






0 简介
丹成学长,搜集分享最新的网络工程专业毕设毕设选题,难度适中,适合作为毕业设计,大家参考。
学长整理的题目标准:
- 相对容易
- 工作量达标
- 题目新颖
🧿 选题指导, 项目分享:见文末
1 如何选题
最近非常多的学弟学妹问学长关于选题的问题,所以今天学长来教大家如何进行毕业设计选题!
毕业设计的选题尤为重要,选好题目是最终完成毕业设计的第一步。
因为题目的选择跟之后的设计实现密不可分,如果你所选择的题目是你无法实现的,而且定题以后就不能修改了,这无疑会给你带来很大的困扰。
2 最新网络工程选题
2.1 Java web - SSM 系统
- 基于java ssm框架的学生周报管理系统
- 基于微服务框架的电影院订票管理系统
- 基于SSM的农产品商品信息管理系统 - vue ssm
- 基于SSM的家教网课学习平台 - ssm vue
- 基于SSM的租房信息管理系统 - ssm vue
- 基于SSM的教师评价考核管理系统 - ssm vue
- 基于SSM的婚纱摄影业务系统 - vue ssm
- 基于SSM的汽车租赁系统 - ssm vue
- 基于SSM的企业销售培训系统 - ssm vue
- 基于SSM的在线药品超市购物系统 - ssm vue
- 基于SSM的在线教学视频点播系统 - ssm vue
- 基于SSM的驾校预约培训管理系统 - vue ssm
- 基于SSM的小区车位出租管理系统 - ssm vue
- 基于SSM的健身运动平台管理系统 - ssm vue
- 基于SSM的员工/学生宿舍后勤管理系统 -ssm vue
- SSM汽车故障报修管理系统 - ssm vue
- 基于SSM的留学生交流平台系统 - ssm vue
- 基于SSM的在线网课学习平台设计与实现 - ssm vue
- 基于SSM的网上购物商城系统 - vue ssm
