







一、目的
爬取网址:https://movie.douban.com/top250
二、参考知识
三、代码
import requests
from pyquery import PyQuery as pq
import re
# 获取网页代码
def get_page(url):
try:
header = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36'}
r = requests.get(url, headers=header)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print("出现异常")
# 解析网页获得排行榜数据
def parse_page(html):
doc = pq(html)
lis = doc.find('div#content li').items()
data = []
for li in lis:
movie_info = []
head_spans = li.find('div.hd a span').items()
for span in head_spans:
span_text = re.sub('/\xa0', "", span.text())
movie_info.append(span_text)
body_ps = li.find('div.bd p').items()
for body_p in body_ps:
body_p_text = re.sub('\xa0', "", body_p.text())
movie_info.extend(body_p_text.split('\n'))
data.append(movie_info)
return data
# 输出爬取数据
def print_data(data):
typlt = "{0:{6}<20}{1:<50}{2:{6}<50}{3:{6}<70}{4:{6}<50}{5:{6}<50}"
# typlt = "{0:{6}^20}{1:{6}^50}{2:{6}^50}{3:{6}^70}{4:{6}^50}{5:{6}^50}"
print(typlt.format("电影名", "别名", "其他名", "导演", "电影类型", "评论", chr(12288)))
for item in data:
try:
print(typlt.format(item[0], item[1], item[2], item[3], item[4], item[5], chr(12288)))
except:
pass
if __name__ == '__main__':
for start in range(0, 226, 25):
url = "https://movie.douban.com/top250"
url += "?start=" + str(start)
# 获取html页面
html = get_page(url)
# 解析html页面
data = parse_page(html)
# 输出数据
print_data(data)
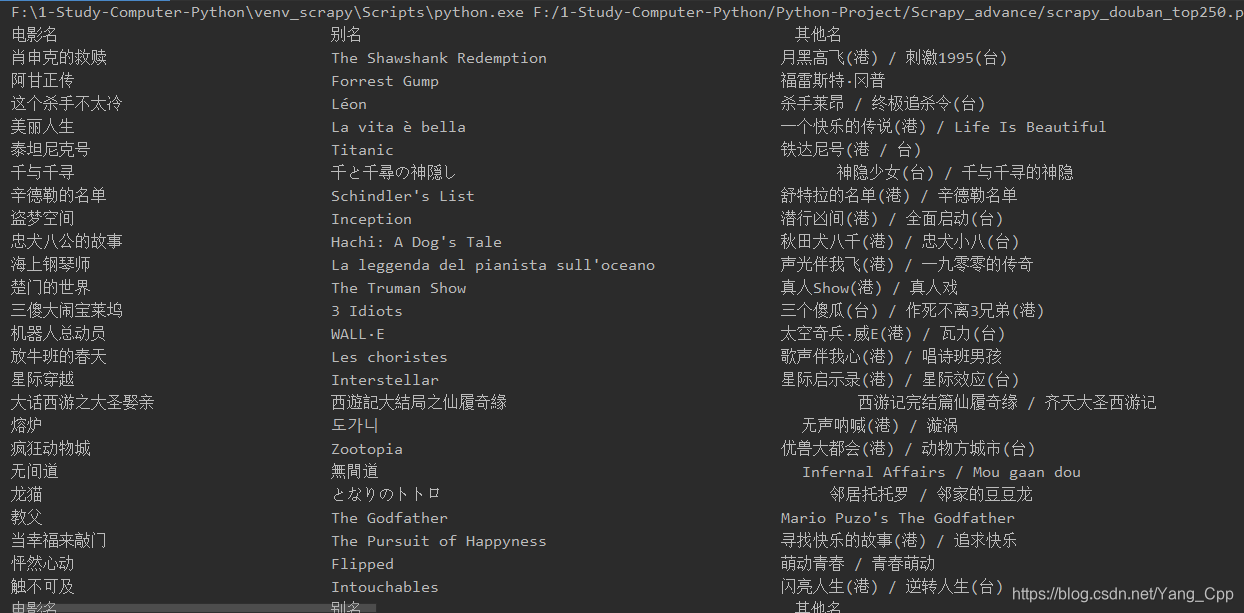
四、结果
五、主要代码分析
# 解析网页获得排行榜数据
def parse_page(html):
doc = pq(html)
lis = doc.find('div#content li').items()
data = []
for li in lis:
# 用于存储一条电影信息
movie_info = []
# 头部信息
head_spans = li.find('div.hd a span').items()
for span in head_spans:
span_text = re.sub('/\xa0', "", span.text())
movie_info.append(span_text)
# 主体信息
body_ps = li.find('div.bd p').items()
for body_p in body_ps:
body_p_text = re.sub('\xa0', "", body_p.text())
