







1、栈的定义
栈是一种有次序的数据项集合,在栈中,数据项的加入和移除都仅发生在同一端, 这一端叫栈“顶top”,另一端叫栈“底base”
2、栈的性质
- 后进先出LIFO Last in First out:距离栈底越近的数据项,留在栈中的时间就越长,而最新加入栈的数据项会被最先移除。
- 反转次序:数据进栈和出栈的次序正好相反
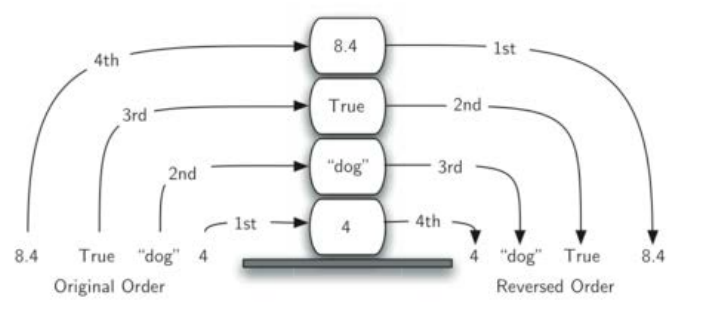
3.栈的工作流程
抽象数据类型“栈”是一个有次序的数据集,每个数据项仅从“栈顶”一端加入到数据集中、从数据集中移除,栈具有后进先出LIFO的特性

