







这里分享一下在学习reques的时候做的简单整理。以http://httpbin.org/这个简单的网址为例。
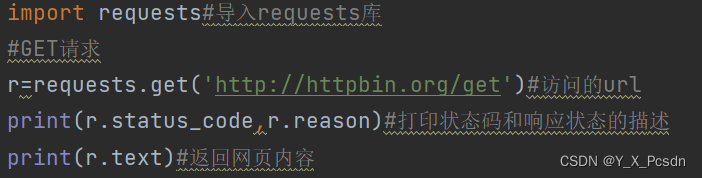
这个是最简单的请求,响应结果如下,200就是状态码,ok是状态码的描述,其中会用到r.status_code等参数,更多可通过网页查询。j
带参数的GET请求

结果:
![]()
如代码图中所示,我们get请求传上去的params数据显示在了args中。
POST请求

结果:
![]() 用post请求的时候我们穿的参数会自动放在form表单中。
用post请求的时候我们穿的参数会自动放在form表单中。
自定义header请求
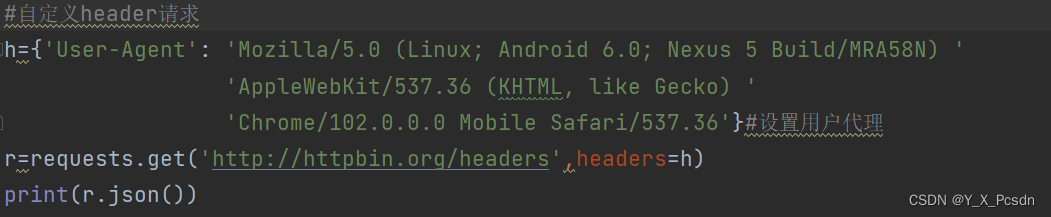
结果:
![]() 这个主要就是设置用户代理(User Agent),很简单,在网页中右击检查,这里就不细说了,可以百度哦!
这个主要就是设置用户代理(User Agent),很简单,在网页中右击检查,这里就不细说了,可以百度哦!
带cookies的请求

结果: ![]()
这里我们查看了cookies,cookie机制和下面将到的session机制的作用是一样的,都是用来网站的保持登录,在我们访问一些网站时,比如:豆瓣网。在这些网站都需要用户登录,用户登录就会有账号和密码,网站的cookie就会记录下来,避免用户每次登录都要输入信息。
Basic-auth认证请求

结果:
![]()
简单来说就是携带账户和密码进行认证请求,但安全性不高,不建议使用。
主动抛出状态码异常

结果


上面代码中输入了404的状态码,就会报出如图中的详细错误,HTTPError: 404 Client Error: NOT FOUND,在我们写代码爬取信息,请求网站的时候,经常会出现状态码的错误,这是我们调用.raise_for_status()就可以检测出详细错误。
使用request.session对象请求
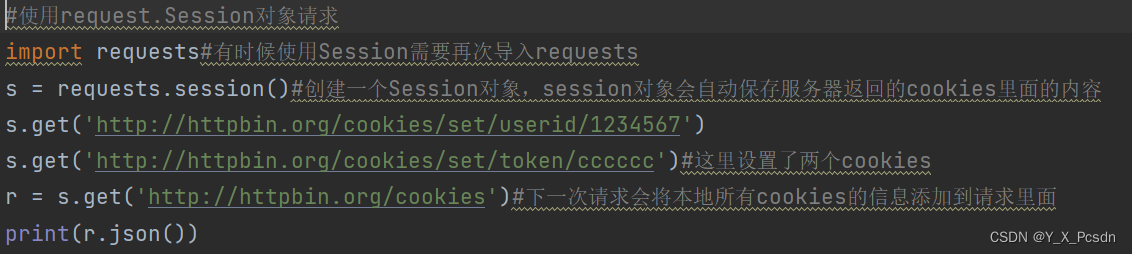
结果:
 session 机制就是将服务器返回的cookies的内容放到session对象中,并在下一次请求时将这些内容放到这次请求的头信息中。和cookies的区别是cookie不可以跨请求,session可以跨请求。cookies是将用户信息放在浏览器端,而session是放在服务器端,在访问不同浏览器是,cookies只能用不同浏览器里面的cookies里的内容,将cookies放到session对象中就可以实现跨浏览器,也就是跨域请求。详细信息或者不懂可以私信小编。
session 机制就是将服务器返回的cookies的内容放到session对象中,并在下一次请求时将这些内容放到这次请求的头信息中。和cookies的区别是cookie不可以跨请求,session可以跨请求。cookies是将用户信息放在浏览器端,而session是放在服务器端,在访问不同浏览器是,cookies只能用不同浏览器里面的cookies里的内容,将cookies放到session对象中就可以实现跨浏览器,也就是跨域请求。详细信息或者不懂可以私信小编。
使用timeout

结果:
 这个就不用多说了,就是设置网页响应时间,超过这个时间就报错,时间以秒为单位。
这个就不用多说了,就是设置网页响应时间,超过这个时间就报错,时间以秒为单位。
今天就分享到这里,有问题的可以私信我,如果文中有解释错误的地方欢迎大佬指点。加油!

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









