







1.概念
树一种基本的“非线性”数据结构。
相关术语:
- 节点Node:组成树的基本部分。每个节点具有名称,或“键值”,节点还可以保存额外数据项,数据项根据不同的应用而变。
- 边Edge:边是组成树的另一个基本部分。每条边恰好连接两个节点,表示节点之间具有关联,边具有出入方向。每个节点(除根节点)恰有一条来自另一节点的入边。每个节点可以有多条连到其它节点的出边。
- 根Root:树种唯一一个没有入边的节点。
- 路径path:边依次连接的节点的有序列表
- 子节点Children:入边均来自于同一个节点的若干节点,称为这个节点的子节点
- 父节点Parent:一个节点是其所有出边所连接节点的父节点
- 兄弟节点Sibling:具有同一个父节点的节点之间成为兄弟节点
- 子树SubTree:一个节点和其所有子孙节点,以及相关边的集合
- 叶节点Leaf:没有子节点的节点。
- 层级Level:从根节点开始到达一个节点的路径,所包含的边的数量,称为这个节点的层级。根节点的层级为0。
- 高度:树中所有节点的最大层级称为树的高度
- 完全二叉树:叶节点只出现在最底层和次底层, 最底层的叶节点集中在树左侧。
2.树的数据结构表示方法:
2.1 嵌套列表法
用嵌套的列表表示树。
[根节点root, 左子树left, 右子树right]
例如
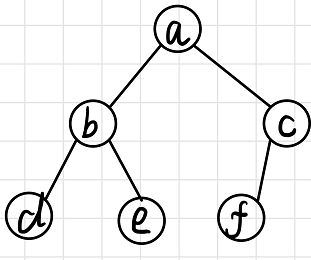
[a, [b, [d, [], []], [e, [], [] ]], [c, [f, [], []], []]]
2.2 嵌套列表法树插入新节点、返回根节点、返回子树的操作代码实现
def binary_tree(root):
# 创建只有根节点的二叉树
return [root, [], []]
def insert_left(root, new_branch):
# 将新节点插入到树的根节点的左节点,作为其左子树的根节点
# 注:不是将新节点直接插入到左子树的最后一个节点上
temp = root.pop(1)
if len(temp) > 1:
root.insert(1, [new_branch, temp, []])
else:
root.insert(1, [new_branch, [], []])
def insert_right(root, new_branch):
# 将新节点插入到树的根节点的右节点,作为其右子树的根节点
# 注:不是将新节点直接插入到右子树的最后一个节点上
temp = root.pop(2)
if len(temp) > 1:
root.insert(2, [new_branch, [], temp])
else:
root.insert(2, [new_branch, [], []])
def get_root_val(root):
return root[0]
def set_root_val(root, new_val):
root[0] = new_val
def get_left_child(root):
return root[1]
def get_right_child(root):
return root[2]
r = binary_tree(3)
insert_left(r, 4)
insert_left(r, 5)
insert_right(r, 6)
insert_right(r, 7)
l = get_left_child(r)
print(l)
set_root_val(l, 9)
print(r)
insert_left(l, 11)
print(r)
print(get_right_child(get_right_child(r)))
[5, [4, [], []], []]
[3, [9, [4, [], []], []], [7, [], [6, [], []]]]
[3, [9, [11, [4, [], []], []], []], [7, [], [6, [], []]]]
[6, [], []]
2.2 链表实现:节点链接法
每个节点保存根节点的数据项,以及指向左右子树的链接
