








 超级会员免费看
超级会员免费看


在建模的时候,有些变量在训练集效果很好,但是在测试集和oot出现了严重衰减。如何识别出这种变量?一种方法是看同样分箱分别在训练集和测试集上IV值,如果差异过大,说明变量分布不稳定。这种方法的优点是容易计算,可以快速筛选出这种类型的变量,缺点是不能看出差异具体分布在哪。为了更清晰地判断两者分布差异,可以通过画双坐标图的形式,直观观察变量分布特征。这种方法在变量精筛的时候常常用到。本文以企业欺诈数据为例,进行代码拆分展示。
文章目录
一、绘图效果
绘图效果如下:
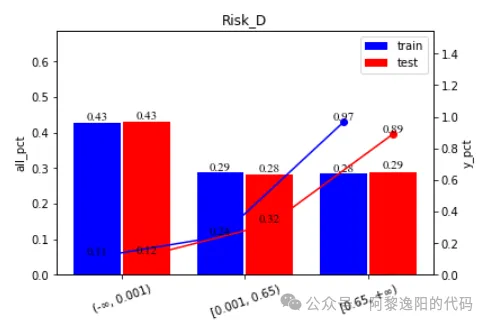
标题Risk_D表示分箱变量名,横轴表示变量分箱区间,左y轴表示柱状图的刻度线,右y轴表示折线图的刻度线。蓝色表示训练集数据,红色表示测试集数据。柱状图表示该箱在整体数据的占比,折线图表示该箱坏样本率。接下来详细介绍该图的生成原理。
二、加载数据
1 加载库
首先加载pandas库,并设置数据读取文件夹。

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











