







数据治理(一)血缘关系
一、概念
数据血缘也称为数据血统或谱系,是来描述数据的来源和派生关系。数据来源是数据科学的关键,也是被公认为数据信任的核心的部分。说白了就是这个数据是怎么来的,经过了哪些过程或阶段,从哪些表,哪些字段计算得来的。
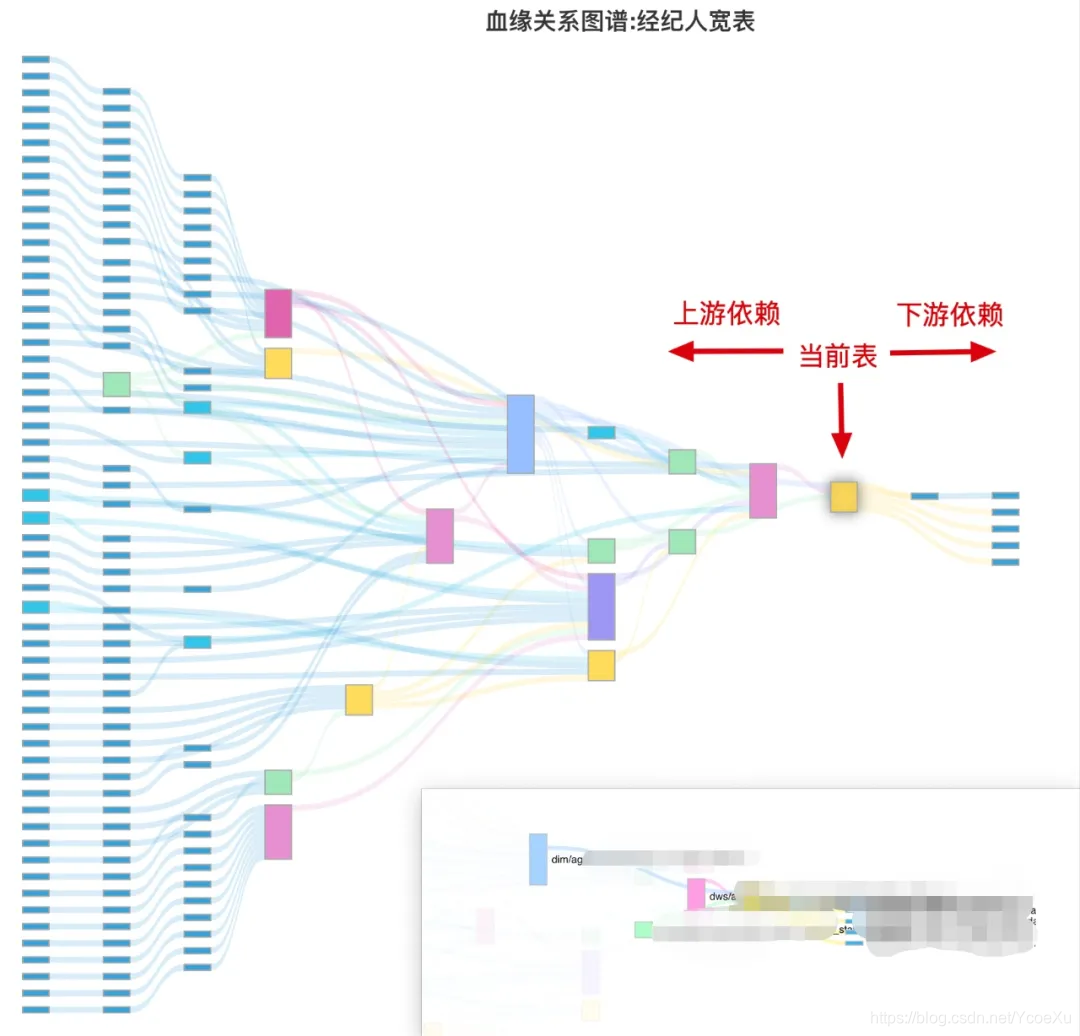
(桑基图是血缘关系的一种表达图表,图表使用ECharts绘制。公司安全要求,对一些业务信息进行模糊处理)
血缘关系按某个表为中心又分为两个方向,当前表依赖到的是上游;当前表被依赖到的是下游。
1. 上游依赖
上游依赖表达的是当前表直接或间接依赖到哪些表
例子:有一天,一个业务员发现他上个月的绩效数据不对的,那么这个问题提交到数仓开发的时候,数仓开发会怎样去查找这个问题呢?