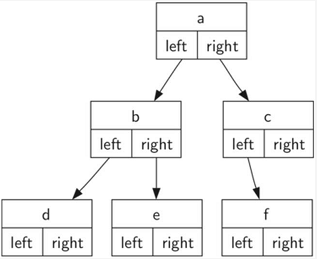
class BinaryTree:
def __init__(self, root_obj):
self.key = root_obj
self.left_child = None
self.right_child = None
def insert_left(self, new_node):
if self.left_child is None:
self.left_child = BinaryTree(new_node)
# 和之前的操作是一样的,意思是插入到根节点的左节点上
# 原来的左子树插入到现在这个左子树的左子树上
else:
t = BinaryTree(new_node)
t.left_child = self.left_child
self.left_child = t
def insert_right(self, new_node):
if self.right_child is None:
self.right_child = BinaryTree(new_node)
else:
t = BinaryTree(new_node)
t.right_child = self.right_child
self.right_child = t
def set_root_val(self, obj):
self.key = obj
def get_root_val(self):
return self.key
def get_left_child(self):
return self.left_child
def get_right_child(self):
return self.right_child
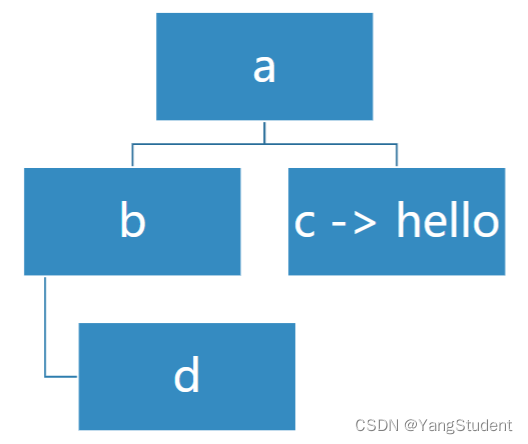
r = BinaryTree('a')
r.insert_left('b')
r.insert_right('c')
r.get_right_child().set_root_val('hello')
r.get_left_child().insert_right('d')
print(r.get_root_val())
print(r.get_right_child().get_root_val())
print(r.get_left_child().get_root_val())
print(r.get_left_child().get_right_child().get_root_val())
a
hello
b
d
上述操作画成图就是:
3. 树的应用:解析树
树可以应用到自然语言处理(机器翻译、语义理解)中,用来分析句子的语法成分,进而可以对句子的各成分进行处理。
语法分析树包含:
主谓宾,定状补
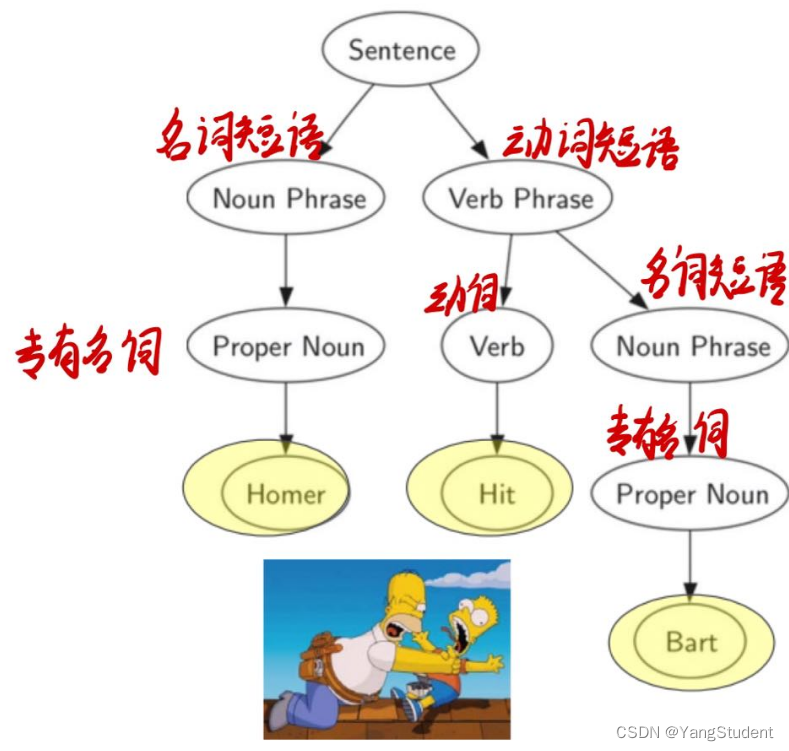
语法树还可以用于程序设计语言的编译当中:
词法、语法检查
从语法树中生成目标代码
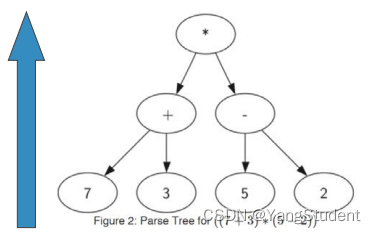
4. 树的应用:表达式解析
树结构可以表示表达式:
- 叶节点:保存操作数
- 内部节点:保存操作符
例如 ((7 + 3) * (5 - 2))的树结构的写法如下:
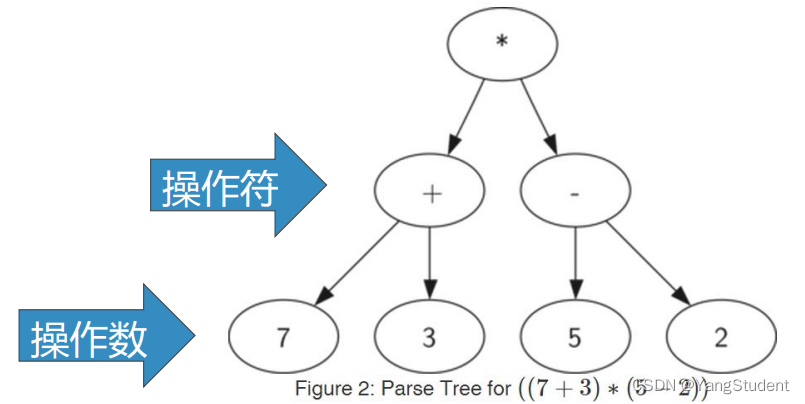
由于括号的存在,需要计算*的话,就必须先计
算7+3和5-2。
表达式层次决定计算的优先级。
越底层的表达式,优先级越高。
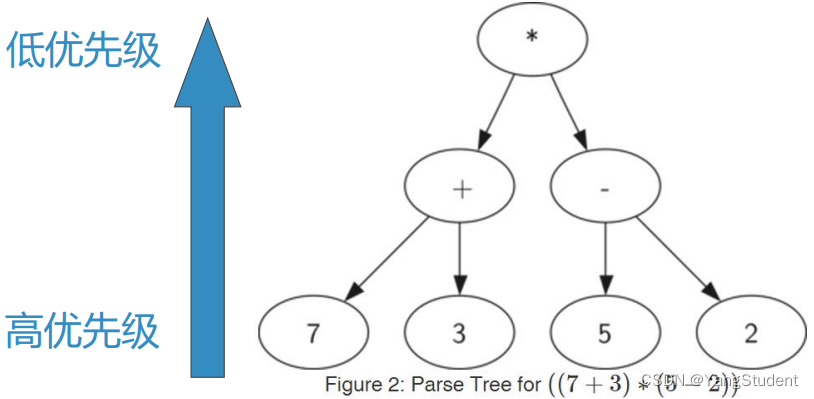
树中每个子树都表示一个子表达式。
将子树替换为子表达式值的节点,即可实现求值。
例如把左子树的 7 + 3 表示成根节点的左叶子节点10的图示如下。
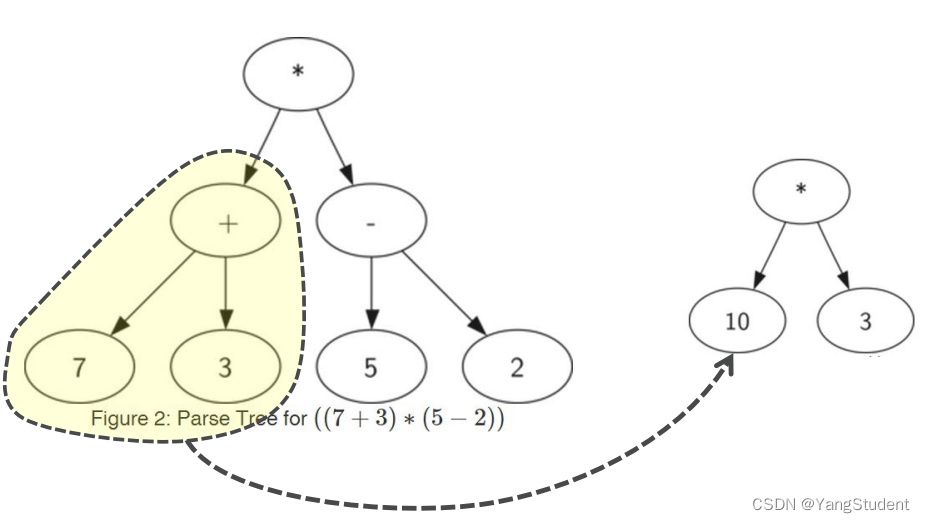
下面,我们用树结构来做如下尝试:
- 从全括号表达式构建表达式解析树
- 利用表达式解析树对表达式求值
- 从表达式解析树恢复原表达式的字符串形式
实例:
- 将全括号表达式分解为符号Token列表