- 基于SSM的在线医药商城购物系统 - vue ssm
- 基于SSM的共享充电宝管理系统 - ssm vue
- 基于SSM的在线电影售票系统 - ssm vue
- 基于SSM的勤工助学管理系统 - ssm vue
- 基于SSM的疫情校园师生登记备案系统 - vue ssm
- 基于SSM的疫情下医院门诊就医管理系统 - vue ssm
- 基于SSM的家庭美食食谱管理系统 - vue ssm
- 基于SSM的在线音乐网站设计与实现 - vue ssm
- 基于SSM的中医商城管理系统 - vue ssm
- 基于SSM的线上医院诊断管理系统 - vue ssm
- 基于ssm个人健康信息管理系统 - ssm vue
- 基于SSM的游戏攻略出售系统 - ssm vue
- 基于SSM的房屋租赁管理系统 - ssm vue
- 基于SSM与垃圾分类的信息管理系统 - ssm vue
- 基于SSM的旅游信息分享管理平台 ssm vue
- 基于ssm的学生社团管理系统 - ssm vue
- 基于SSM的大学生就业企业推荐系统 - ssm vue
- 基于SSM的大学生兼职信息管理系统 - ssm vue
- 基于SSM的考研信息搜集分享管理系统 - ssm vue
- 大学生在线兼职发布与管理平台 -SSM+VUE
- ssm在线医疗诊断跟踪系统
- 基于ssm的毕设选题管理系统
- 基于java的毕业设计选题题目推荐
- 基于SSM与VUE的汉服销售论坛系统
2.2 大数据方向
- 数据挖掘相关算法的研究与平台实现
- 数据挖掘中聚类方法的研究
- 基于支持向量机的过程工业数据挖掘技术研究
- 数据挖掘技术与分类算法研究
- 基于数据挖掘的电站运行优化理论研究与应用
- 数据挖掘算法优化研究与应用
- 海量流数据挖掘相关问题研究
- 半结构化数据挖掘若干问题研究
- 海量数据挖掘技术研究
