables t where name like 'tmp%' and len(name)=30 and name not like 'tmp[_]%'
and not exists(select 1 from T_BAS_TEMPORARYTABLENAME where FTABLENAME=t.name) and create_date<=DATEADD(n,-5, GETDATE())
select @icount=@@ROWCOUNT
while @i<@icount
begin
select @sql=@sql+name+',' from temptb where id between @i and @i+49
if @@ROWCOUNT>0
set @sql=substring(@sql,1,len(@sql)-1)+';'
set @i=@i+50
exec(@sql)
set @sql='drop table '
end
if object_id('temptb','table')>0 drop table temptb;
--清理视图定义
declare @sql varchar(max)
set @sql=''
select @sql=@sql+'drop view '+name+char(13) from sys.views where name like 'tmp%' and len(name)=30 and name not like 'tmp[_]%'
if len(@sql)>0
exec(@sql)
--清理记录表
truncate table t_bas_temporarytablename
DBCC DBREINDEX(' t_bas_temporarytablename ');执行删除临时表的后台计划未执行,原因排查:
第一步: 登录管理中心,检查数据中心是否勾选了 "允许执行计划任务"
第二步:查看金蝶云星空服务器,K3CloudJobProcess服务是否启用
第三步:确认删除临时表的执行计划设置是否正确?
开始时间:必须在今天之前
结束时间:必须在今天以后
任务状态:必须是准备状态
第四步:检查Windows系统日志,查看执行计划是否有出错
第五步:检查删除临时表的执行计划最近一次执行情况
如果执行时间已经刷新,且记录了最近一次执行情况,则说明执行计划能正常调用
--查看是否存在阻塞语句
select * from master..sysprocesses where blocked<>0- 返回记录说明存在阻塞
- 如果隔几秒再次执行,没有记录返回,那可能属于正常的阻塞
--查询死锁信息语句
SELECT XEventData.XEvent.value('@timestamp', 'datetime2(3)'),
cast(XEventData.XEvent.value('(data/value)[1]', 'varchar(max)') as xml)
FROM (SELECT CAST (target_data AS XML) AS TargetData
FROM sys.dm_xe_session_targets st
JOIN sys.dm_xe_sessions s ON s.address = st.event_session_address
WHERE [name] = 'system_health' AND st.target_name = N'ring_buffer') AS Data
CROSS APPLY TargetData.nodes ('//RingBufferTarget/event') AS XEventData (XEvent)
WHERE XEventData.XEvent.value('@name', 'varchar(4000)') = 'xml_deadlock_report';如果某帐套突然增大很多,可通过报表“按排在前面的表的磁盘使用情况”,查看具体到哪张表突然增大,造成磁盘的突然增大。

按平均CPU时间排在前面的查询,按总CPU时间排在前面的查询,按平均IO次数排在前面的查询,按总IO次数排在前面的查询。通过上述四张报表,可获取到比较慢的SQL语句,并初略分析出查询慢等相关的问题。
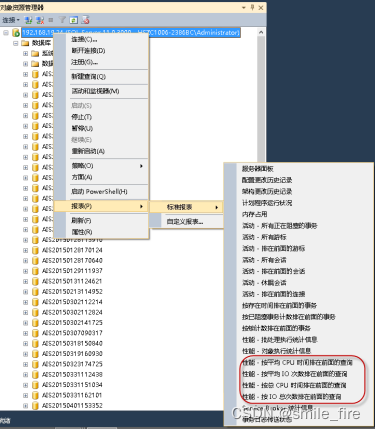
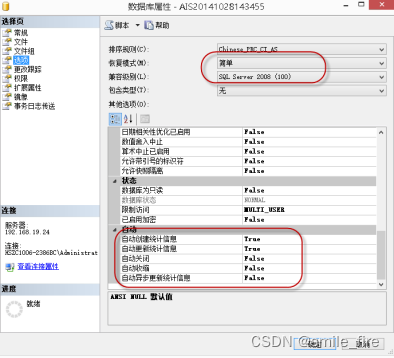
推荐:恢复模式设置为简单模式,数据库的自动更新统计信息设置为已启用,数据库自动伸缩设置为禁用,自动关闭属性设置为禁用,数据库兼容级别(SQL SERVER 2008 R2兼容级别为100,SQL SERVER 2012兼容级别为110,SQL SERVER 2014 兼容级别为120)
1)在命令行下,执行命令netstat -an >c:\netstat.txt
2)检查内容,统计1433端口(SQL服务默认端口)TIME_WAIT的数量,如果数目超过100,这时候整个系统将可能出现登录非常缓慢或者无法登陆的情况。
关键内容,数据库的IP地址,端口1433 状态TIME_WAIT
例如:
TCP 58.250.37.187:1433 61.4.185.166:5019 TIME_WAIT
TCP 58.250.37.187:1433 61.4.185.166:5020 TIME_WAIT
TCP 58.250.37.187:1433 61.4.185.166:5222 TIME_WAIT
TCP 58.250.37.187:1433 61.4.185.166:5358 TIME_WAIT
TCP 58.250.37.187:1433 61.4.185.166:5566 TIME_WAIT
TCP 58.250.37.187:1433 61.4.185.166:5584 TIME_WAIT
TCP 58.250.37.187:1433 61.4.185.166:5699 TIME_WAIT
TCP 58.250.37.187:1433 61.4.185.166:6007 TIME_WAIT
TCP 58.250.37.187:1433 61.4.185.166:6097 TIME_WAIT
TCP 58.250.37.187:1433 61.4.185.166:6155 TIME_WAIT
TCP 58.250.37.187:1433 61.4.185.166:6255 TIME_WAIT
3)约束:检查需要在数据库服务器上执行;
4)分析结果:数据库服务器基于1433端口的连接状态为TIME_WAIT的连接数为100个(统计出来的数量),请检查网络或者代码中有没打开数据连接没有关闭的情况。如果服务器通过外网可以直接访问,可能服务器被攻击,建议将服务器迁移到内网。















 2182
2182











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









