






概要
nvidia课程奖项需要写一篇文章,随便记录一下,原价90U的课程可以白学还给奖励
课程
https://learn.nvidia.com/courses
课程主页中选择《开发基于提示工程的大语言模型(LLM)应用》

开始有一个视频可以看
点下面的Start可以开始notebook的实验环境

可能需要多等一会
等待环境开始后电机LAUNCH即可进入notebook环境

通关秘籍
为了拿证可以直接进入6-Assessment的61-Assessment.ipynb

要做的是识别客户的投诉来源的提示词
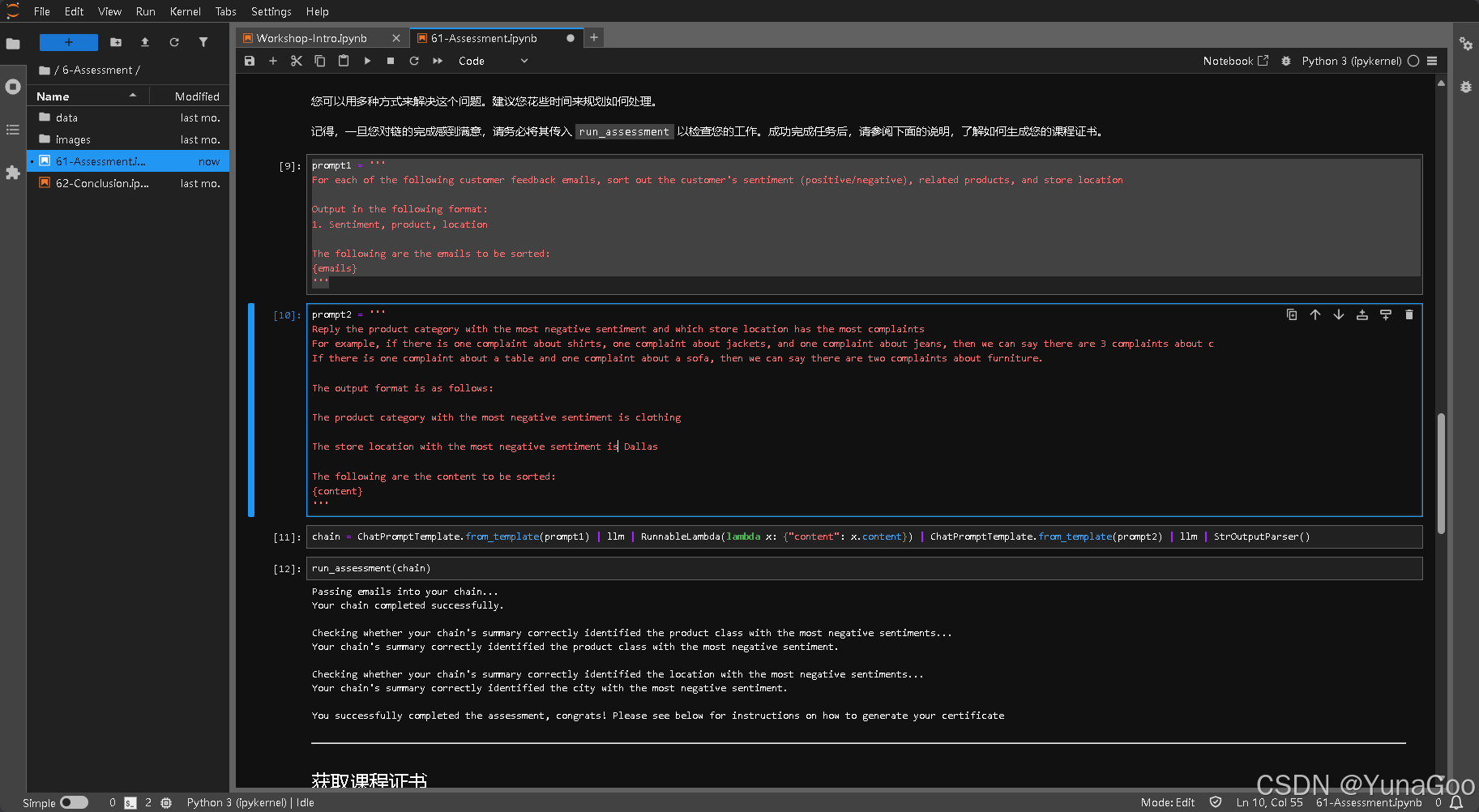
可以直接将以下内容加入notebook直接运行即可拿证。
prompt1 = '''
For each of the following customer feedback emails, sort out the customer's sentiment (positive/negative), related products, and store location
Output in the following format:
1. Sentiment, product, location
The following are the emails to be sorted:
{emails}
'''prompt2 = '''
Reply the product category with the most negative sentiment and which store location has the most complaints
For example, if there is one complaint about shirts, one complaint about jackets, and one complaint about jeans, then we can say there are 3 complaints about c
If there is one complaint about a table and one complaint about a sofa, then we can say there are two complaints about furniture.
The output format is as follows:
The product category with the most negative sentiment is clothing
The store location with the most negative sentiment is Dallas
The following are the content to be sorted:
{content}
'''chain = ChatPromptTemplate.from_template(prompt1) | llm | RunnableLambda(lambda x: {"content": x.content}) | ChatPromptTemplate.from_template(prompt2) | llm | StrOutputParser()run_assessment(chain)
Prompt详解
Prompt1
For each of the following customer feedback emails, sort out the customer's sentiment (positive/negative), related products, and store location
Output in the following format:
1. Sentiment, product, location
The following are the emails to be sorted:
{emails}
prompt2
Reply the product category with the most negative sentiment and which store location has the most complaints
For example, if there is one complaint about shirts, one complaint about jackets, and one complaint about jeans, then we can say there are 3 complaints about c
If there is one complaint about a table and one complaint about a sofa, then we can say there are two complaints about furniture.
The output format is as follows:
The product category with the most negative sentiment is clothing
The store location with the most negative sentiment is Dallas
The following are the content to be sorted:
{content}
Prompt1主要用来对原始邮件进行基础信息分类
指定输出的格式:情感,产品,位置
1. Sentiment, product, location
如
Negative, coffee maker, Seattle
Prompt2则对结构化后的数据进行统计决策
The product category with the most negative sentiment is clothing
The store location with the most negative sentiment is Dallas
-
将具体产品归类到大类(如衬衫/夹克→服装)
-
统计负面情感最多的产品类别
-
统计投诉最多的店铺位置
整体来看,Prompt1的输出会作为Prompt2的{content}输入,形成从原始数据→结构化数据→决策洞察的完整分析链条。
相当于先做数据清洗(Prompt1),再做数据分析(Prompt2)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