- 数据库中数据挖掘理论方法及应用研究
- 时间序列数据挖掘中的维数约简与预测方法研究
- 基于数据挖掘技术的联网审计风险控制研究
- 基于数据挖掘的道路交通事故分析研究
- 基于数据挖掘的金融时间序列预测研究与应用
- 基于数据挖掘技术的金融数据分析系统设计与实现
- 基于数据挖掘的微博用户兴趣群体发现与分类
- 基于数据挖掘的煤矿安全可视化管理研究
- 基于数据挖掘技术的财务风险分析与预警研究
- 可视化数据挖掘技术在城市地下空间GIS中的应用研究
- 基于RFID的物流大数据资产管理及数据挖掘研究
- 基于数据挖掘的战略管理会计若干问题研究
- 数据挖掘在零售银行精准营销中的应用研究
- 一种基于云计算的数据挖掘平台架构设计与实现
- 面向服务的数据挖掘关键技术研究
- 基于数据挖掘的基坑工程安全评估与变形预测研究
- 基于消错理论的数据挖掘错误系统优化方法及应用研究
- 基于数据挖掘的当代不孕症医案证治规律研究
- 基于数据挖掘的网络入侵检测关键技术研究
- 基于HADOOP的数据挖掘研究
- 数据挖掘技术在P2P网络金融中的应用研究
- 基于大数据的数据挖掘引擎
- 基于YARN的数据挖掘系统的设计与实现
- 基于数据挖掘从经验方和医案探析岭南名医治疗妇科疾病的诊疗和用药规律
- 渐进式滑坡多场信息演化特征与数据挖掘研究
- 基于深度学习的运动想象脑电信号分类研究
2.3 人工智能方向
- 基于指纹识别的门禁管理
- 智能AI语音灯控
- 智能AI在线答疑
- 智能语音搜索
- 人机在线五子棋游戏
- 智能小车定位和路径规划系统
- 智能蔬菜种植管理
- 智能在线学习平台
- 基于机器学习的智能农作物识别
- 基于机器视觉的微生物样本识别系统研发
- 基于图像识别的停车收费系统
- 智能家庭种植系统
- 基于深度学习的恶意代码可视化检测及分类研究
- 基于文本相似度的在线答疑系统
- 基于语音识别的智能日程管家
