







Unix/Linux操作系统提供了一个fork()系统调用,它非常特殊。普通的函数调用,调用一次,返回一次,但是fork()调用一次,返回两次,因为操作系统自动把当前进程(称为父进程)复制了一份(称为子进程),然后,分别在父进程和子进程内返回。
fork调用的一个奇妙之处就是它仅仅被调用一次,却能够返回两次,它可能有三种不同的返回值:
1)在父进程中,fork返回新创建子进程的进程ID;
2)在子进程中,fork返回0;
3)如果出现错误,fork返回一个负值;
Python的os模块封装了常见的系统调用,其中就包括fork,可以在Python程序中轻松创建子进程:
# multiprocessing.py
import os
print 'Process (%s) start...' % os.getpid()
pid = os.fork()
if pid==0:
print 'I am child process (%s) and my parent is %s.' % (os.getpid(), os.getppid())
else:
print 'I (%s) just created a child process (%s).' % (os.getpid(), pid)运行结果
Process (876) start...
I (876) just created a child process (877).
I am child process (877) and my parent is 876.由于Windows没有fork调用,上面的代码在Windows上无法运行。有了fork调用,一个进程在接到新任务时就可以复制出一个子进程来处理新任务,常见的Apache服务器就是由父进程监听端口,每当有新的http请求时,就fork出子进程来处理新的http请求。
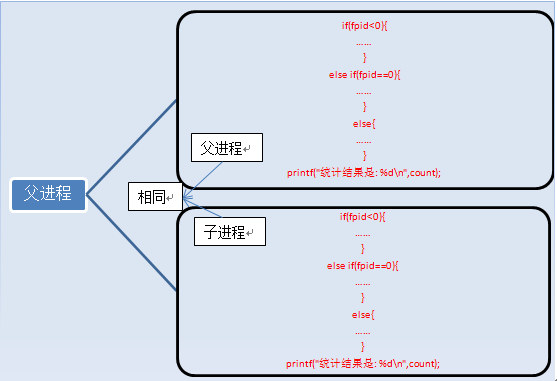
在fork函数执行完毕后,如果创建新进程成功,则出现两个进程,一个是子进程,一个是父进程。在子进程中,fork函数返回0,在父进程中,fork返回新创建子进程的进程ID。我们可以通过fork返回的值来判断当前进程是子进程还是父进程。
引用一位网友的话来解释fpid的值为什么在父子进程中不同。“其实就相当于链表,进程形成了链表,父进程的fpid(p 意味point)指向子进程的进程id, 因为子进程没有子进程,所以其fpid为0.
fork出错可能有两种原因:
1)当前的进程数已经达到了系统规定的上限,这时errno的值被设置为EAGAIN。
2)系统内存不足,这时errno的值被设置为ENOMEM。
创建新进程成功后,系统中出现两个基本完全相同的进程,这两个进程执行没有固定的先后顺序,哪个进程先执行要看系统的进程调度策略。
每个进程都有一个独特(互不相同)的进程标识符(process ID),可以通过getpid()函数获得,还有一个记录父进程pid的变量,可以通过getppid()函数获得变量的值。















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









