







 本文介绍了神经网络中的向前和向后传播过程,解释了如何通过这些步骤计算损失并利用反向传播更新权重以减小损失。同时,还讨论了几种常用的优化算法。
本文介绍了神经网络中的向前和向后传播过程,解释了如何通过这些步骤计算损失并利用反向传播更新权重以减小损失。同时,还讨论了几种常用的优化算法。
向前和向后传播
前后传播是Net的重要组成,如下图所示:

向前Forward
通过给定的参数计算每层的值,就像函数一样top=f(bottom)。

上图表示数据通过内积层输出,再由softmax给出损失。
向后Backward
向后是计算loss的梯度,每层梯度通过自动微分来计算整个模型梯度,即反向传播。
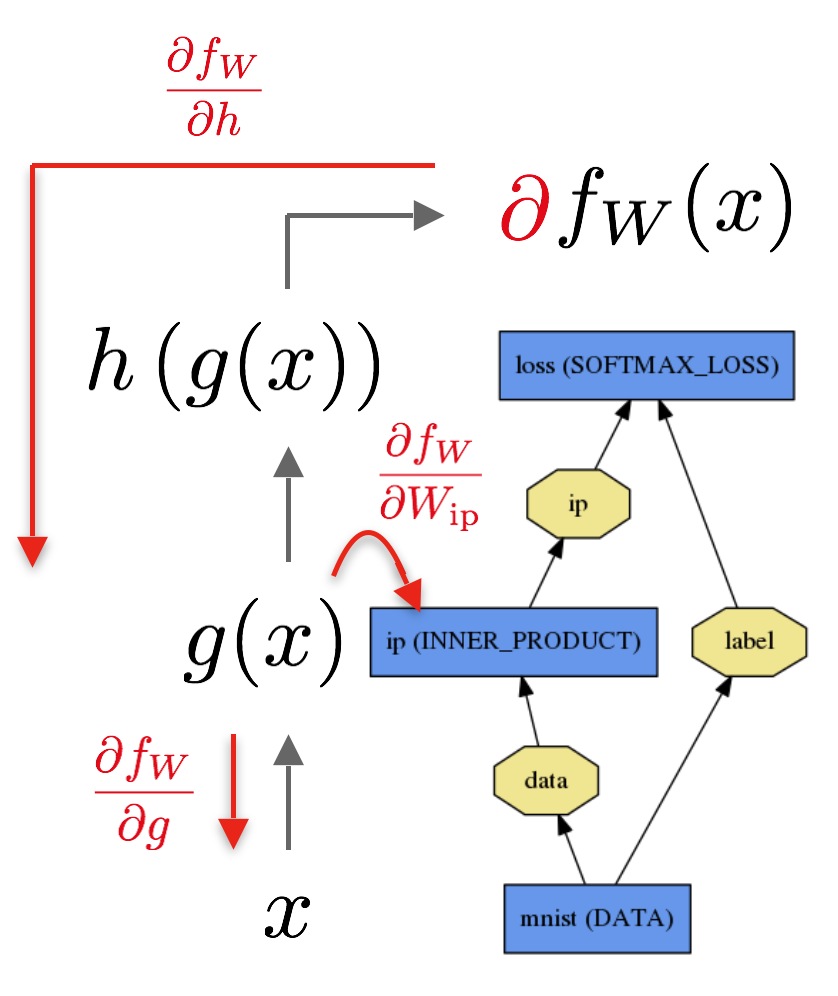
从这个图上可以看出,由loss开始,通过链式法则,不断求出结果对各层的导数。
Net::Forward()和Net::Backward()是针对网络,Layer::Forward()和Layer::Backward()是针对每一层。同时也可以设置CPU、GPU模式。
过程大概是:solver调用forward计算输出和loss,再生成梯度,并尝试更新权重减小loss。
损失Loss
Loss
使loss变小,是学习中的一个目标。如上所说,loss是由forward计算而出。
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "pred"
bottom: "label"
top: "loss"
}这一段就是上面流程图最后一层loss的表达。
Loss weights
一般的loss只是最后一层才有,其他层只是中间计算,不过每层都可以通过增加loss_weight: <float>到该层生成的每个顶(top)层中。对于后缀有loss的层都隐含着loss_weight: 1(对第一个top,其他的loss_weight: 0)。因此上面代码也等价于在最后加上loss_weight: 1。
然而任何能反向传播的层都可以赋予非零loss_weight,最终的loss由网络上各层loss权重求得
loss := 0
for layer in layers:
for top, loss_weight in layer.tops, layer.loss_weights:
loss += loss_weight * sum(top)Solver
分类
Solver通过forward和backward形成参数更新,从而改善loss。包括:
- Stochastic Gradient Descent (type: “SGD”),
- AdaDelta (type: “AdaDelta”),
- Adaptive Gradient (type: “AdaGrad”),
- Adam (type: “Adam”),
- Nesterov’s Accelerated Gradient (type: “Nesterov”) and
- RMSprop (type: “RMSProp”)
方法
对于数据集
D
,优化目标是使整个
L(W)=1|D|∑i|D|fW(X(i))+λr(W)
其中 fW(X(i)) 是对于数据 X(i) 输入的损失, r(W) 是加权 λ 的权重 W 正则项。通常用于学习的数据量
模型向前计算 fW ,向后返回梯度 ∇fW 。参数的更新 ΔW 由solver从 ∇fW 得到,正则化梯度每种方法得到的不同。
具体每种solver, 网上讲的很多,这里就不讲了。

















 2192
2192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