符号包括:
- 括号“( )”
- 操作符“+ - * /”
- 操作数“0~9”这几类
左括号就是表达式的开始,而右括号是表达式的
结束。
如对于全括号表达式:(3 + (4 * 5)),将其分解为token表:
[‘(’, ‘3’, ‘+’, ‘(’, ‘4’, ‘*’, ‘5’, ‘)’, ‘)’]
- 创建表示解析树过程
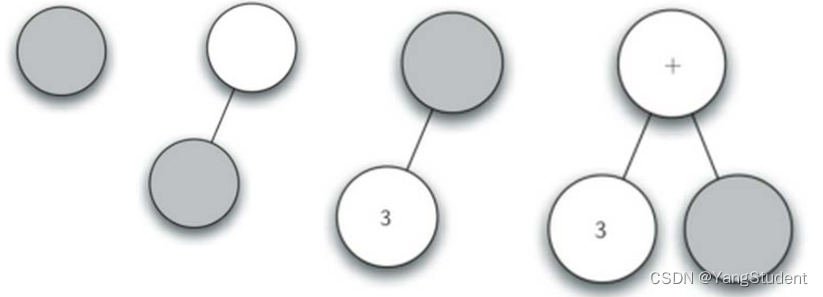
- 创建空树,当前节点为根节点
- 读入’(',创建了左子节点,当前节点下降
- 读入’3’,当前节点设置为3,上升到父节点
- 读入’+',当前节点设置为+,创建右子节点,当前节点下降
- 读入’(',创建左子节点,当前节点下降
- 读入’4’,当前节点设置为4,上升到父节点
- 读入’*‘,当前节点设置为’*',创建右子节点,当前节点下降
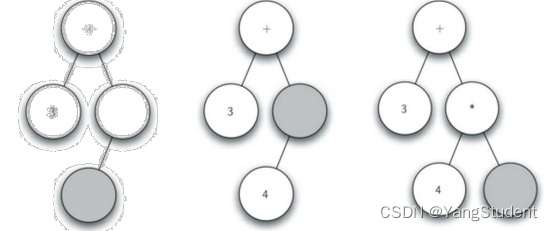
- 读入’5’,当前节点设置为5,上升到父节点
- 读入’)',上升到父节点
- 读入’)',再上升到父节点
建立表达式解析树的顺序就是:
从左到右扫描全括号表达式的每个字符token,依据规则建立解析树
- 如果当前字符是"(":为当前节点添加一个新节点作为其左子节点,当前节点下降为这个新节点
- 如果当前字符是操作符"+, -, /, *":将当前节点的值设为此符号,为当前节点添加一个新节点作为其右子节点,当前节点下降为这个新节点
- 如果当前字符是操作数:将当前节点的值设为此数,当前节点上升到父节点
- 如果字符单词是")" :则当前节点上升到父节点
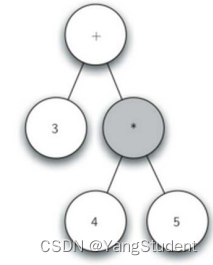
对全括号表达式 (3 + (4 * 5)),建立表达式解析树的流程就是:
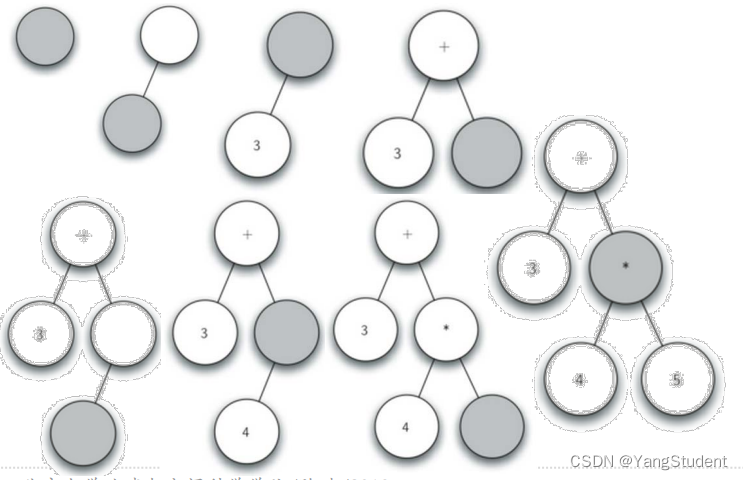
从图示过程中我们看到,创建树过程中关键的是对当前节点的跟踪:
- 创建左右子树可调用insert_left/right
- 当前节点设置值,可以调用set_root_val
- 下降到左右子树可调用get_left/right_child
- 但是,上升到父节点,这个没有方法支持!
我们可以用一个栈来记录跟踪父节点。
当前节点下降时,将下降前的节点push入栈。
当前节点需要上升到父节点时,上升到pop出栈的节点即可!
# 定义一个节点链接法实现的树
class Tree:
def __init__(self, root_obj):
self.key = root_obj
self.left_child = None
self.right_child = None
def insert_left(self, new_node):
if self.left_child is None:
self.left_child = Tree(new_node)
else:
temp_tree = Tree(new_node)
temp_tree.left_child = self.left_child
self.left_child = temp_tree
def insert_right(self, new_node):
if self.right_child is None:
self.right_child = Tree(new_node)
else:
temp_tree = Tree(new_node)
temp_tree.right_child = self.right_child
self.right_child = temp_tree
def get_root_val(self):
return self.key
def set_root_val(self, new_node):
self.key = new_node
def get_left_child(self):
return self.left_child
def get_right_child(self):
return self.right_child
# 建构表达解析式树
def build_parse_tree(expression):