数仓开发首先会找到这个报表指标用的是哪个表-字段,再找到这个表的数据创建脚本,认真查了一遍指标的计算逻辑。确认当前表-字段的计算逻辑没问题后,会往上查找这个表直接依赖到的表-字段。再继续用同样的方法确认这些表-字段,如此一层层定位问题…

(这个是经纪人宽表的上游依赖图。用树形图可以清晰展示依赖关系,但它不能表达环状的依赖,直接使用ant-design的树形控件)
2. 下游依赖
下游依赖表达的是当前表被哪些表直接或间接依赖。
例子:某个表能不能下线?
首先要检查的就是这个表有没有被依赖到。如果有,那肯定是不能直接下线的(至少需要将下线下游的表);如果没有,也还需要再进一步确认下这个表还有没有被使用。没下游依赖并不代表没被使用!

(这个是经纪人宽表的下游依赖图,报表的依赖没有在这里显现,但可以在表的详情里面查看到)
二、为什么需要建立血缘关系
问这个问题,其实应该先问:数据要不要治理?这跟开一个公司,员工要不要管理一样,答案是肯定的。只是治理到什么程度而已。
刚开始搭建大数据平台时,是比较忽视数据治理的。几个开发,几十个表,用个Excel或文档就可以搞定的事。但随着迭代的继续,表越来越多;随着人员的变更,会越来越难以管理。指标难找、不知道已经存在这个指标…于是重复开发指标,然后就出现了各种指标/数据不一致的问题。烟囱式的开发也很容易带来这些问题。企业数仓发展到这个阶段,就需要考虑多人协作,统一的标准,解决数据一致性等问题了。数据治理就是解决这类问题的基础,它可以说是发展到一定阶段必定会演化出来的系统。
数据治理,应该系统性地去思考解决这些问题,统筹地去考虑如何限制和落地定制的规范,而不只是用几个文档或Excel展示。数据治理的基础是采集各种信息,将其分类归整好,然后定制出一个合理的规则进行执行监督。各种信息中血缘关系是核心,从数据怎么来,怎样分布的,怎么使用,怎样结束。这就形成了数据治理里面的数据地图、数据质量、数据生命周期等一系列模块。后续会有相关的文章单独讲解数据治理…
