






文章目录
0 前言
🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是
🚩 基于大数据的电影数据爬取分析可视化系统
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:4分
- 工作量:4分
- 创新点:3分
🧿 选题指导, 项目分享:见文末
1 课题背景
随着互联网的快速发展,越来越多的人喜欢在微博、知乎、豆瓣等社交网站上发表自己对某些事物的想法、态度或意见。用户同时也会将自己购买的产品或体验到的服务,在这些社区式的网站上评价,这样通常会带动他人也前去购买或体验,形成口碑效应。
社交应用及网站上有源源不断的信息发布,这些信息中隐含着大量对我们及企业有收集价值的资源。就像用户评分和评价系统中,用户不但会对作品进行评比,还分享和传播了作品信息。如果能够获取这些数据并对其进行分析,可以让人们挑选到满意的书籍、选择出一部精彩的电影,也可以帮助企业改进产品的服务等。使用爬虫程序可以高效地对社交网站上的信息进行收集、组织和管理。豆瓣网作为社交网站的代表,提供了在图书、电影和音乐等方面独树一帜的评分、推荐及比价体系,在社交网络中产生了深远的影响。
2 项目效果展示
2.1 主界面展示
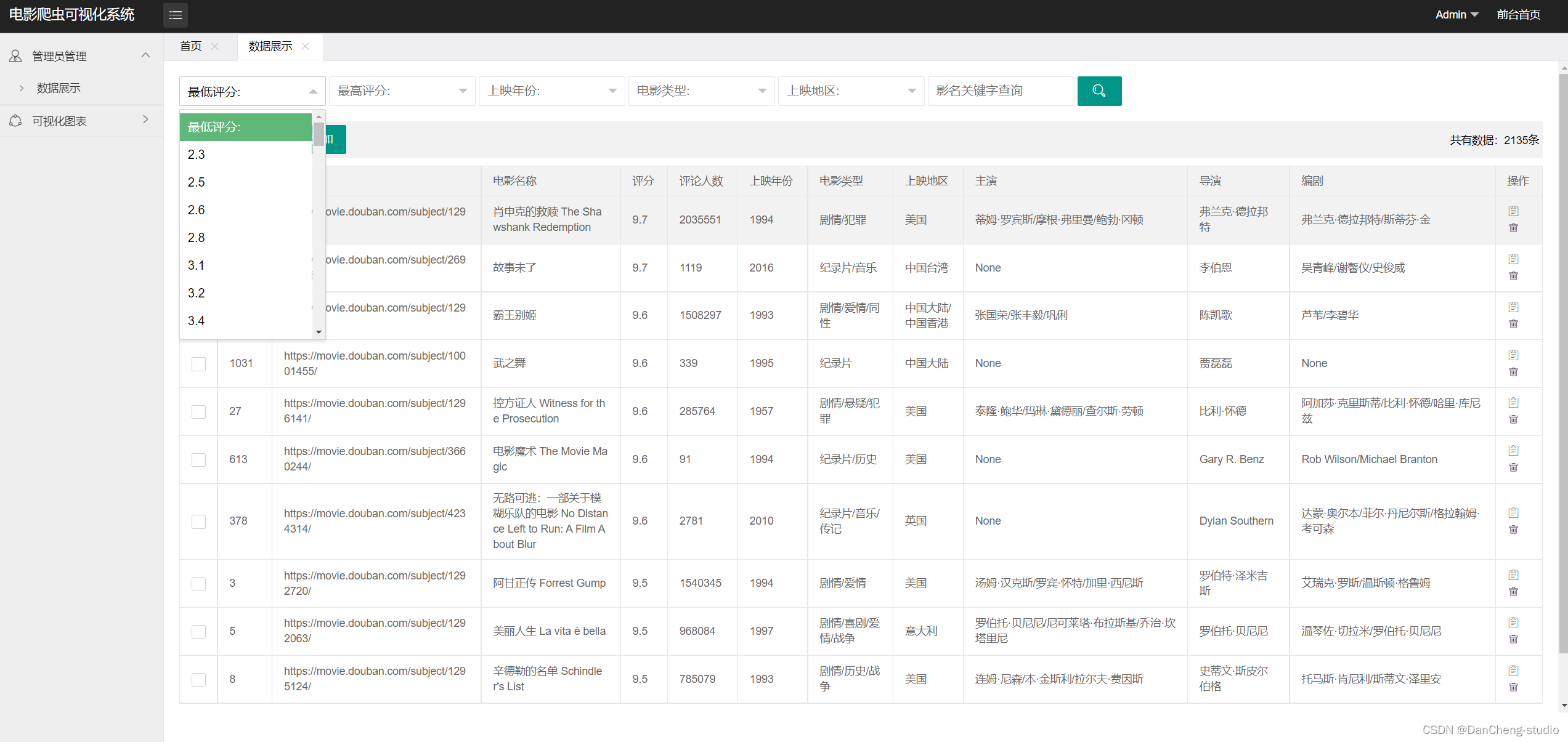