expression_list = expression.split()
# 先把表达解析式拆分到列表当中
father_node_stack = []
# 用栈存储父节点,便于做上下节点的操作
parse_tree = Tree('')
father_node_stack.append(parse_tree)
cur_node = parse_tree
for token in expression_list:
if token == '(':
cur_node.insert_left('')
father_node_stack.append(cur_node)
cur_node = cur_node.get_left_child()
# 当前节点下降到左子节点
if token in ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']:
cur_node.set_root_val(token)
parent = father_node_stack.pop()
# 当前节点上升到父节点
cur_node = parent
if token in ['+', '-', '*', '/']:
cur_node.set_root_val(token)
cur_node.insert_right('')
father_node_stack.append(cur_node)
cur_node = cur_node.get_right_child()
# 当前节点下降到右子节点
if token == ')':
if father_node_stack is not None:
cur_node = father_node_stack.pop()
return parse_tree
ex_tree = build_parse_tree('( 3 * ( 4 + 5 ) )')
print(ex_tree.get_root_val())
print(ex_tree.get_left_child().get_root_val())
print(ex_tree.get_right_child().get_root_val())
print(ex_tree.get_right_child().get_left_child().get_root_val())
print(ex_tree.get_right_child().get_right_child().get_root_val())
5. 用表达式解析树求值
表达式解析树是用来求全括号表达式的值的。二叉树是递归数据结构,可用递归算法处理。
求值递归函数evaluate:
由前述对子表达式的描述,可从树的底层子树开始,逐步向上层求值,最终得到整个表达式的值。
求值函数evaluate的递归三要素:
- 基本结束条件:叶节点是最简单的子树,没有左右子节点,其根节点的数据项即为子表达式树的值
- 缩小规模:将表达式树分为左子树、右子树,即为缩小规模
- 调用自身:分别调用evaluate计算左子树和右子树的值,然后将左右子树的值依根节点的操作符进行计算,从而得到表达式的值
import operator
def evaluate(parseTree):
operators = {'+': operator.add,
'-': operator.sub,
'*': operator.mul,
'/': operator.truediv}
# 缩小规模
leftC = parseTree.get_left_child() # 范围缩小到左子树,先求左子树的小表达式的值
rightC = parseTree.get_right_child() # 范围缩小到右子树,再求右子树的小表达式的值
if leftC and rightC:
fn = operators[parseTree.get_root_val()] # 每棵子树的根节点,保存着操作符
return fn(evaluate(leftC), evaluate(rightC)) # 递归调用
else:
return int(parseTree.get_root_val()) # 基本结束条件,到叶节点就直接返回值了
the_result = evaluate(ex_tree)
print("The result of the expression: ", the_result)
整个构建表达式解析树和求解的过程如下:
# 定义一个节点链接法实现的树
class Tree:
def __init__(self, root_obj):
self.key = root_obj
self.left_child = None
self.right_child = None
def insert_left(self, new_node):
if self.left_child is None:
self.left_child = Tree(new_node)
else:
temp_tree = Tree(new_node)
temp_tree.left_child = self.left_child
self.left_child = temp_tree
def insert_right(self, new_node):
if self.right_child is None:
self.right_child = Tree(new_node)
else:
temp_tree = Tree(new_node)
temp_tree.right_child = self.right_child
self.right_child = temp_tree
def get_root_val(self):
return self.key
def set_root_val(self, new_node):
self.key = new_node
def get_left_child(self):
return self.left_child
def get_right_child(self):
return self.right_child
# 建构表达解析式树
def build_parse_tree(expression):
expression_list = expression.split()
# 先把表达解析式拆分到列表当中
father_node_stack = []
# 用栈存储父节点,便于做上下节点的操作
parse_tree = Tree('')
father_node_stack.append(parse_tree)
cur_node = parse_tree
for token in expression_list:
if token == '(':
cur_node.insert_left('')
father_node_stack.append(cur_node)
cur_node = cur_node.get_left_child()
# 当前节点下降到左子节点
if token in ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']:
cur_node.set_root_val(token)
parent = father_node_stack.pop()
# 当前节点上升到父节点
cur_node = parent
if token in ['+', '-', '*', '/']:
cur_node.set_root_val(token)
cur_node.insert_right('')
father_node_stack.append(cur_node)
cur_node = cur_node.get_right_child()
# 当前节点下降到右子节点
if token == ')':
if father_node_stack is not None:
cur_node = father_node_stack.pop()
return parse_tree
ex_tree = build_parse_tree('( 3 * ( 4 + 5 ) )')
print(ex_tree.get_root_val())