另外,血缘关系也是指标的派生关系、指标数据的影响因子,通过这个关系,对于指标数据异常的智能发现提供了最直接的溯源依据。比如平台经纪人的活跃指标突然下降,程序可以通过这个指标的上游关系自动的回溯,快速找到出现异常的最源头表-字段。这样对数据异常的排查难度会大大降低。
三、Apache Atlas?
1. 表级别的血缘关系
如果只是到表级别,这个实现比较简单,像hive tool就自带了一个工具类可以直接获得:

2. 字段级别的血缘关系
到表级别显然是不够的,我们需要更细粒度的,到字段级别的血缘关系。选择并不多,Apache Atlas名气很大,可以提供血缘关系和元数据管理功能。
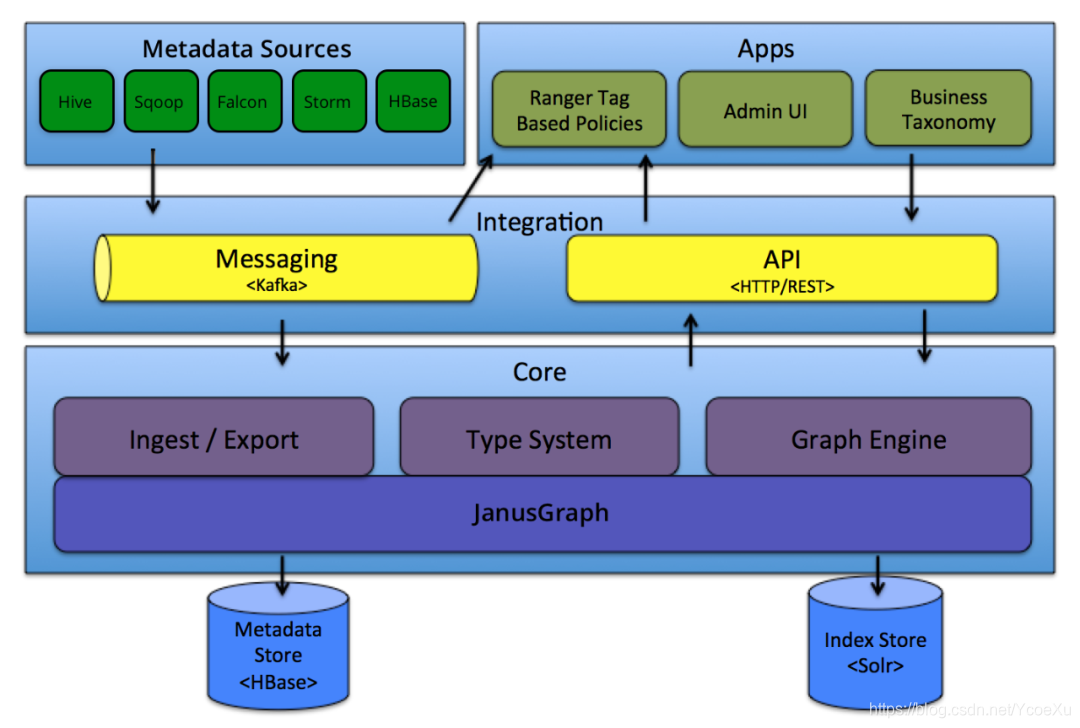
(来自:https://atlas.apache.org/#/Architecture)
Apache Atlas支持的大数据组件很多:Hive / Sqoop / Falcon / Storm / HBase …也提供了接入Hook和接口的接入方式。底层存储使用HBase,使用Solr实现索引,存储之上用JanusGraph将其转换成图数据。
(来自:https://atlas.apache.org/#/ClassificationPropagation,还是挺炫酷)
我们第一版的数据血缘关系就是基于Apache Atlas搭建,使用它的元数据扩展功能扩展了中文名、标签等字段。但是在使用的过程,也遇到了很多问题,主要是复合查询的支持不够和性能问题,这主要是由它的底层索引架构和存储介质决定的。
四、自研duo-lineage
1. 为什么要重复造轮子