2.2电影数据查询
管理员可对电影数据进行查询,可根据“最低评分”,“最高评分”,“上映年份”,“电影类型”,“上映地区”,“影名关键字”等标签进行筛选、查询。
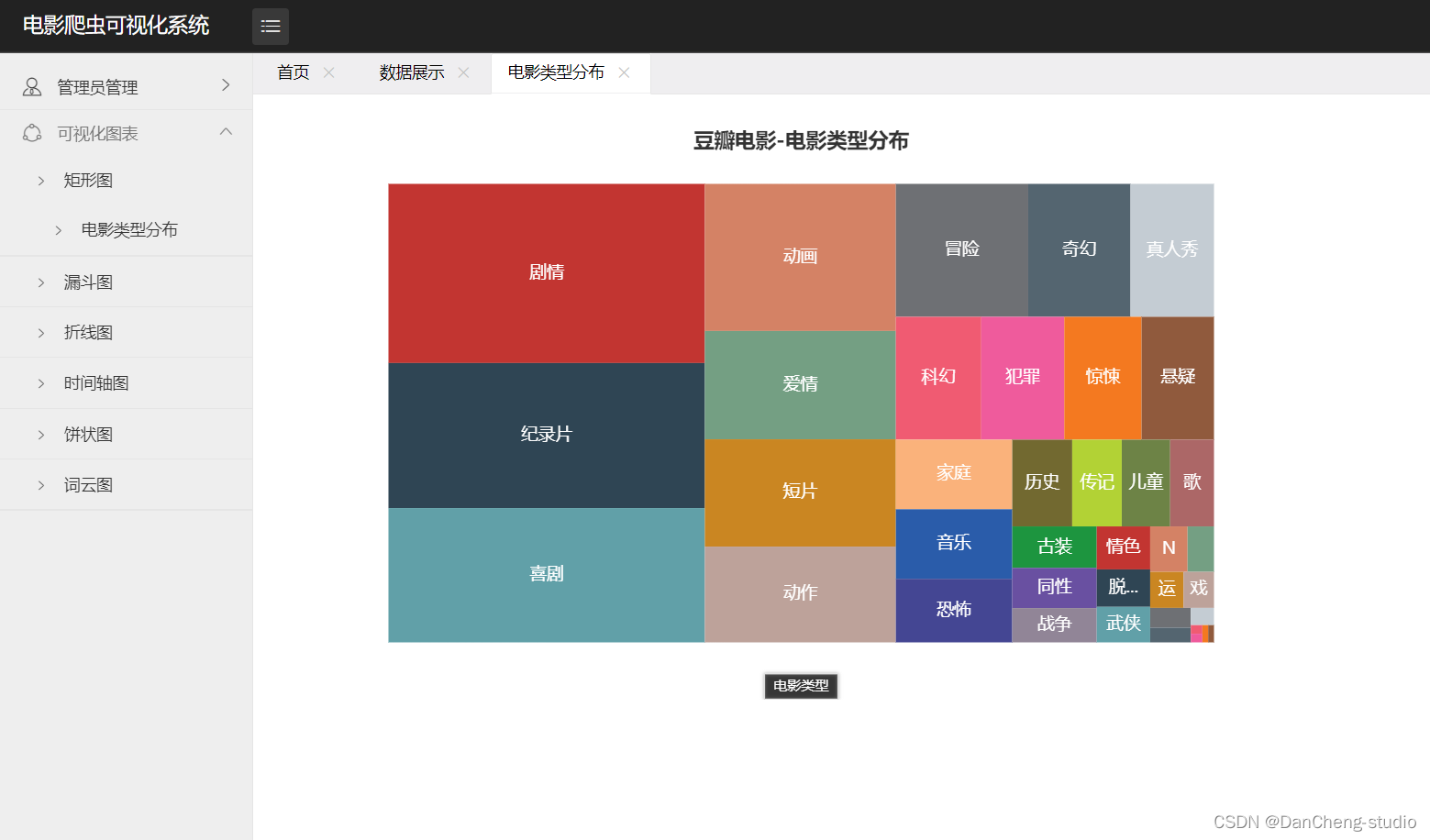
2.3可视化展示
- 电影类型矩形图:可以清楚的看到剧情,纪录片,喜剧类型的电影所占比重较大。
