







想必大家在搜爬虫教程的时候都看到这一篇爬糗百教程
http://python.jobbole.com/81351/
这个教程很赞,但这是15年的,里面有些地方要调整,照搬的话可能会掉坑里去,比如我
先贴一个我改编后的代码
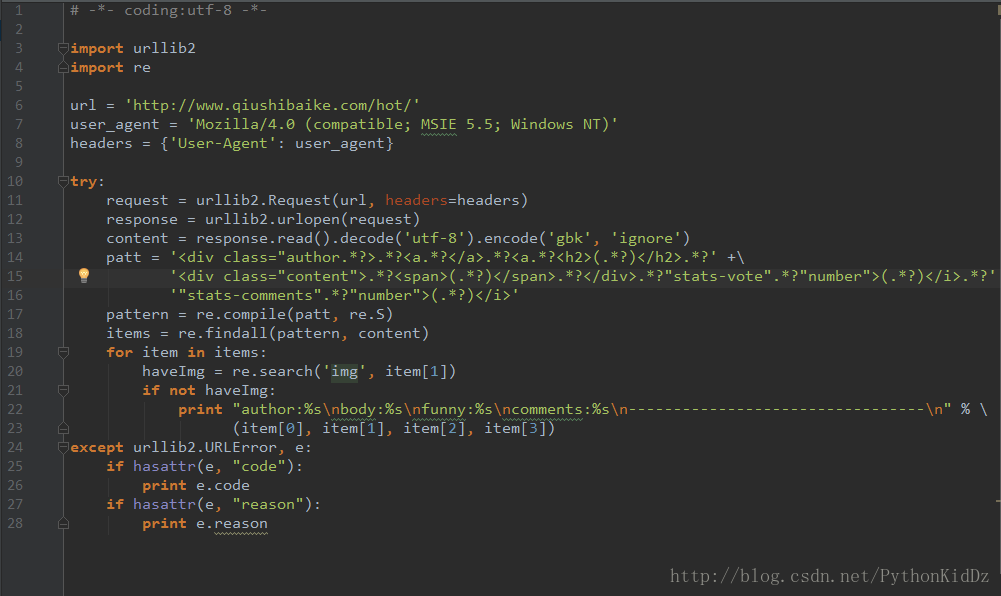
说一下坑:
- 13行中用到了decode和encode.原因是按照教程代码的话,中文会显示乱码,编码这个问题是老大难了,一直都没有细细地去研究。总之是先解码为utf-8,然后再编码成gbk,这里有个ignore参数,一定要加。因为抓取的页面中有不能编码成gbk的内容,我们就忽略掉
- 14行的正则表达式匹配模式,这个要自己去学正则表达式,重新匹配。原教程匹配的内容跟他想要的差距甚大。我这里是抓取了作者,内容,好笑值,评论数这四项,并进行了格式化优雅显示
下面是将代码做成类
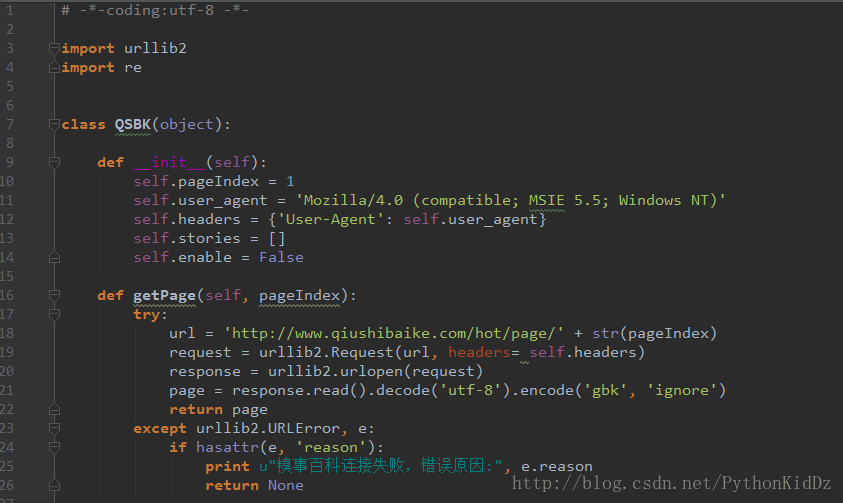
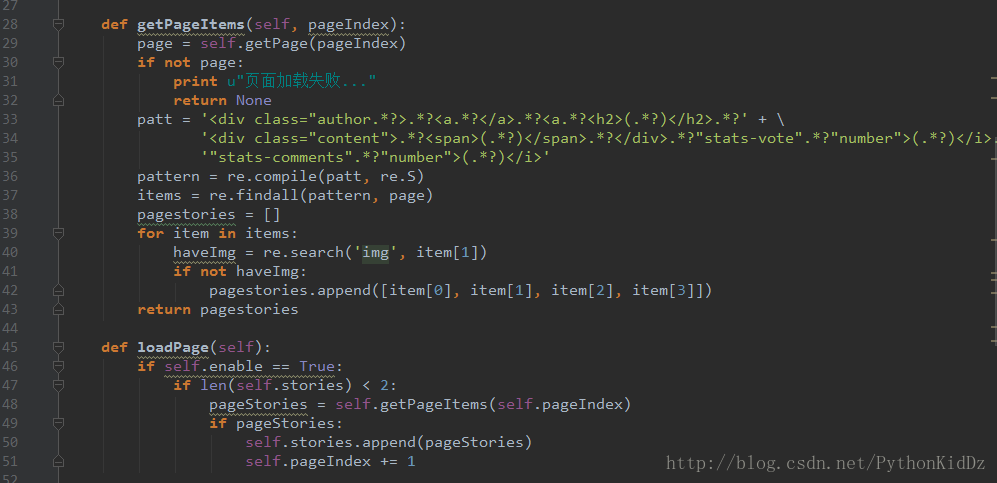
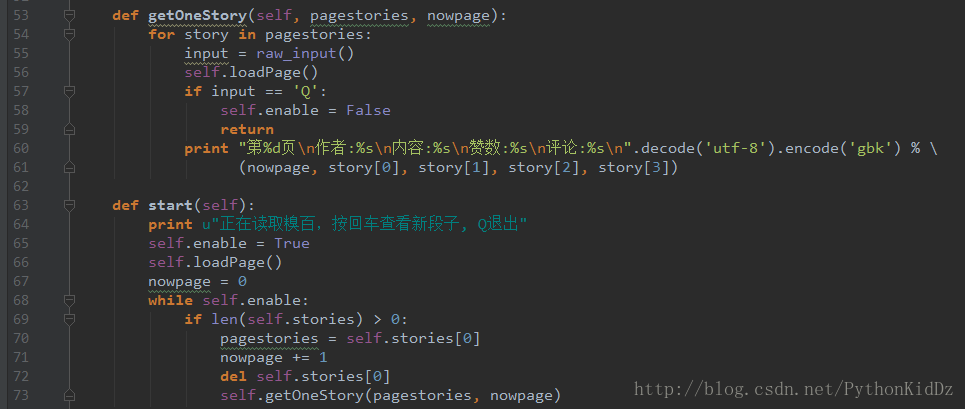
然后运行代码
qiubai = QSBK()
qiubai.start()
就行了,效果图如下

注意,一开始我以为是1页1个段子,看到好多第1页觉得哪里出问题了。后来才醒悟,1页有好多段子,不只一个(衰)















 1814
1814

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