之前我就写了几个duo系列的产品了(duo-doc / duo-graphql / duo-schedule …),名字不重要,重要的是为什么我们要重新造一个轮子?
数据治理是一整套的方案,不仅仅是采集血缘关系。在规划这一套治理方案过程中,越来越觉得数据血缘信息的重要性,很有必要将它前置在执行脚本之前(Apache Atlas在执行阶段通过Hive Hook的方式采集的血缘关系,属于被动式采集,数据有点滞后)完成数据血缘的提取。以配合治理方案前期的规范验证和脚本依赖自动发现,为发布系统和智能调度系统提供数据。
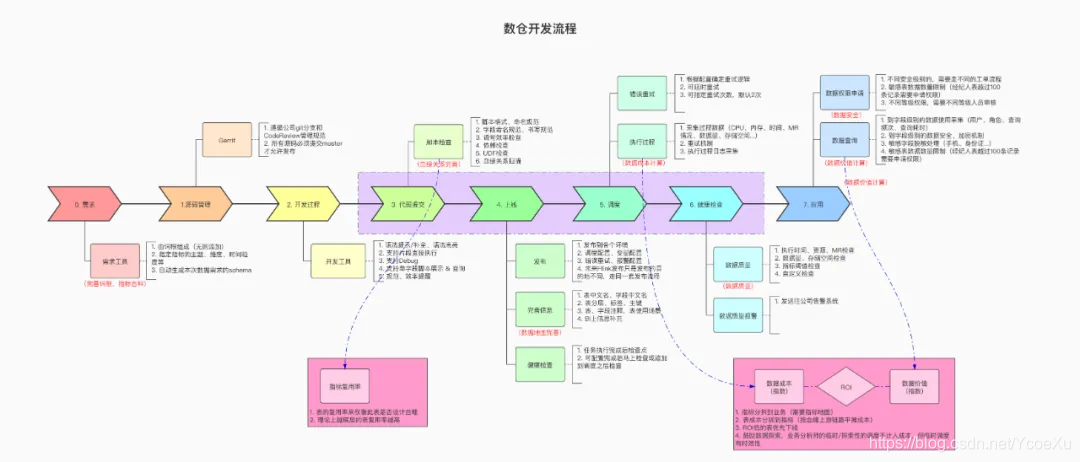
(DwOps流程图,会在后续的文章里更多介绍)
详见:https://www.processon.com/view/link/5fed67095653bb21c1b1acaf
前置数据血缘解析,在脚本入库后自动触发脚本解析,同时对制定的一些规范进行验证,比如命名是否规范,分层是否合理,是否跨层依赖等。没有规范的限制,开发人员为了省事不去构建中间统计表,有可能出现ADM层的指标直接查ODS数据,这对数仓结构和性能来说是个灾难性的。
数据血缘关系同时也是脚本调度依赖关系。目前业内的调度系统oozie / airflow / azkaban…都得人工去配置依赖,容易出错。前置数据血缘解析可以实现自动的调度依赖配置,让调度的配置工作自动完成,最大限度地减少人工操作失误的可能性。
数据治理是一整套的方案,理念是通过程序去落地规范,完善数据采集。让治理工作不依赖人工维护(人是不可靠的),成为一个闭环,这样才能保证数据治理平台信息的准确性和关联性,避免形成信息孤岛。将DevOps的理念引入到大数据领域,将开发流程、发布系统、智能调度与数据治理方案整合成一套完整的系统,为数仓保驾护航。
