







可以使用一个例子理解。设计一个函数输出0到n的平方,设计第一版函数:
def sum_n(n):
for i in range(n+1):
print(i**2)
运行函数,sum_n(3)得到以下结果
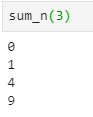
这个函数可以打印出我们需要的结果,但是函数的可复用性比较差,因为函数的返回值是None,其他程序无法使用此函数产生的结果。
如果要提高函数的复用性,则可以使用列表将结果保存,第二版函数如下:
def sum_n(n):
sum_list=[]
for i in range(n+1):
sum_list.append(i**2)
return sum_list
当n=3时,配合for循环,同样可以打印出结果
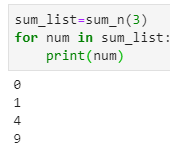
而且,这样提高了函数的可复用性,但是,当n比较大的时候,列表占用的内存比较大。如果是在jupyter中运行的话,很多时候回出现kernel dead的情况。
我们既要使得函数具有很好的复用性同事减小内存占用率,所以可以考虑使用yield。yield作用可以先简单粗暴地理解成和print()一样能够运行出结果,但是print是即时可见的,运行到print直接打印出结果,yield可以理解成先把该print的结果保存在一个迭代对象中(反正就是理解为先保存了),如果我们想要具体得到yield的结果,则需要配合for循环。 使用yield的第三版函数如下:
def sum_n(n):
for i in range(n+1):
yield i**2
当n=3时,运行结果如下
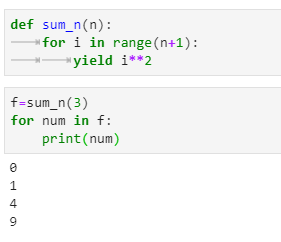
有表现形式可以看出,函数使用了yield的结果就像一个列表。我们可以使用for循环 读取这个“列表里的内容”。这里的值是迭代取的,所以占用了很少的内存。为了便于理解,我们可以把它先当成是一个“列表”。但我们要清楚,运行sum_n(3)得到的实际是一个迭代对象,并不是列表。














 6119
6119











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