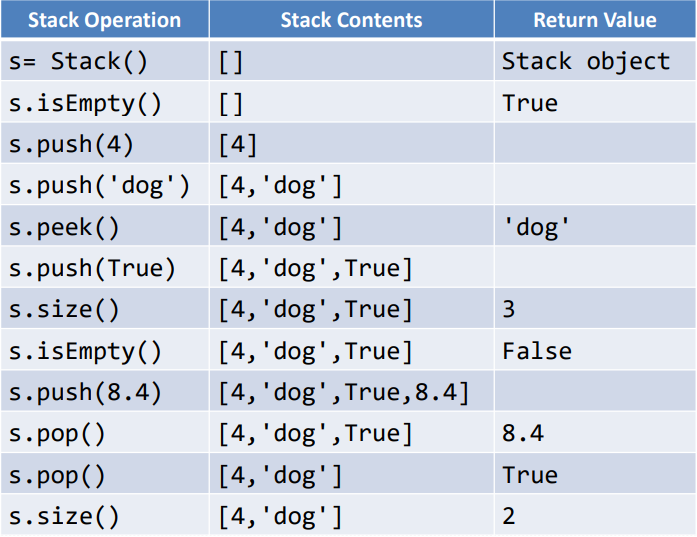
4.栈的各种操作
- Stack():创建一个空栈,不包含任何数据项
- push(item):将item加入栈顶,无返回值
- pop():将栈顶数据项移除,并返回,栈被修改
- peek():“窥视”栈顶数据项,返回栈顶的数据项但不移除,栈不被修改
- isEmpty():返回栈是否为空栈
- size():返回栈中有多少个数据
例如
5.Python实现栈
将栈定义为python中的类,用列表实现栈
class Stack:
def __init__(self):
Stack.items = []
def push(self, item):
return self.items.append(item)
def pop(self):
return self.items.pop()
def peek(self):
return self.items[len(self.items) - 1]
def isEmpty(self):
return self.items == []
def size(self):
return len(self.items)
S = Stack()
print(S.size())
print(S.isEmpty())
S.push(1)
S.push(2)
S.push(3)
print(S.items)
print(S.size())
print(S.isEmpty())
S.pop()
print(S.items)
print(S.peek())
print(S.size())
print(S.isEmpty())
通常在考试中,我们不需要从0写一个栈。直接定义一个栈就用就行了。
如
S = Stack()
S.push(item)
S.pop()
S.peek()
S.size()
S.isEmpty()
6.栈的应用
6.1简单括号匹配
括号的使用必须平衡,即左右(开闭)括号数量相同。
括号匹配识别算法:
1.遍历一个只包含括号的序列
2.遇到左括号,入栈
3.遇到右括号,判断栈是否为空,栈不空时,表示匹配到了左括号,出栈。栈空时,表示右括号多了,判断匹配失败。
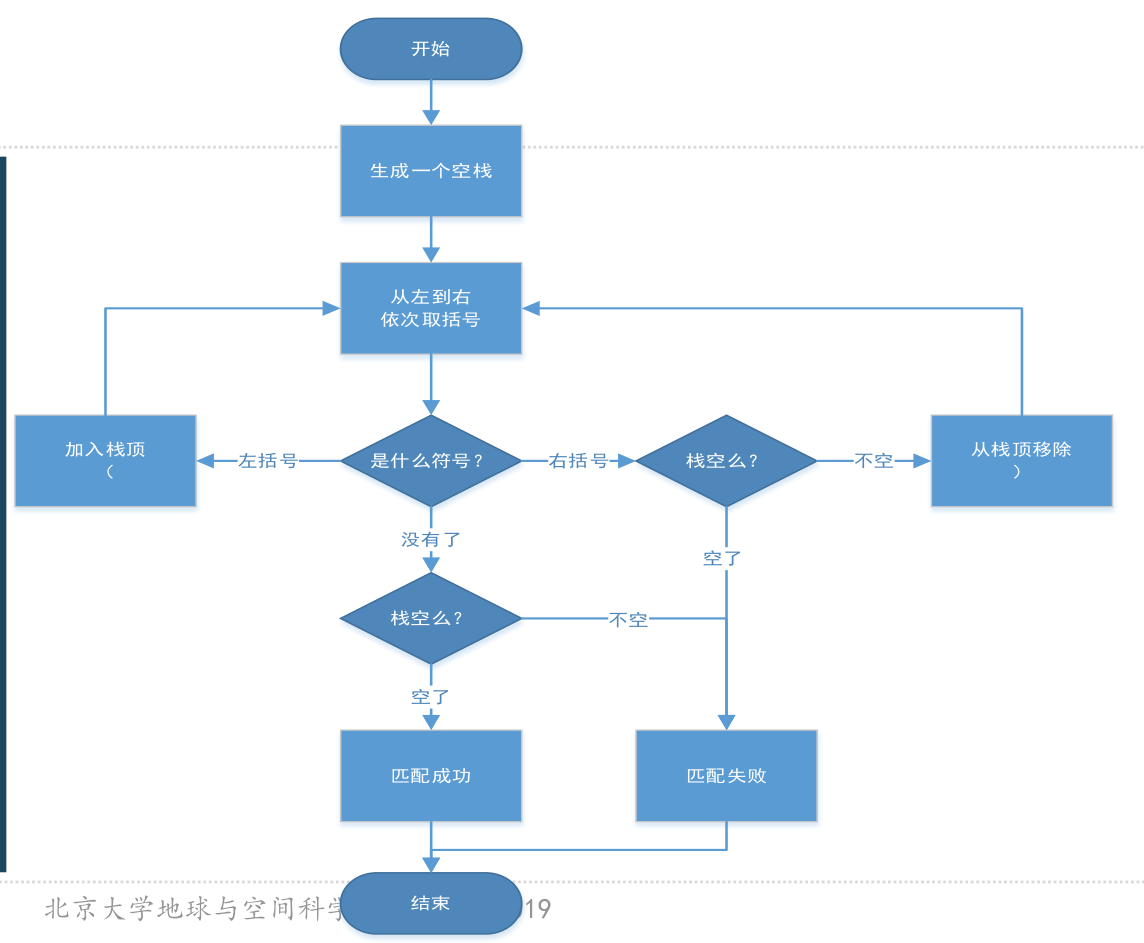
简而言之,左括号先入栈,碰到后面的右括号时,前面的左括号出栈。当栈为空且遍历结束表示匹配成功,其他情况匹配失败。
def parChecking(string):
s = Stack()
result = True
for i in range(len(string)):
if string[i] == "(":
s.push("(")
else:
if s.isEmpty() == True: # 这表示右括号数量多了,匹配失败
result = False
else:
s.pop()
if s.isEmpty() == False: # 遍历结束,如果左括号多,栈非空,匹配失败
result = False
return result
print(parChecking("()"))
print(parChecking("((())"))
解法1:通用的括号匹配算法还包括了中括号和花括号,因此我们还需要加上他们的匹配判断。如果括号类型不匹配就判断为错。
def match(left, right):
lefts = "([{"
rights = ")]}"
return lefts.index(left) == rights.index(right)
def parChecking(string):
s = Stack()
result = True
for i in range(len(string)):
if string[i] in "([{":
s.push(string[i])
else:
if s.isEmpty() == True: # 这表示右括号数量多了,匹配失败
result = False
else:
top = s.pop()
if not match(top, string[i]):
result = False
if s.isEmpty() == False: # 遍历结束,如果左括号多,栈非空,匹配失败
result = False
return result
print(parChecking("[{()}]"))
print(parChecking("{)"))
解法2:分情况讨论
即(碰到)时出栈,由于括号的具有先后顺序,即{ [ ( , 所以当 [ 碰到 ] 时,(都已经出栈了,直接判断 [ 是否碰到了 ] 就行了, 对{}也是相同的道理。
def par_check_advance(string):
stack = []
for char in list(string):
if char == "(":
stack.append(char)
if char == ")":
if not stack or stack[-1] != "(": # 右括号)在栈里没有找到(,或栈已经空了
return False
else:
stack.pop()
if char == "[":
stack.append(char)
if char == "]":
if not stack or stack[-1] != "[": # 右括号]在栈里没有找到[,或栈已经空了
return False
else:
stack.pop()
if char == "{":
stack.append(char)
if char == "}":
if not stack or stack[-1] != "{": # 右括号{在栈里没有找到},或栈已经空了
return False
else:
stack.pop()
if stack:
return False
else:
return True
print(par_check_advance("{{{[()]}}}"))
print(par_check_advance("{{{[())]}}}"))
6.2 表达式转换
我们平时用的都是中缀表达式,如 A + B。 + 就是运算符。 中缀表达式就是运算符在数字之间,前缀表达式时运算符在数字前面,后缀表达式是运算符在数字后面。