movie_info.extend(body_p_text.split('\n'))
data.append(movie_info)
return data
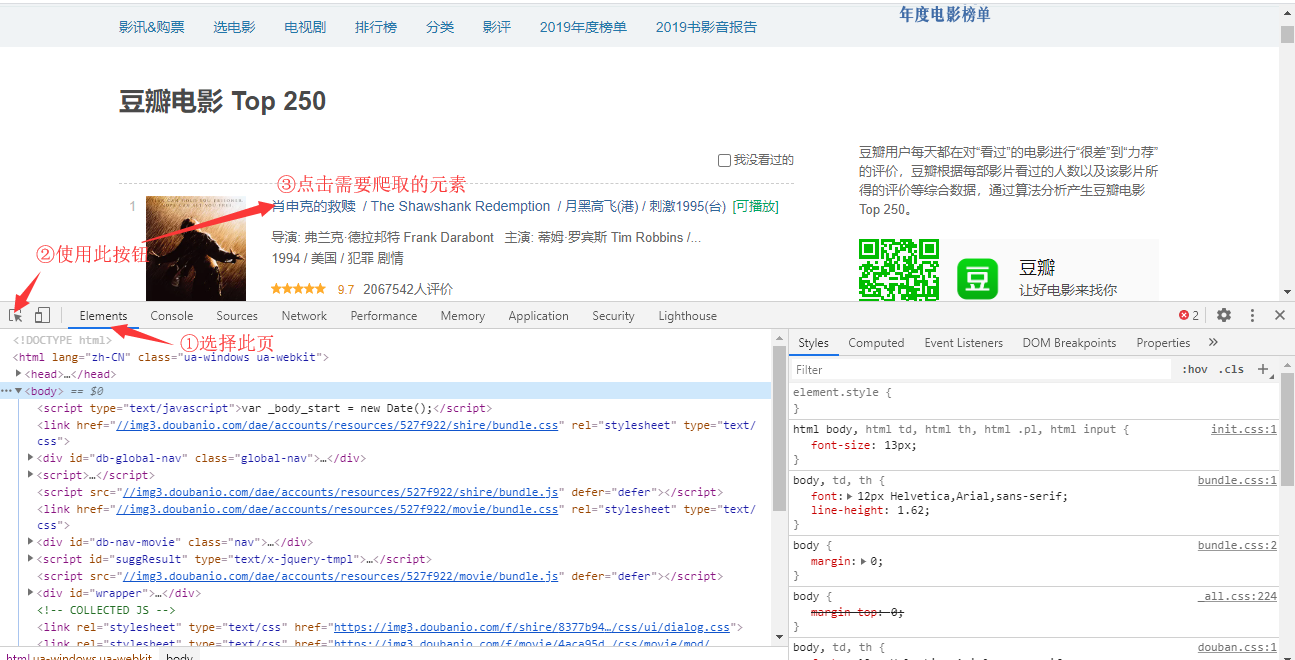
- 打开网站,按
F12键检查网页元素
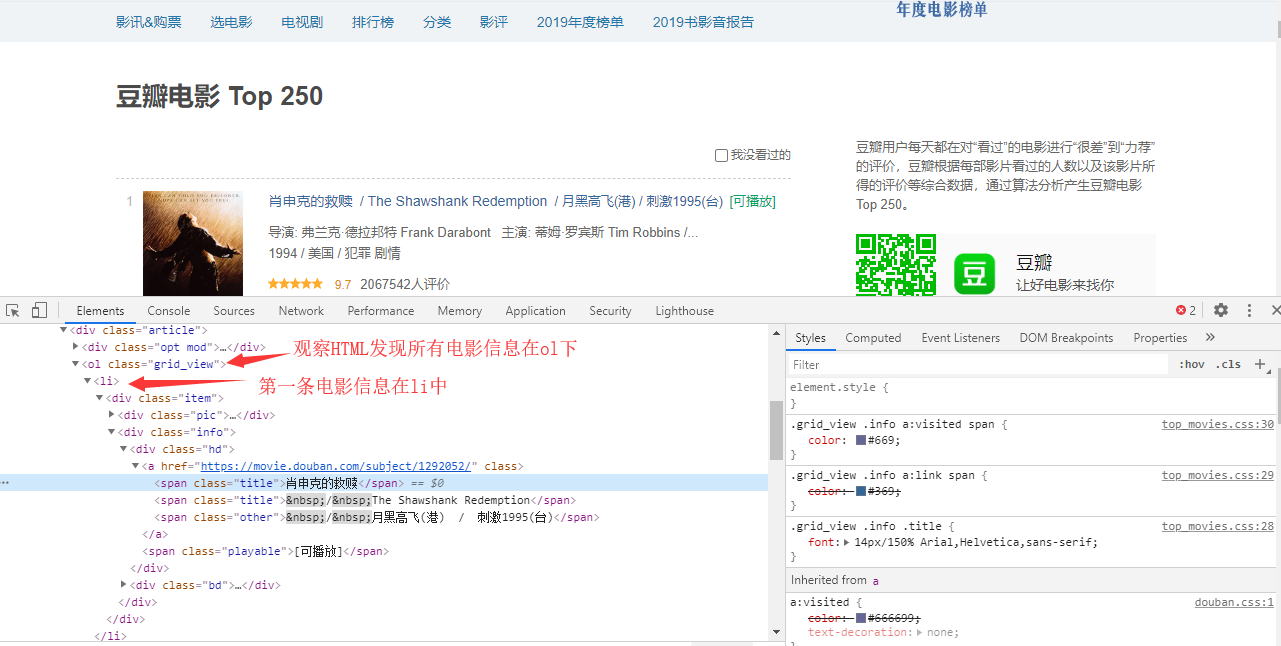
- 找到包含电影信息的标签
ol / li
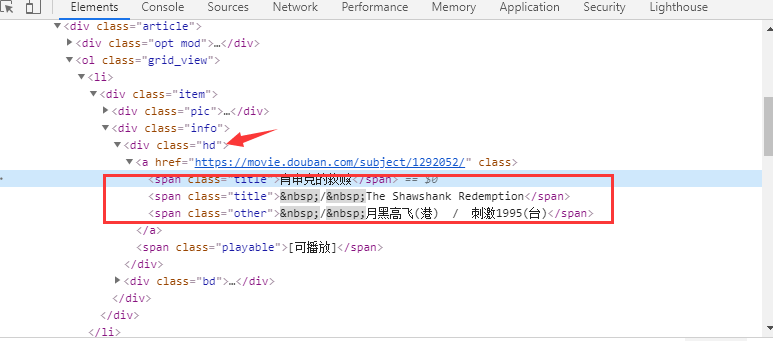
- 返回
li标签的迭代器,可对电影信息列表进行遍历lis = doc.find('div#content li').items() - 找到电影信息头部信息在
div class="hd" / span标签中
# 返回span标签的迭代器 head_spans = li.find('div.hd a span').items() # 遍历span标签,获取标签中的文本,并通过正则表达式除去特殊字符 for span in head_spans: span_text = re.sub('/\xa0', "", span.text()) movie_info.append(span_text) - 找到电影信息主体信息,主要在
div class="bd" / p标签中
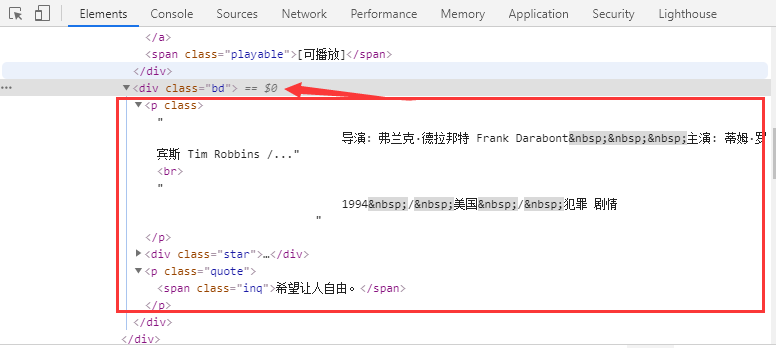
# 主体信息 # 返回p标签的迭代器 body_ps = li.find('div.bd p').items() # 遍历p标签,通过正则表达式处理掉特殊字符,并且添加进入电影信息列表中 for body_p in body_ps: body_p_text = re.sub('\xa0', "", body_p.text()) movie_info.extend(body_p_text.split('\n')) data.append(movie_info)

















 320
320

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