为了实现这个宏大的想法,在数据血缘这一层面依赖Apache Atlas是实现不了的,所以我们重新造了一个轮子…
2. 技术选型
数据的产生方式很多,Shell、ETL、代码+SQL混合实现的spark,甚至纯scala/java代码实现。我们没办法实现所有数据血缘的采集。只能将采集范围最小化,收缩到两大类:Sqoop脚本和SQL(可能是Hive SQL、Spark SQL、Flink SQL…统称为SQL了)。
Sqoop的脚本其实最终也是转换成SQL,所以不再过多阐述,大的方向就是SQL化。(数据治理理念:所有数据处理必须可治理,SQL化更方便治理)
确定了SQL化治理,那么构建血缘关系的关键就是解析SQL生成AST(抽象语法树),再进行一步解析血缘关系。那么AST的解析就成了关键,当前可用的方案挺多的
Alibaba Druid:它是一个数据库连接池,里面带了一个SQLParser,可以解析SQL为AST。
优点:依赖简单,解析出来的AST简单,对Hive SQL的支持还不错,目前确实还有些语法不支持,但最近的版本在Hive SQL的支持在逐渐增强
缺点:AST解析工具只是它的副业 [哭笑],另外有些不支持的语法需要额外处理
queryparser:uber开源,实现了hive、presto、vertica、teradata、pg等解析器。
优点:定制化很高,对语法支持好
缺点:使用haskell编写,学习成本比较高
hive:hive内置的解析器,依赖的包太重
优点:Hive SQL完美支持(亲爹)
缺点:包依赖太重,解析出来的AST比较复杂
Antlr4:通用的高性能的语法分析器
优点:高性能,灵活,自己写几乎可以把控它的所有行为
缺点:太底层了,需要自己写解析规则,后续的维护成本也会很高,Alibaba Druid就是基于Antlr4实现的AST