再来看中缀表达式“(A+B)×C”,按照转换的规则,前缀表达式是“×+ABC”,而后缀表达式是“AB+C×”,中缀表达式转换为前缀表达式或者后缀表达式后,括号就没了,更利于计算机计算。
更多的例子
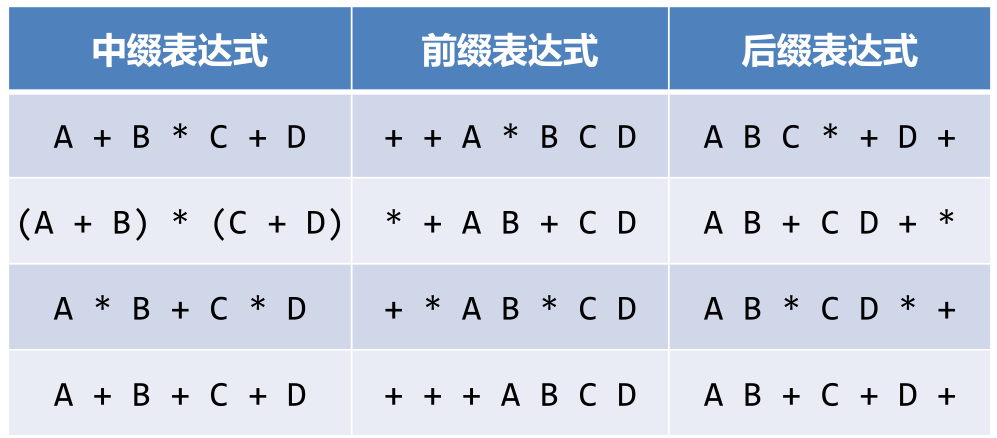
6.2.1中缀表达式转后缀和前缀的方法:
首先引入全括号形式的中缀表达式,后续要用到这个形式。
全括号形式就是把表达式能括的括号全写上。
比如 A + B × C 的全括号形式就是 (A + (B × C)),这种表达式的形式显式表达了计算次序,我们注意到每一对括号,都包含了一组完整的操作符和操作数。
无论表达式多复杂,需要转换成前缀或者后缀,只需要两个步骤:
1.将中缀表达式转换为全括号形式
2.将所有的操作符移动到子表达式所在的左括号(前缀)或者右括号(后缀)处,替代之,再删除所有的括号