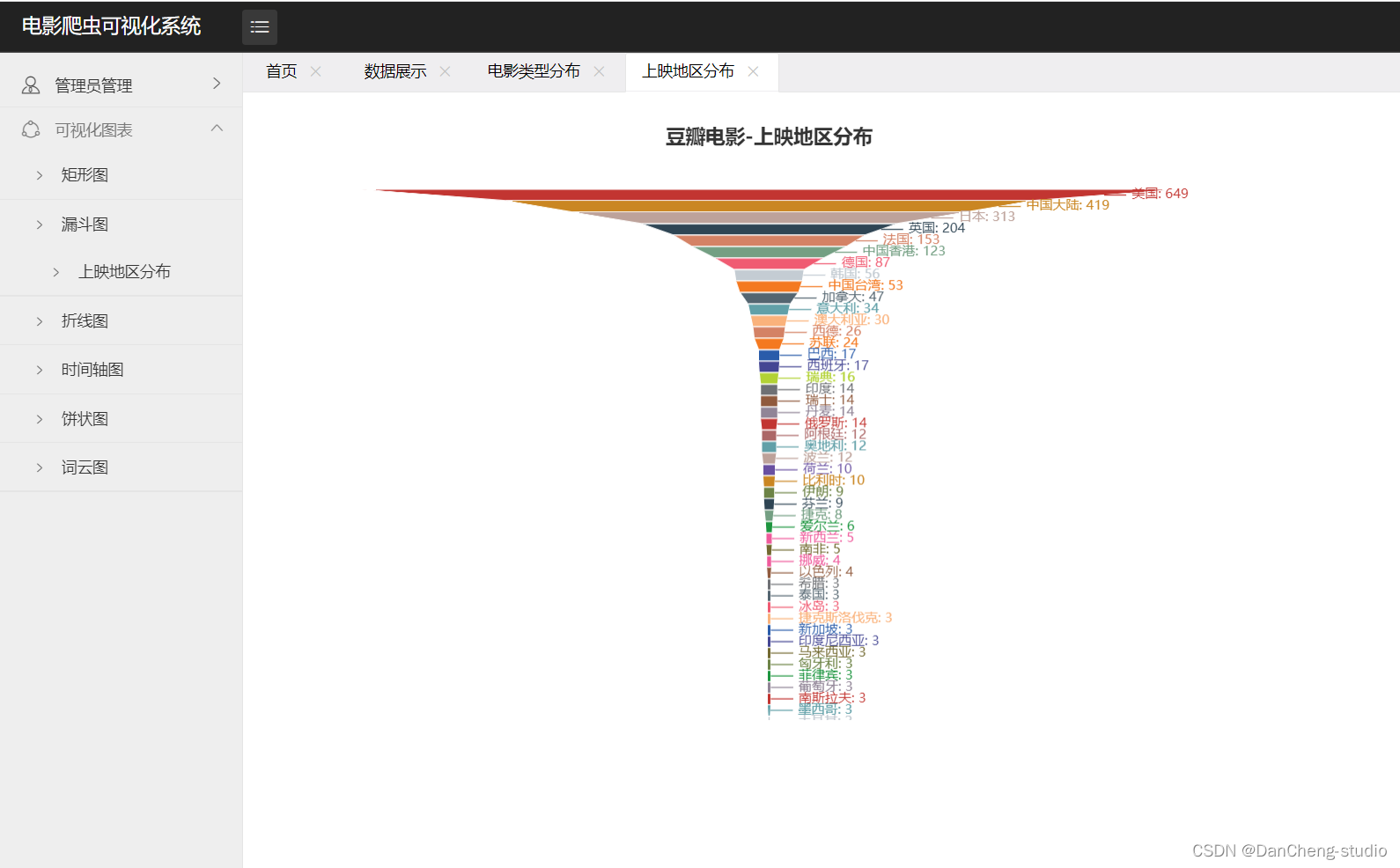
- 上映年份漏斗图:可以看到中国、美国上映地区较多。
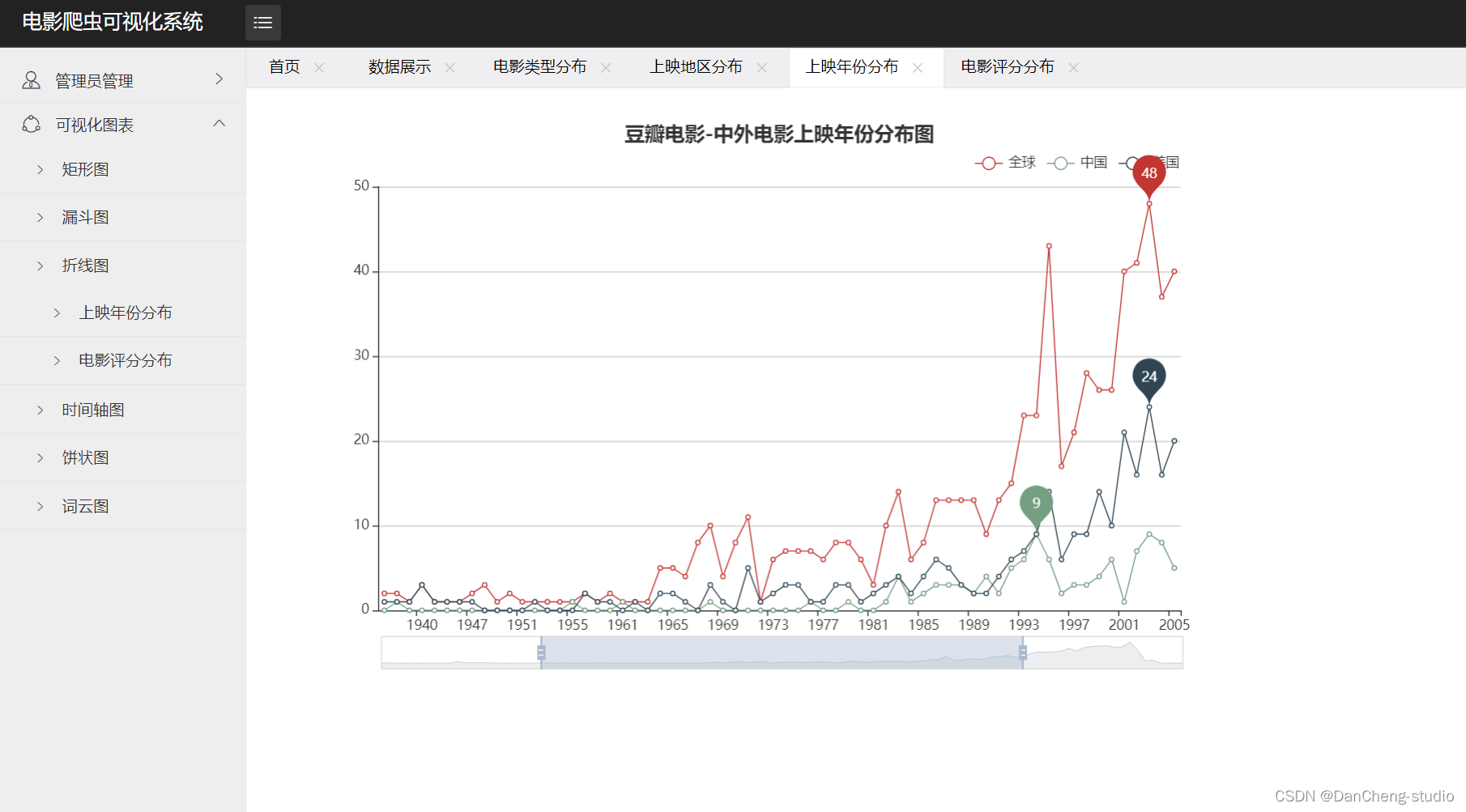
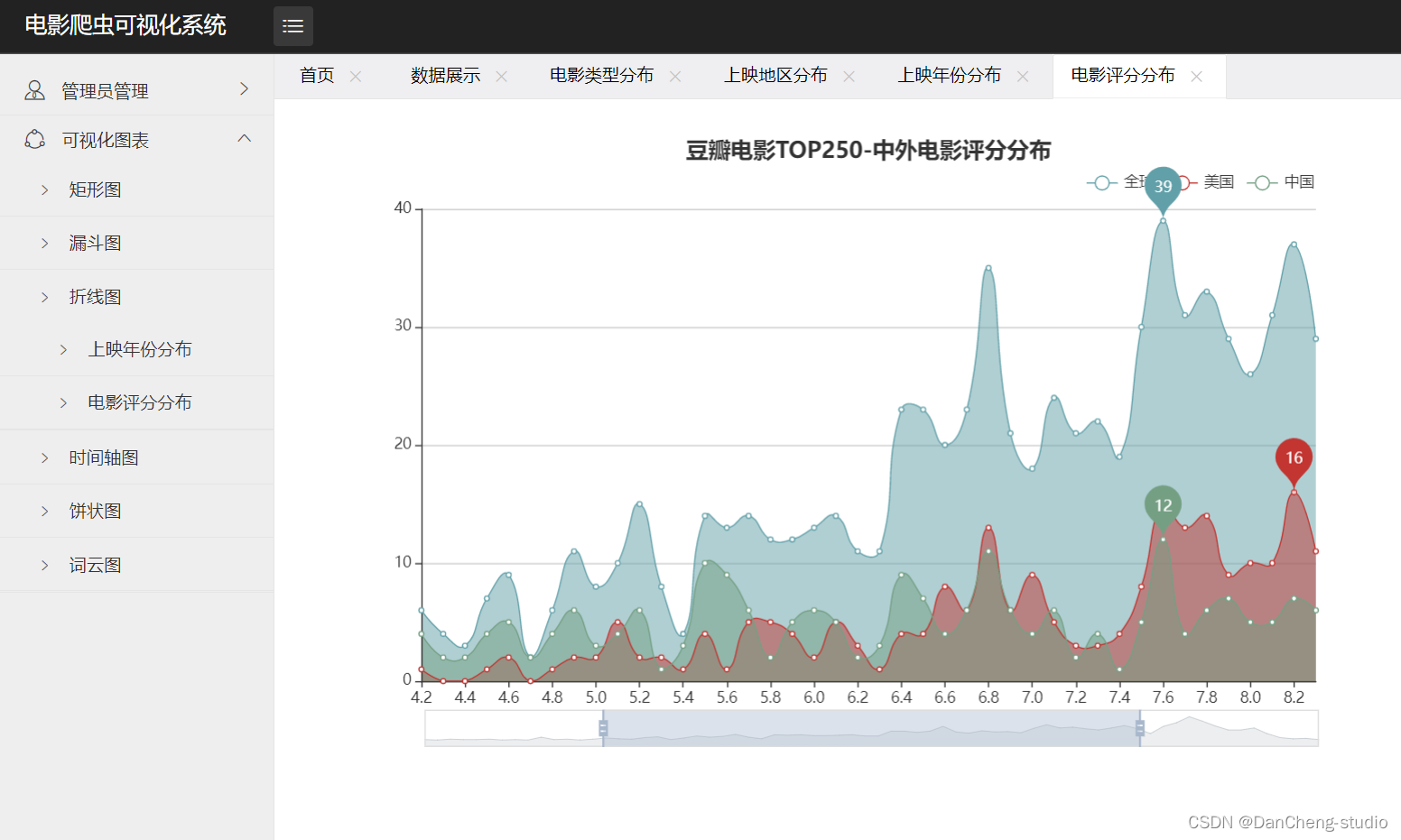