…
综合各种情况,我们选择了 Alibaba Druid。
3. 实现
解析AST,无非就是遍历这棵树,解析出需要的数据再向上冒泡。实现原理挺简单的,但是还是有很多的细节需要处理的。处理流程如下图:
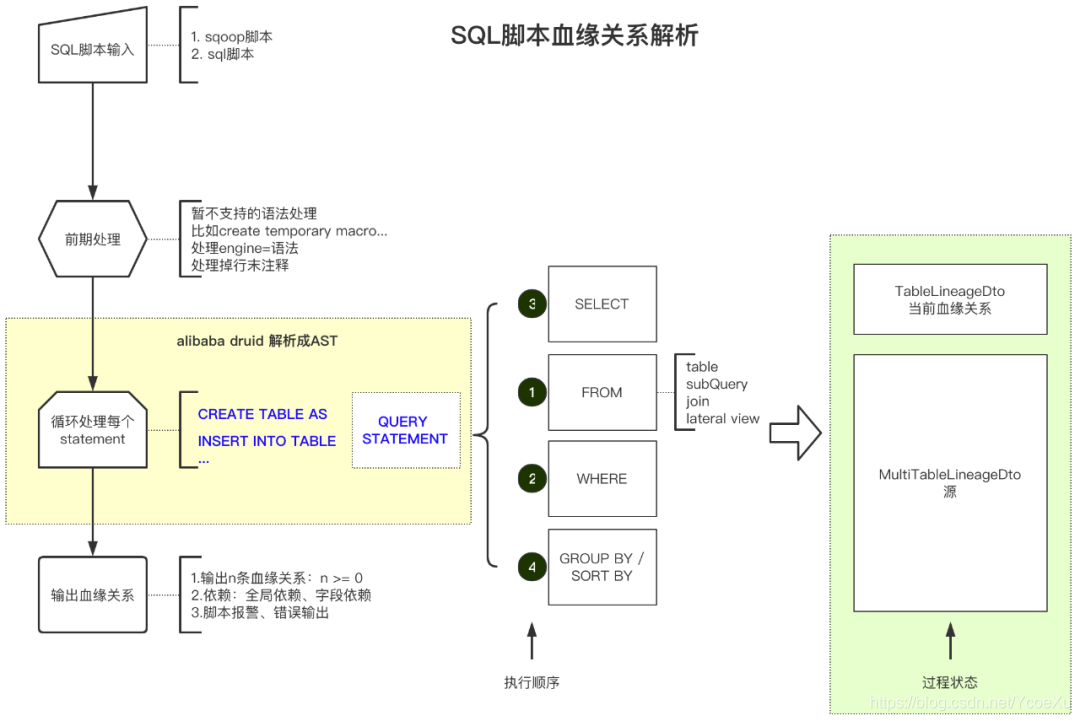
首先在输入时,如果是sqoop脚本,需要先解析脚本,将其转换成SQL。
其次就是对目前不支持的语法进行处理,比如注释掉,只要处理后不影响数据血缘就可以了。
接进来就是对各个解析出来的Statement进行处理,SQL的Statement有很多种,有用的就是Create Table / Insert / Select这三类。当然在执行过程中还需要对Drop Table进行处理,临时表可以看成是临时的变量,不会对整个过程有什么影响,所以在血缘关系中会隐藏掉,将它的血缘直接传递过去即可。
无论是哪种Statement生成的数据,最终都会落到QueryStatement上,对Query的解析才是重头戏。其中一个细节就是在语法树的处理顺序上。From是源头,所以需要先解析它。它可能多种源组成,比如:实体表、子查询、JOIN、甚至是由lateral view等抽象出来的。From节点可能解析出多个源头(一般会指定别名)然后交给Where节点进行筛选。Where / Group By / Sort By是对所有的字段起作用的,所在这些节点上出现的字段都归为全局依赖。
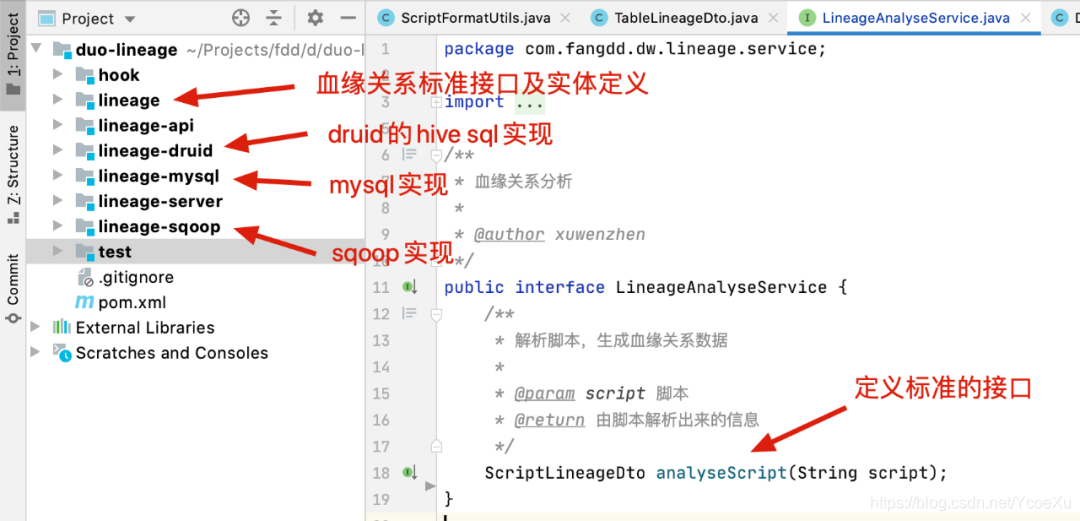
(项目模块截图,模块化设计,可以更好扩展)
hook是使用端插件,比如hive hook实现,用于上报执行过程的SQL,用于采集数据使用情况,超出了本文的内容,会在后续文章中介绍
lineage-api:dubbo客户端协议定义,是对外提供的协议包