6.2.1.1 中缀转后缀
看子表达式 (B × C) 的右括号,如果把操作符×移到右括号的位置,替代它,再删去,左括号,得到 BC×,这个正好把子表达式转换为后缀形式
进一步再把更多的操作符移动到相应的右括号处,替代之,再删去左括号,那么整个表达式就完成了到后缀表达式的转换

6.2.1.1 中缀转前缀
同样的,如果我们把操作符移动到左括号的位置替代之,然后删掉所有的右括号,也就得到了前缀表达式

6.2.3 通用的中缀转后缀算法
中缀表达式 A + B * C,其对应的后缀表达式是 ABC * +
- 操作数ABC的顺序没有改变。
- 操作符的出现顺序,在后缀表达式中反转了。
- 由于 * 的优先级比 + 高,所以后缀表达式中操作符的出现顺序与运算次序一致。
在中缀表达式转换为后缀形式的处理过程中,操作符比操作数要晚输出。因为在后缀表达式中,都是先写两个操作数再写他们的运算符号。
所以在扫描到对应的第二个操作数之前,需要把操作符先保存起来。
这种反转特性,使得我们考虑用栈来保存暂时未处理的操作符。
对于 (A + B) × C 这个式子来说,它的后缀形式是 AB + C ×
这里+的输出比要早,主要是因为括号使得+的优先级提升,高于括号之外的 ×。
回顾刚刚所讲的内容,中缀转后缀就是把全括号形式的中缀表达式的右括号换成操作符。
所以遇到左括号,要标记下,其后出现的操作符优先级提升了,一旦扫描到对应的右括号,就可以马上输出这个操作符。
总之,在从左到右扫描逐个字符扫描中缀表达式的过程中,采用一个栈来暂存未处理的操作符。
这样,栈顶的操作符就是最近暂存进去的,当遇到一个新的操作符,就需要跟栈顶的操作符比较下优先级,再行处理。
算法流程:
- 创建空栈opstack用于暂存操作符,空表postfixList用于保存后缀表达式
- 将中缀表达式转换为token列表
- 从左到右扫描中缀表达式token列表
如果单词是操作数,则直接添加到后缀表达式列表的末尾
如果单词是左括号“(”,则压入opstack栈顶
如果单词是右括号“)”,则反复弹出opstack栈顶操作符,加入到输出列表末尾,直到碰到左括号
如果单词是操作符“*/±”,则压入opstack栈顶
•但在压入之前,要比较其与栈顶操作符的优先级
•如果栈顶的高于或等于它,就要反复弹出栈顶操作符,加入到输出列表末尾
•直到栈顶的操作符优先级低于它 - 中缀表达式列表扫描结束后 ,把opstack栈中的所有剩余操作符依次弹出,添加到输出列表末尾
- 把输出列表再用join方法合并成后缀表达式字符串,算法结束。
例如