print(ex_tree.get_left_child().get_root_val())
print(ex_tree.get_right_child().get_root_val())
print(ex_tree.get_right_child().get_left_child().get_root_val())
print(ex_tree.get_right_child().get_right_child().get_root_val())
import operator
def evaluate(parseTree):
operators = {'+': operator.add,
'-': operator.sub,
'*': operator.mul,
'/': operator.truediv}
# 缩小规模
leftC = parseTree.get_left_child() # 范围缩小到左子树,先求左子树的小表达式的值
rightC = parseTree.get_right_child() # 范围缩小到右子树,再求右子树的小表达式的值
if leftC and rightC:
fn = operators[parseTree.get_root_val()] # 每棵子树的根节点,保存着操作符
return fn(evaluate(leftC), evaluate(rightC)) # 递归调用
else:
return int(parseTree.get_root_val()) # 基本结束条件,到叶节点就直接返回值了
the_result = evaluate(ex_tree)
print("The result of the expression: ", the_result)
6. 树的遍历
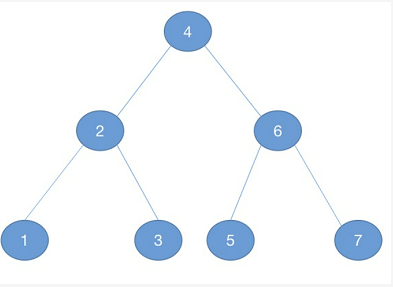
例图来源于:一文搞懂二叉树的前序遍历,中序遍历,后序遍历
6.1 前序遍历 preorder
遍历顺序:根节点 -> 左子树 -> 右子树
对上图: 4->2->1->3->6->5->7
Python代码:
def preorder(tree):
if tree:
print(tree.getRootVal())
preorder(tree.getLeftChild())
preorder(tree.getRightChild())
6.2 中序遍历 inorder
遍历顺序:左子树 -> 根节点 -> 右子树
对上图:1->2->3->4->5->6->7
Python代码:
def inorder(tree):
if tree != None:
inorder(tree.getLeftChild())
print(tree.getRootVal())
inorder(tree.getRightChild())
6.3 后序遍历 postorder
遍历顺序:左子树 -> 右子树 -> 根节点
对上图:1->3->2->5->7->6->4
Python代码:
def postorder(tree):
if tree != None:
postorder(tree.getLeftChild())
postorder(tree.getRightChild())
print(tree.getRootVal())
6.4 前序遍历还有可以写在建树的代码里
def preorder(self):
print(self.key)
if self.left_child:
self.left_child.preorder()
if self.right_child:
self.right_child.preorder()
6.5 后序遍历:表达式求值
回顾第5节的内容,表达式解析树求值,也是一个后序遍历的过程。
import operator
def post_order_evaluate(tree):
opers = {
"+": operator.add,
"-": operator.sub,
"*": operator.mul,
"/": operator.truediv
}
res1 = None
res2 = None