lineage-server:dubbo服务端,对外暴露了dubbo和RESTful两类接口
定义了个简单的接口,解析的结果除了血缘关系数据外,还包含了一些脚本规范、错误、引入的jar包、变量等信息,主要是在DwOps发布系统中使用。为了确保项目质量,每类脚本都写了一组单元测试,确保每次迭代不会影响到核心功能。
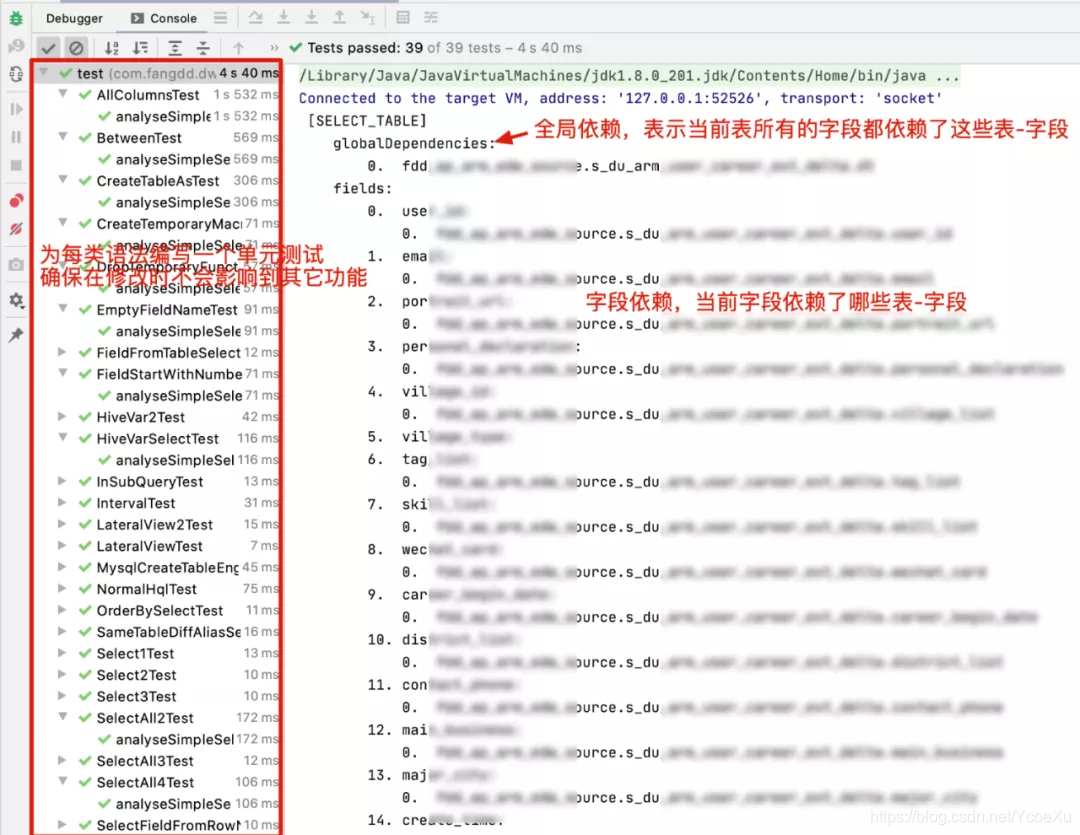
(单元测试截图,右侧是到字段级别的血缘关系数据)
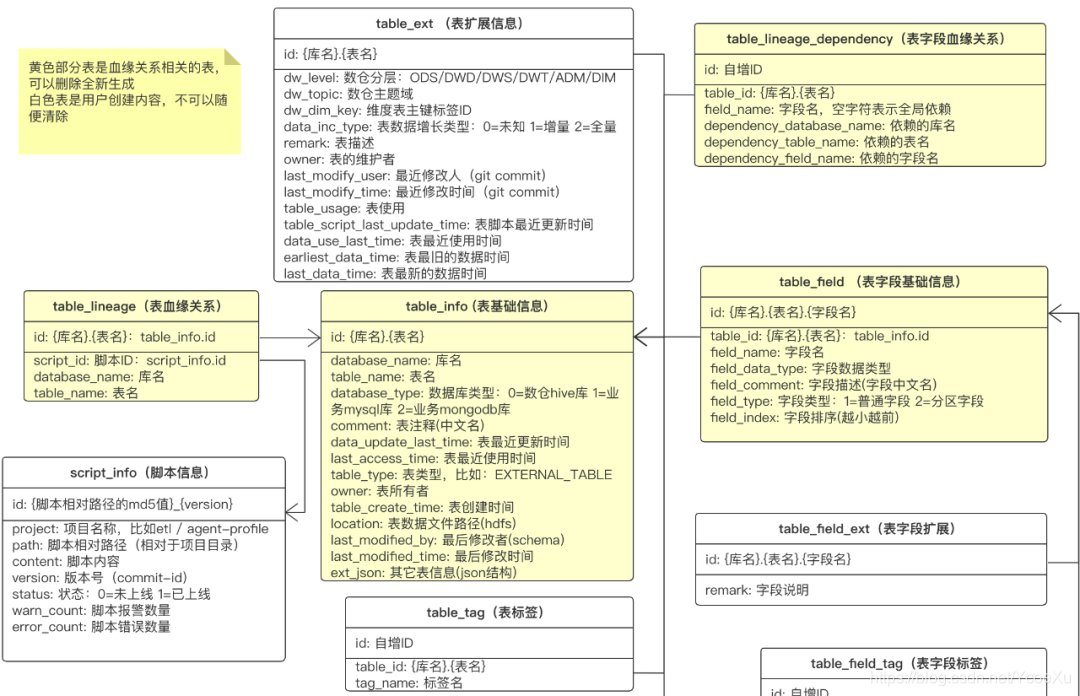
(关键表设计,只包含关键的字段,非全部字段)
表设计上,分为两大块,浅黄色部分是数据血缘的表,可以随时清空,从源码中重新构建。白色部分是数据字典的表,是平时维护的信息,不可再生。如此设计主要也是为了更好的迭代血缘关系,部分表可以比较无压力的删了重建。
4. 查询性能
吸取Apache Atlas的教训,在接口性能优化上做了精心设计,确保在所有的查询中可以瞬间返回数据。事实证明,仅此一项,大家都觉得这是一次成功的重造轮子
一张表完整的血缘关系可能会很复杂,关联上的表可达上百张,如果使用传统的存储/缓存(redis),这么多的查询也会消耗不少的时间。所以最好的选择是使用内存缓存!对于静态数据来说,其它实现不是很复杂。但是对于多节点部署的动态变更的数据,情况就复杂很多了。
我们使用了Hazelcast实现了内存缓存,具体使用可以查询官网。这里大概说下Hazelcast的能力:
- 分布式内存缓存,它的内置机制实现了数据变更时的同步,不需要我们额外去实现
- 实现了分布式队列。这个特性,本项目没有用到,但在duo-schedule中大量使用
- 实现了分布式锁,在更新血缘关系时使用到