def infixToPostfix(infixexpr):
prec = {}
prec["*"] = 3
prec["/"] = 3
prec["+"] = 2
prec["-"] = 2
prec["("] = 1 # 到此为止是在标记各操作符的优先级
tokenList = infixexpr.split() # 将中缀表达式的各token分割为列表
opStack = Stack() # 用于暂存操作符
postfixList = () # 用于保存输出结果
for token in tokenList: # 遍历整个表达式
if token in "ABCDEFGHIJKLMNOPQRSTUVWXYZ" or token in "123456789":
postfixList.append(token) # 遇到操作符时直接输出操作符
elif token == "(":
opStack.push("token")
elif token == ")":
topToken = opStack.pop()
while topToken != "(":
postfixList.append(topToken)
topToken = opStack.pop()
else:
while (not opStack.isEmpty()) and \
(prec[opStack.peek()] >= prec[token]):
postfixList.append(opStack.pop())
opStack.push(token)
while not opStack.isEmpty():
postfixList.append(opStack.pop())
return "".join(postfixList)
print(infixToPostfix("(A+B)*C"))
6.2.4 后缀表达式求值
扫描后缀表达式,操作符在操作数后面,所以暂存操作数。在碰到操作符的时候,再将暂存的两个操作数进行实际的计算。仍然是栈的特性:操作符只作用于离它最近的两个操作数。
例如
“4 5 6 * +”,我们先扫描到4、5两个操作数,还不知道对这两个操作数能做什么计算,需要继续扫描后面的符号才能知道,继续扫描,又碰到操作数6,还是不能知道如何计算,继续暂存入栈。直到“*”,现在知道是栈顶两个操作数5、6做乘法。
弹出两个操作数,计算得到结果30。注意:先弹出的是右操作数后弹出的是左操作数,这个对于-/很重要!
为了继续后续的计算,需要把这个中间结果30压入栈顶。
继续扫描后面的符号
当所有操作符都处理完毕,栈中只留下1个操作数,就是表达式的值


算法流程重点:
- 创建空栈operandStack用于暂存操作数
- 将后缀表达式用split方法解析为token的列表
- 从左到右扫描单词列表
- 如果单词是一个操作数,将单词转换为整数int,压入operandStack栈顶
- 如果单词是一个操作符(*/±),就开始求值,从栈顶弹出2个操作数,先弹出的是右操作数,后弹出的是左操作数,计算后将值重新压入栈顶
- 单词列表扫描结束后,表达式的值就在栈顶
- 弹出栈顶的值,返回。
方法一:使用栈的数据结构,并写一个运算函数
class Stack:
def __init__(self):
Stack.items = []
def push(self, item):
return self.items.append(item)
def pop(self):
return self.items.pop()
def peek(self):
return self.items[len(self.items) - 1]
def isEmpty(self):
return self.items == []
def size(self):
return len(self.items)
def doMath(op, op1, op2):
if op == "*":
return op1 * op2
elif op == "/":
return op1 / op2
elif op == "+":
return op1 + op2
else:
return op1 - op2
def postfixEval(postfixexpr):
operandStack = Stack()
tokenList = postfixexpr.split()
for token in tokenList:
if token in "0123456789":
operandStack.push(int(token))
else:
operand2 = operandStack.pop()
operand1 = operandStack.pop()
result = doMath(token, operand1, operand2)
operandStack.push(result)
return operandStack.pop()
print(postfixEval("456*+"))
方法二:用列表作为栈,用eval()方法计算两个操作数的运算结果
"""
给一个后缀表达式,求出这个表达式的值
输入: 4 5 6 * +
输出: 34
"""
def calculate_postfix_exp(postfix_exp):
stack = [] # 用于存储操作数
postfix_exp = postfix_exp.split() # 把字符串转成列表方便遍历
temp = [] # 用于计算出栈的两个数的运算结果
for i in postfix_exp:
if i in "123456789": # 如果是数字,直接存到栈中
stack.append(i)
else: # 如果是操作符,将栈中的两个数先进行运算
num2 = stack.pop() # 栈顶的这个是后进去的数,如果是减法或除法,他就是被减或被除的
num1 = stack.pop()
temp.append(num1)
temp.append(i)
temp.append(num2) # 此时temp变为[num1, i, num2]
result = eval(" ".join(temp))
# 先将temp合并为一个字符串才能使用eval()方法,计算这个式子的结果,注意计算结果是int类型,要改成str
temp = []
stack.append(str(result))
return stack[0]
print(calculate_postfix_exp("4 5 6 * +"))
print(calculate_postfix_exp("1 2 -"))
print(calculate_postfix_exp("2 4 -"))
print(calculate_postfix_exp("8 9 5 * -"))
6.3 十进制转换为二进制算法
例如 十进制的 233 对应的二进制是 11101001
23
3
10
=
2
∗
1
0
2
+
3
∗
1
0
1
+
2
∗
1
0
0
233_{10} = 2 * 10^2 + 3 * 10^1 + 2 * 10^0
23310=2∗102+3∗101+2∗100
11101001
2
=
1
∗
2
7
+
1
∗
2
6
+
1
∗
2
5
+
0
∗
2
4
+
1
∗
2
3
+
0
∗
2
2
+
0
∗
2
1
+
1
∗
2
0
{11101001}_{2} = 1 * 2 ^ 7 + 1 * 2 ^ 6 + 1 * 2 ^ 5 + 0 * 2 ^ 4 + 1 * 2 ^ 3 + 0 * 2 ^ 2 + 0 * 2 ^ 1 + 1 * 2 ^ 0
111010012=1∗27+1∗26+1∗25+0∗24+1∗23+0∗22+0∗21+1∗20
十进制转二进制的方法是除以二求余数,具体来说,就是把整数每次除以二,依次求出的余数,就是从低位到高位的二进制的组成部分。