if tree:
res1 = post_order_evaluate(tree.left_child)
res2 = post_order_evaluate(tree.right_child)
if res1 and res2:
return opers[tree.get_root_val()](res1, res2)
else:
return tree.get_root_val()
6.6 中序遍历建立全括号中缀表达式
def print_exp(tree):
the_exp = ""
if tree:
if tree.get_left_child():
the_exp = '(' + print_exp(tree.get_left_child())
else:
the_exp = print_exp(tree.get_left_child())
the_exp = the_exp + str(tree.get_root_val())
if tree.get_right_child():
the_exp = the_exp + print_exp(tree.get_right_child()) + ')'
else:
the_exp = the_exp + print_exp(tree.get_right_child())
return the_exp
print(print_exp(ex_tree)) # 接在第5节的后,结果是 (3*(4+5))
7. 二叉堆Binary Heap和优先队列 Priority Queue
7.1 优先队列
前面我们学习了一种FIFO数据结构队列,队列有一种变体称为“优先队列”。
例如:银行窗口取号排队,VIP客户可以插到队首。操作系统中执行关键任务的进程或用户特别指定进程在调度队列中靠前。
优先队列的出队跟队列一样从队首出队;
但在优先队列内部,数据项的次序却是由“优先级”来确定:
- 高优先级的数据项排在队首,而低优先级的数据项则排在后面。
- 这样,优先队列的入队操作就比较复杂,需要将数据项根据其优先级尽量挤到队列前方。
7.2 二叉堆Binary Heap实现优先队列
实现优先队列的经典方案是采用二叉堆数据结构。
二叉堆能够将优先队列的入队和出队复杂度都保持在O(log n)。
二叉堆的有趣之处在于,其逻辑结构上像二叉树,却是用非嵌套的列表来实现的!
最小key排在队首的称为“最小堆min heap”,反之,最大key排在队首的是“最大堆max heap”
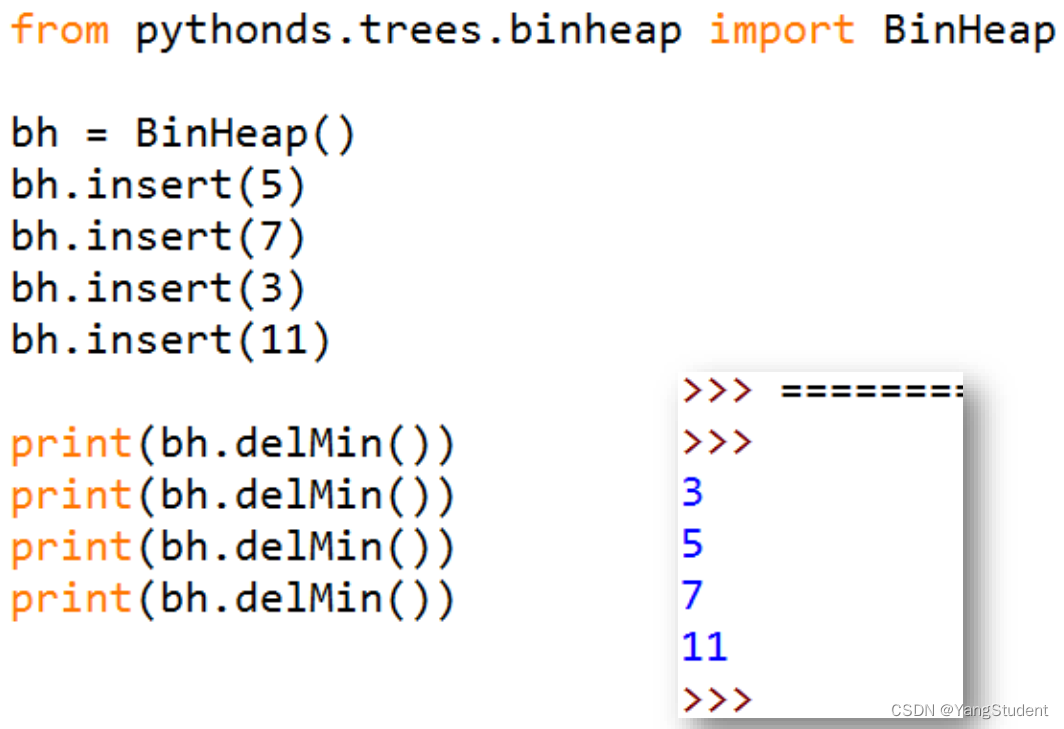
BinaryHeap数据结构的类,包含以下操作:
- BinaryHeap():创建一个空二叉堆对象;
- insert(k):将新key加入到堆中;
- findMin():返回堆中的最小项,最小项仍保留在堆中;
- delMin(): 返回堆中的最小项,同时从堆中删除;
- isEmpty():返回堆是否为空;
- size():返回堆中key的个数;
- buildHeap(list):从一个key列表创建新堆
对这个类的操作如下:
7.3 用非嵌套列表实现二叉堆
为了使堆操作能保持在对数水平上,就必须采用二叉树结构;
同样,如果要使操作始终保持在对数数量级上,就必须始终保持二叉树的“平衡”,即树根左右子树拥有相同数量的节点。
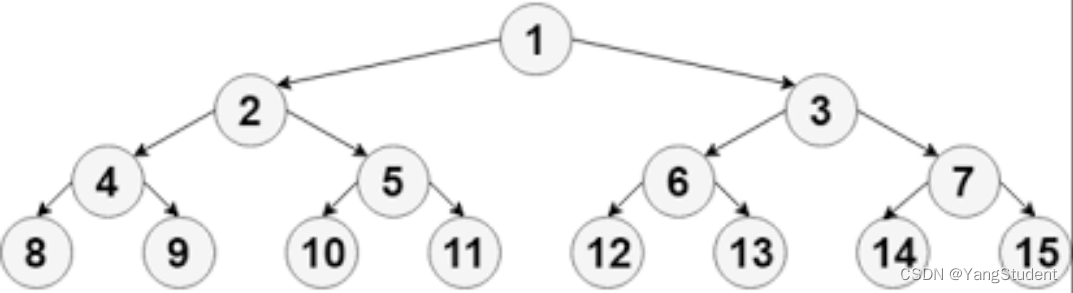
可采用“完全二叉树”的结构来近似实现“平衡”。
完全二叉树,叶节点最多只出现在最底层和次底层,而且最底层的叶节点都连续集中在最左边,每个内部节点都有两个子节点,最多可有1个节点例外(即最后一个节点,有可能时单独的一个子节点)
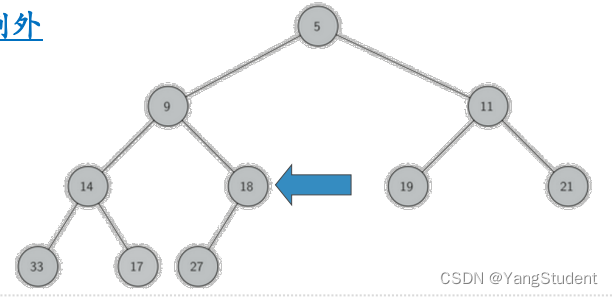
我们给上面这个图,按照从上往下,从左往右的顺序打上索引。可以看出,如果节点的下标为p,那么:
- 左子节点下标为2p
- 右子节点为2p+1
- 父节点下标为p // 2
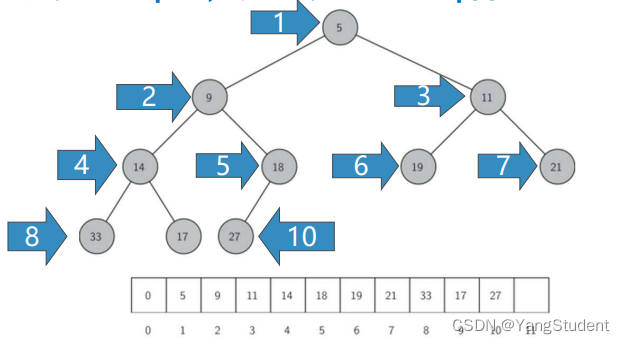
可见,完全二叉树由于其特殊性,可以用非嵌套列表,以简单的方式实现,具有很好性质。
