







序
在家没事本来想弄一下pyqt,做一些python下的界面,但是eric装了半天没成功……于是改做爬虫(:3[__]
还好网上教程多,参考了一下,大致的框架都比较简单,难的在于针对不同的网页如何写正则表达式。不过这东西写多了应该就掌握方法了。从网上找了一段代码是爬糗百的,由于改版原来的表达式失效了,正好有了一个锻炼的机会。以下是代码:
代码
# -*- coding:utf-8 -*-
import urllib
import urllib2
import re
page = 1
url = 'http://www.qiushibaike.com/hot/page/' + str(page)
user_agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64)'
# 需要加上headers才能访问
headers={'User-Agent' : user_agent}
try:
request = urllib2.Request(url,headers=headers)
response = urllib2.urlopen(request)
except urllib2.URLError, e:
if hasattr(e,"code"):
print e.code
if hasattr(e,"reason"):
print e.reason
content = response.read().decode('utf-8')
# 正则表达式
target = 'div.*?="author clearfix".*?title="(.*?)".*?div.*?="content".*?<span>(.*?)</span>.*?</a>.*?<img src="(.*?)".*?</div>'
pattern = re.compile(target,re.S)
items = re.findall(pattern,content)
print "done"
num=1;
lenth=len(items);
for item in items:
# 判断是否存在图片
haveImg = re.search("pic.qiushibaike.com/system/pictures",item[2])
print str(num),'of',str(lenth)
print item[0] # 用户名
print item[1] # 内容
if haveImg:
print item[2] # 输出图片链接
num+=1;
效果
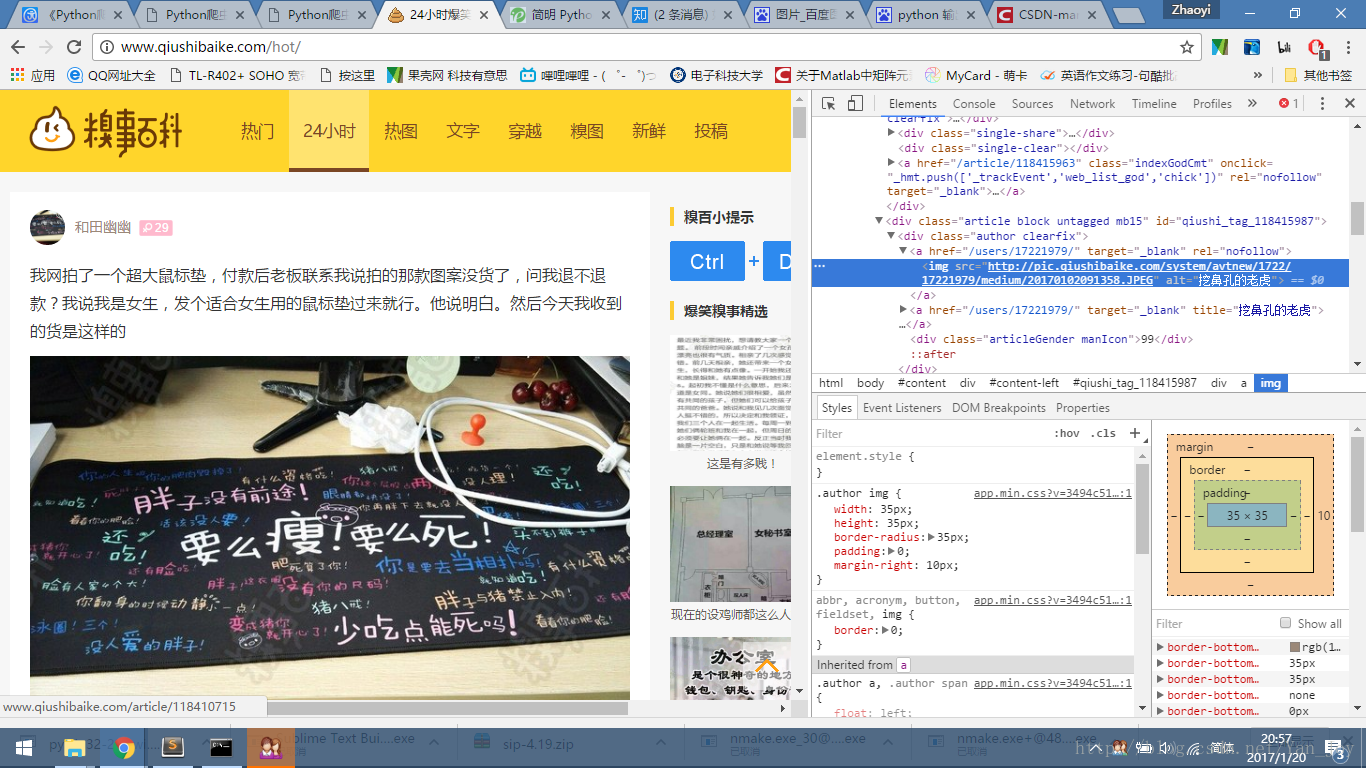
原始网页:
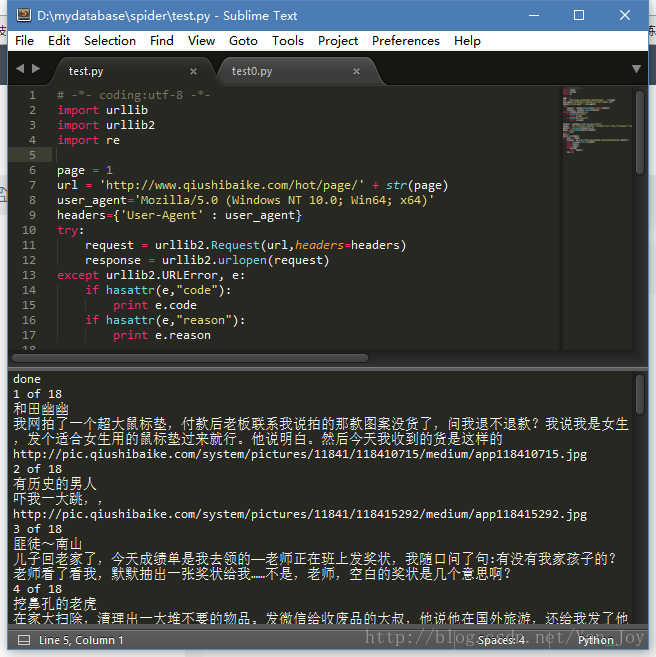
代码与结果:
总结
这算是比较简单的抓取,不用登陆就可以了,之后再学学困难的。















 1296
1296

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