算法最后的输出是从高位到低位的,所以使用栈来反转次序。循环地将每次求出的余数存入到栈中。循环结束后,出栈,保存到一个新的列表中,将新的列表中的元素合并成字符串,就是我们想要的答案。
def decimal_to_binary(num):
num = int(num)
stack = [] # 用于出入栈的空栈
temp = [] # 出栈后,按顺序保存的数字
divided_result = 1 # 最后的整数的商
while divided_result != 0: # 循环结束条件,最后一个除法的商等于1
divided_result = num // 2 # 每次的商,如果是十进制转其他的N进制,把2改成N即可
mod_result = num % 2 # 每次的余数,如果是十进制转其他的N进制,把2改成N即可
stack.append(mod_result) # 将余数存入到栈中
num = divided_result # 对每次的商再次进行除法运算
for i in range(len(stack)):
temp.append(str(stack.pop())) # 反转顺序,注意join方法只能连接str字符
# return temp
join_symbol = "" # 合并列表中元素的连接符
return join_symbol.join(temp)
print(decimal_to_binary(233))
print(decimal_to_binary(35))
十进制转其他进制也是一样的做法,要注意16进制用16个字符表达,即A=10, B=11, C=12, D=13, E=14, F=15
23 3 10 = E ∗ 16 + 9 ∗ 1 = E 9 16 233_{10} = E * 16 + 9 *1 = E9_{16} 23310=E∗16+9∗1=E916
def decimal_to_N(num, n):
num = int(num)
stack = []
temp = []
divided_num = 1
while divided_num != 0:
divided_num = num // n
mod_result = num % n
num = divided_num
if mod_result == 10: # 转为16进制时,需要将大于9的数字翻译成字母
mod_result = "A"
if mod_result == 11:
mod_result = "B"
if mod_result == 12:
mod_result = "C"
if mod_result == 13:
mod_result = "D"
if mod_result == 14:
mod_result = "E"
if mod_result == 15:
mod_result = "F"
stack.append(mod_result)
for i in range(len(stack)):
temp.append(str(stack.pop()))
join_symbol = ""
return join_symbol.join(temp)
print(decimal_to_N(233, 16))
print(decimal_to_N(233, 2))
参考文献
本文的知识来源于B站视频 【慕课+课堂实录】数据结构与算法Python版-北京大学-陈斌-字幕校对-【完结!】,是对陈斌老师课程的复习总结














 469
469











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