2.4 其他方向
- 智能农业大棚环境监测数据分析系统
- 网页在线聊天系统的设计与实现
- 智慧小区团购系统
- 排课管理系统
- 权限管理系统及数据可视化
- 智能小区物业管理系统的设计实现
- 治安综合管理信息系统的设计与实现
- 车辆寄售系统的设计与实现
- 爱心捐赠物资维护系统的设计与实现
- 抽奖营销系统的设计与实现
- 券商资讯平台的设计与实现
- 疫苗监管平台的设计与实现
- 知识产权申请服务平台的设计与实现
- X学校在线招生报名系统的设计与实现
- 智慧育幼园管理系统的设计与实现
- 社会志愿者服务管理平台的设计与实现
- 美食菜谱在线分享平台
- 家装在线平台的设计与开发
- 中学生报考及学业规划咨询系统
- 健康咨询及在线评估分析系统
- 闲置物品置换平台
- 垃圾分类知识管理及在线学习平台
- 智能天气管家系统设计与实现
- 智能学习计划规划服务
- 个人健康管理服务系统
- 智能办公室管理系统
- 流浪动物领养系统的设计与实现
学长项目展示:
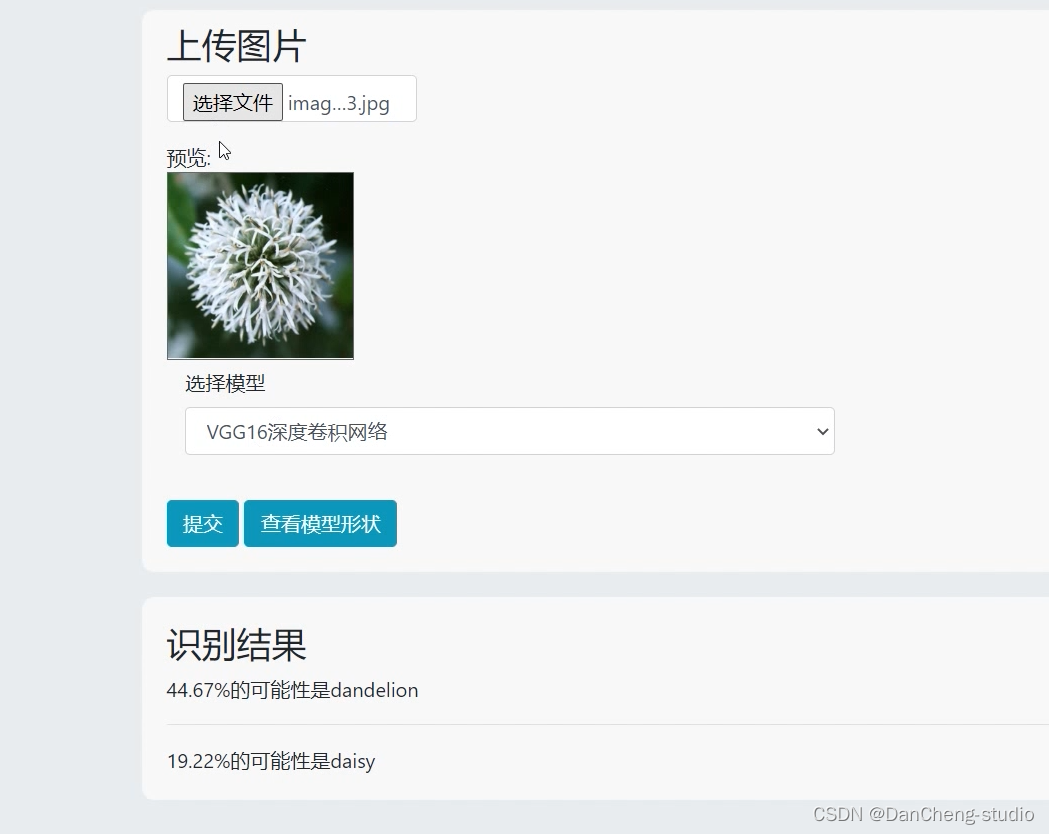
植物识别:
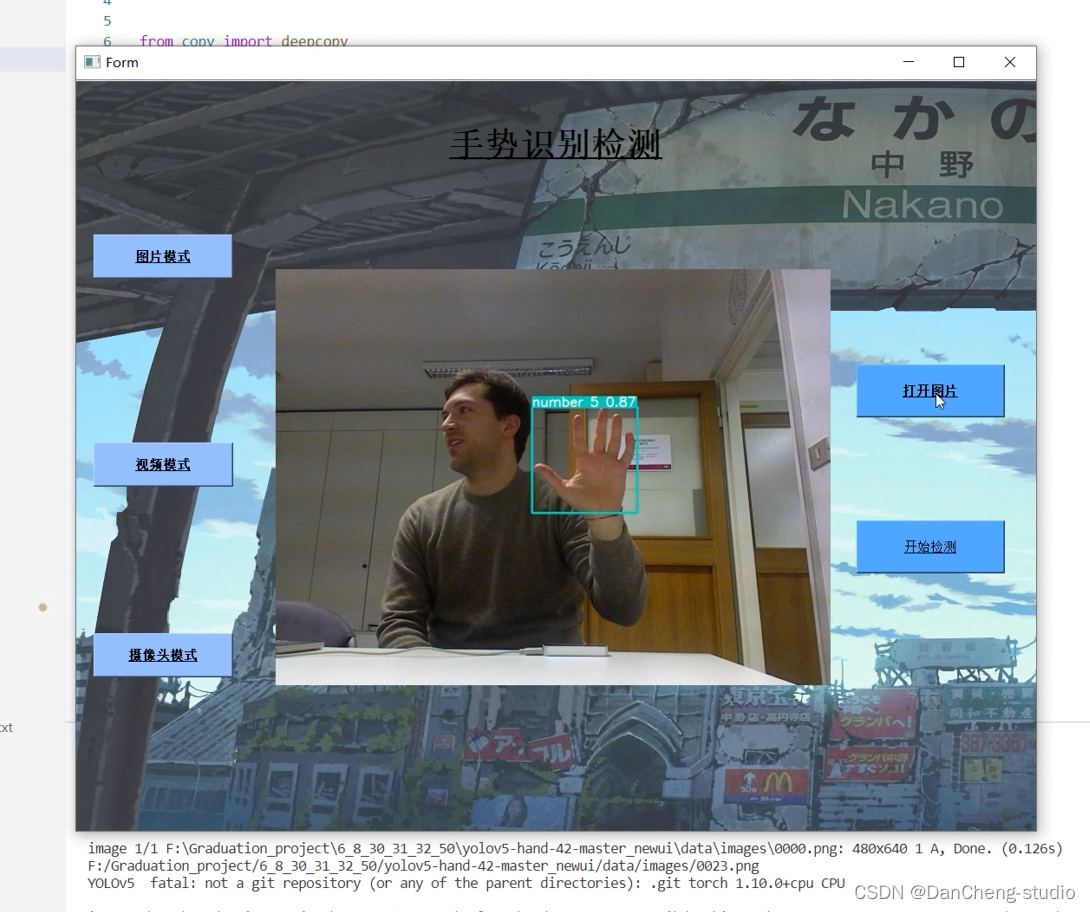
手势识别:
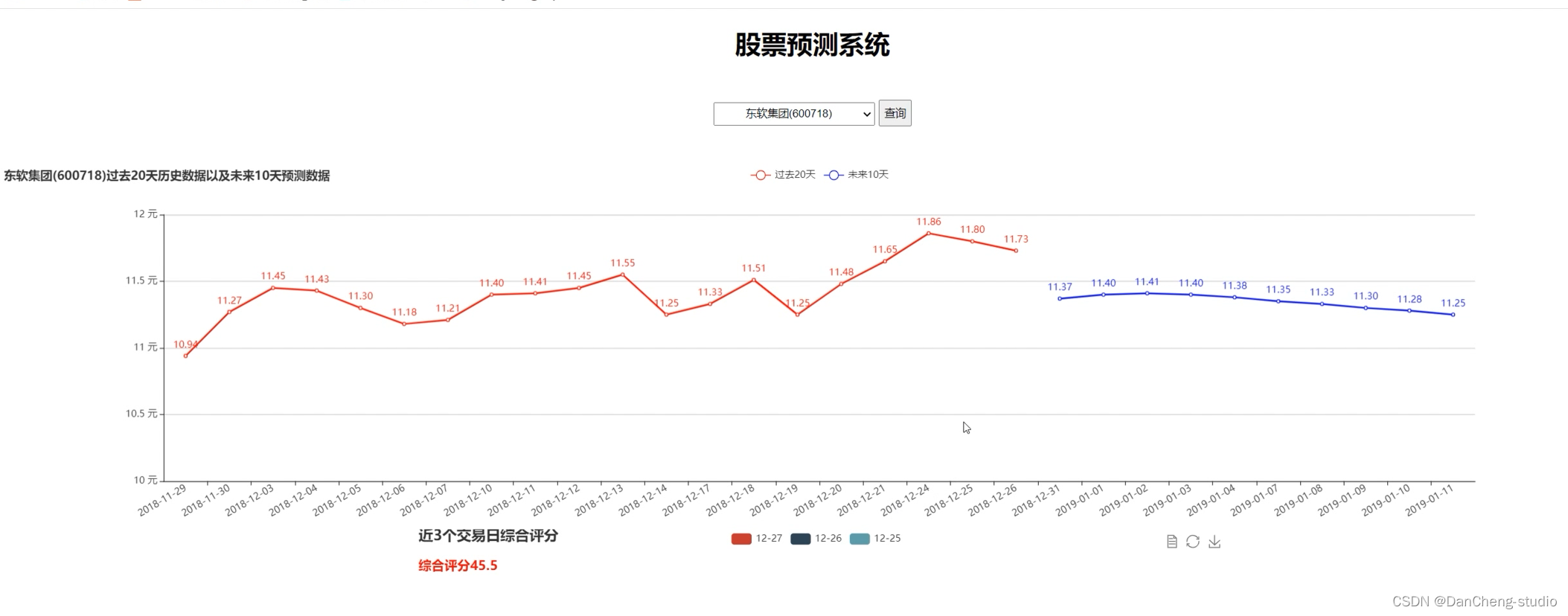
股票预测
自动驾驶,车道线检测:

项目较多,其他的不一 一展示了。。。。。。
4 最后
**毕设帮助, 选题指导, 项目分享: ** https://gitee.com/yaa-dc/warehouse-1/blob/master/python/README.md















 322
322











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