7.4 堆排序Heap Order
堆排序应该放在排序那一章节的,但是其实现时树这一章的,所以在这里将。
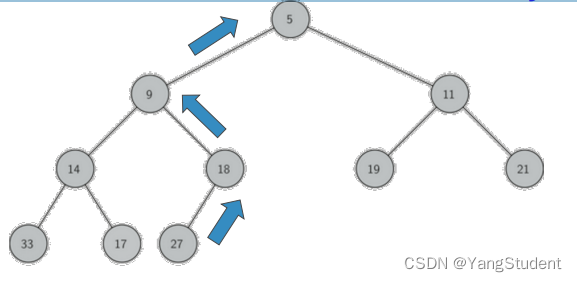
对于一个 最小堆
任何一个节点x,其父节点 p 中的 key 均小于 x 中的 key。
这样,符合“堆”性质的二叉树,其中任何一条路径,均是一个已排序数列,根节点的key最小。
4. 树的应用:二叉排序(查找)树 Binary Search Tree BST
4.1 定义
就是一颗 左子树所有节点的关键字值 < 根节点关键字值 < 右子树所有节点的关键字值 的树
所有的子树都符合这个规律
由于二叉查找树 左<根<右的特点,对二叉排序树中序遍历,就可以得到 递增序列
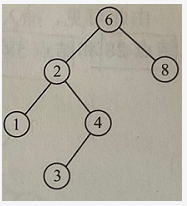
如中序遍历这个 BST得到 123468 序列
4.2 查找节点
BST的查找过程和二分法差不多:
- 目标和根节点对比,相等,查找成功
- 目标>根节点,查找右子树
- 目标<根节点,查找左子树
4.3 插入节点
BST插入节点的过程和查找的过程是一样的,
- BST为空时,直接插入
- 若关键字小于根节点就插入左子树
- 关键字小于根节点就插入右子树

就像这个图 , 分别是插入28和58,虚线是搜索插入位置的路径
4.4 删除节点
-
如果删除的是叶节点,直接删除,不影响BST的性质
-
如果删除的节点只有一颗子树(左或右),让这个子树成为删除节点的父节点的子树,代替原来的位置

-
如果删除的节点有两颗子树,让节点的直接后继(即在大小上刚好大于它的,在列表中处于他后面的那个位置的节点)代替他

4.5 构造二叉查找树
和插入节点的操作是一样的,就是依次用上面的方法插入节点
4.6 二叉树查找效率分析
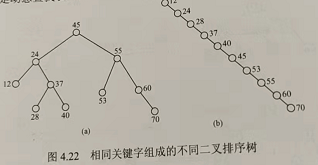
平均查找长度ASL可表示查找效率:计算方法,就是查找每个节点需要走多少步,加起来,除以总的节点的个数
对于左边的树
ASL = (1 + 2 * 2 + 3 * 4 + 4 * 3) / 10 = 2.9
对于右边的树
ASL = (1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 + 10) / 10 = 5.5
5. 树的应用:平衡二叉树 AVL树
5.1 定义
任意节点的左右子树高度差绝对值不超过1的二叉排序树叫做AVL树(平衡二叉树)
平衡因子:左右子树的高度差, AVL树的平衡因子只能是 -1, 0, 1

5.2 平衡二叉树插入节点旋转
插入新节点可能导致平衡二叉树变得不平衡,然后就需要旋转
旋转的方法这篇博客讲的很好
二叉平衡树的旋转操作
6. 树的应用:哈夫曼树和哈夫曼编码
6.1 定义
在许多实际应用中,树的节点带有权重。
带权路径长度WPL:从根节点到任意节点的路径长度(经过的边数)与该节点的权值的乘积,记为:
W
P
L
=
∑
i
=
1
n
w
i
l
i
WPL = \sum_{i = 1}^{n}w_il_i
WPL=∑i=1nwili
w
i
w_i
wi 是第i个节点的权值
l
i
l_i
li是根节点到该节点的路径长度
哈夫曼树是带权路径长度最小的二叉树,也称最优二叉树
6.2 构造哈夫曼树
每次选最小的两个节点作为子节点,他们的和作为父节点。
例如

我这个可能看不清楚,哈夫曼树以及哈夫曼编码的构造步骤
这篇文章讲的不错
这颗哈夫曼树的WPL = 7 * 1 + 5 * 2 + 2 * 3 + 4 * 3= 35
6.3 哈夫曼编码
前缀编码:没有一个编码是另一个编码的前缀,如 0,101和100是前缀编码。前缀编码不容易造成混淆,所以翻译简单。
由哈夫曼树得到的哈夫曼编码就是前缀编码,至于怎么得到的
还是这篇文章讲的更好一些哈夫曼树以及哈夫曼编码的构造步骤















 2385
2385











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