系统启动时,从数据库中加载数据,将每张表的直接上游、下游关系数据保存到内存Map中。在查询血缘关系时,直接在内存里递归遍历依赖的表,构建完整的血缘关系图。注意这里需要特殊处理下循环依赖的表,避免出现死循环。
经过这一设计,表血缘关系响应几乎可以在10ms内返回。

(使用关系图表达,可能会非常复杂,要加载这些关系需要做些特殊处理,图表使用ECharts的关系图绘制 )
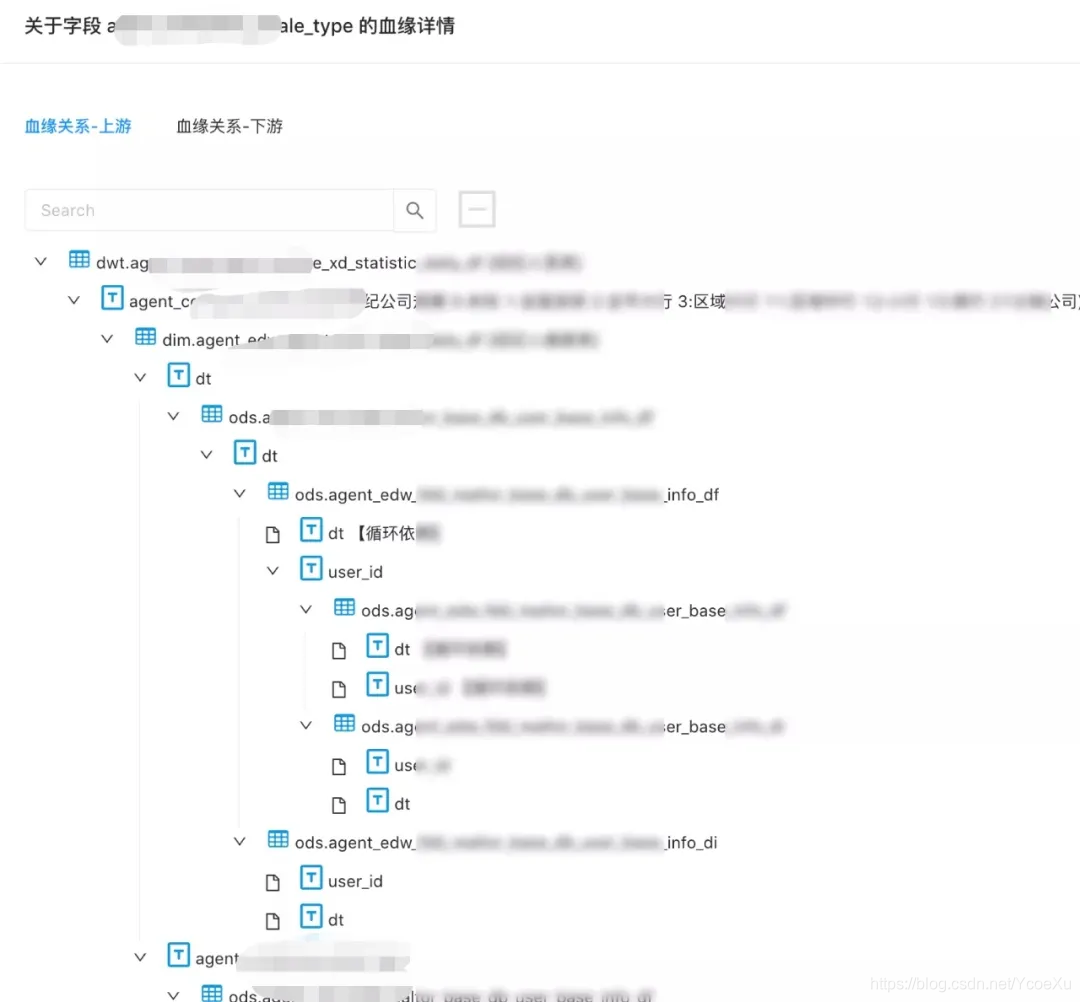
(字段级别的血缘关系)
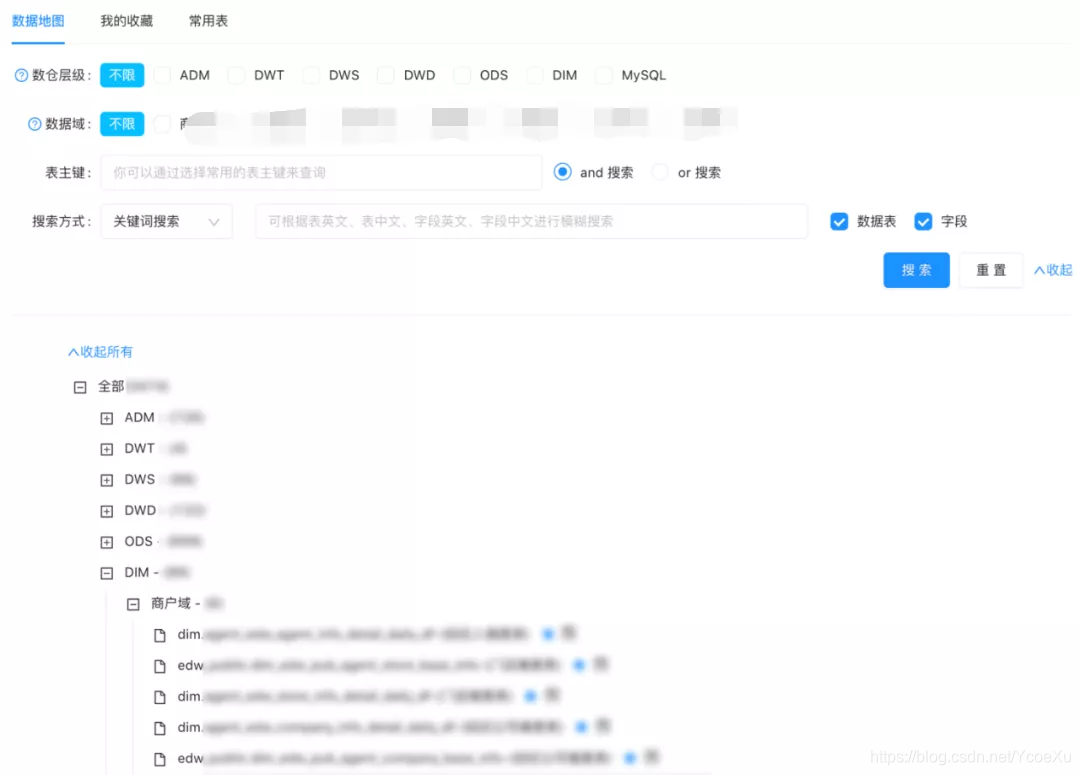
目前,我们已经打通了从业务库到数仓再回到业务库整个数据链条的血缘关系,并提供了多个维度的搜索功能,为数据治理提供了可靠的血缘关系数据。
参考:
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.406.8789&rep=rep1&type=pdf
https://github.com/alibaba/druid
https://atlas.apache.org
https://github.com/apache/hive/blob/master/ql/src/test/org/apache/hadoop/hive/ql/tool/TestLineageInfo.java
https://github.com/uber/queryparser
https://docs.hazelcast.com
血缘关系解析项目 duo-lineage 项目地址:https://gitee.com/duoec/duo-lineage

















 1532
1532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