- 上映年份分布、电影评分分布图。
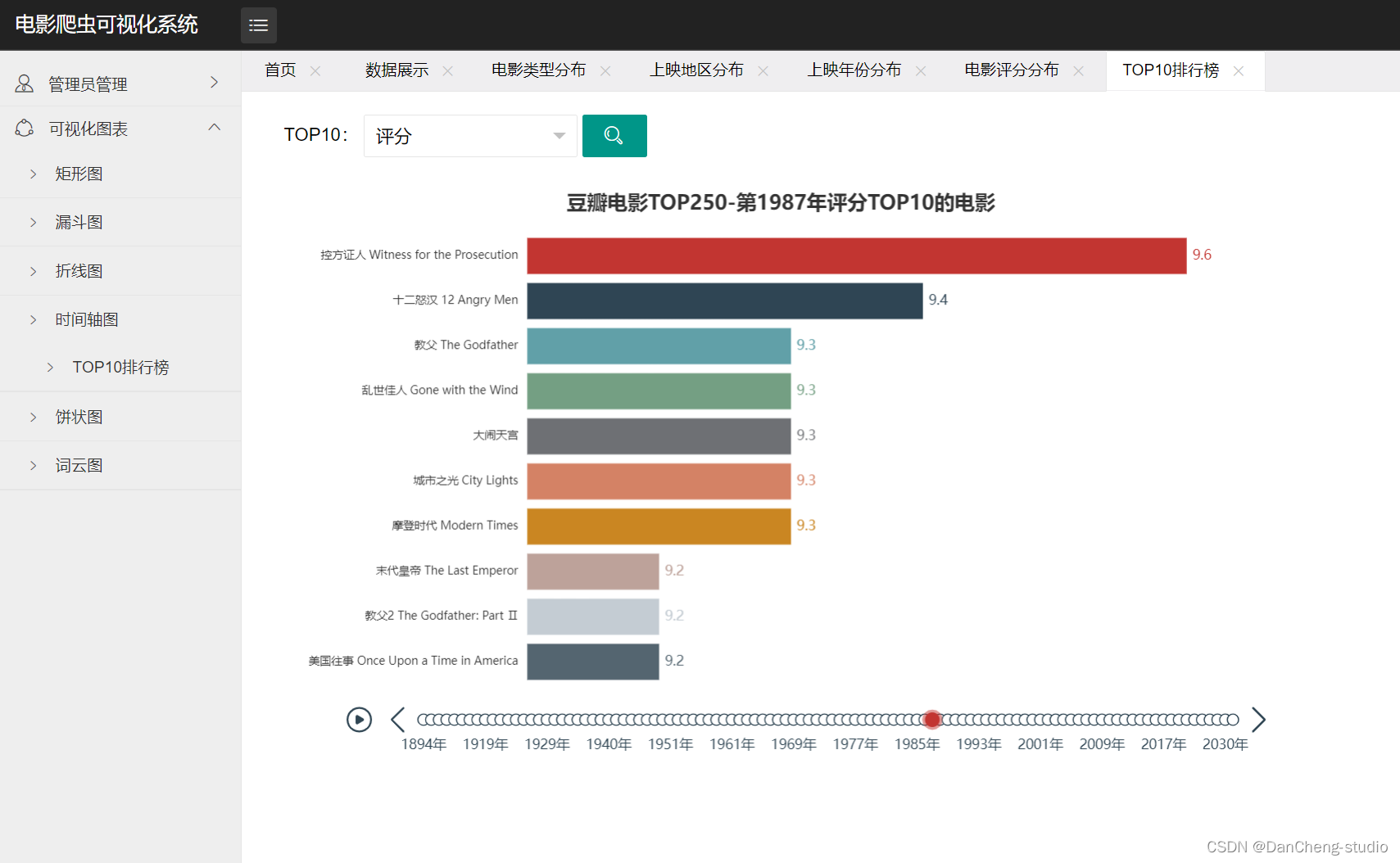
- 时间轴图:可随年份动态变化效果。
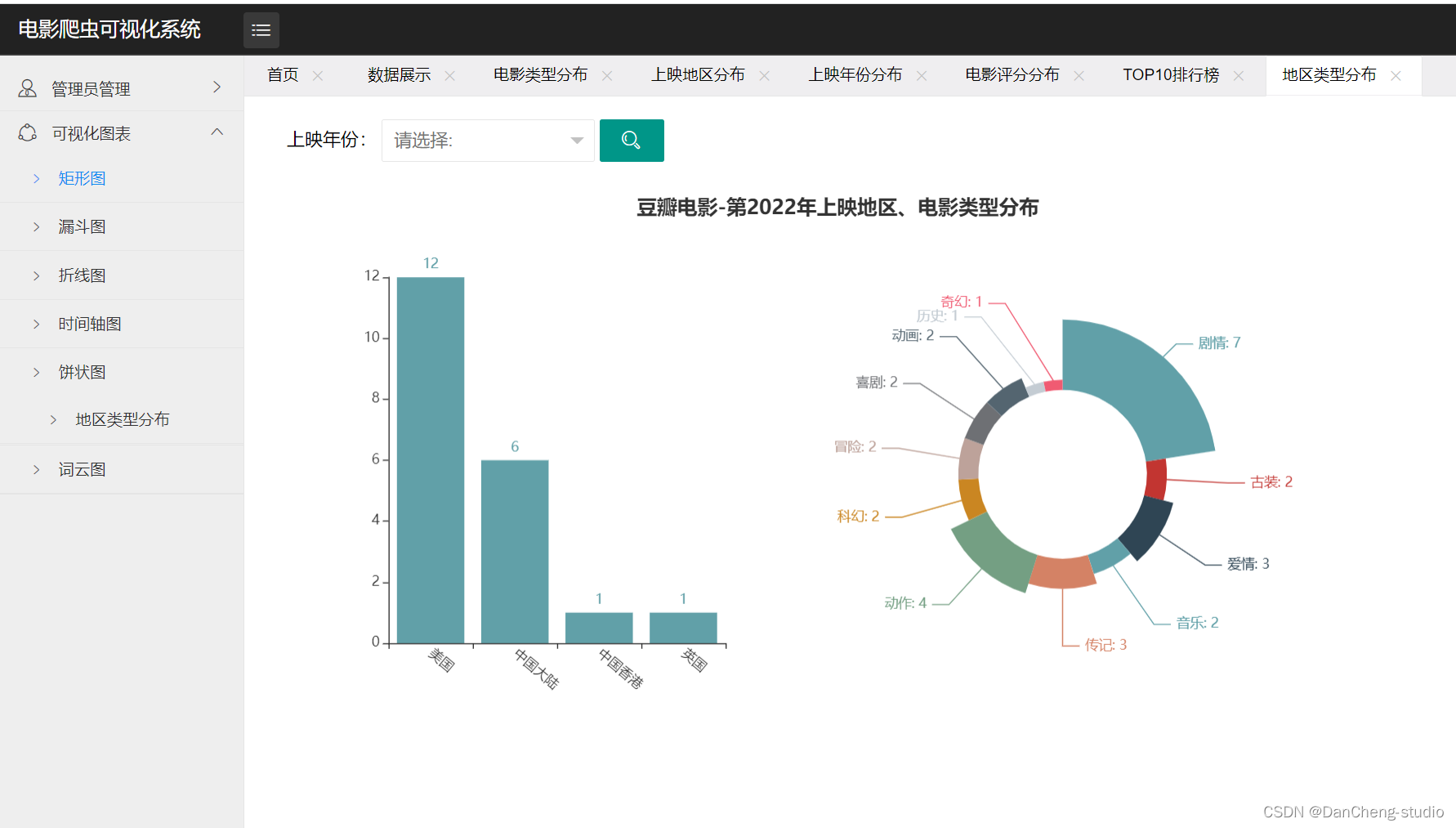
- 地区类型分布饼状图
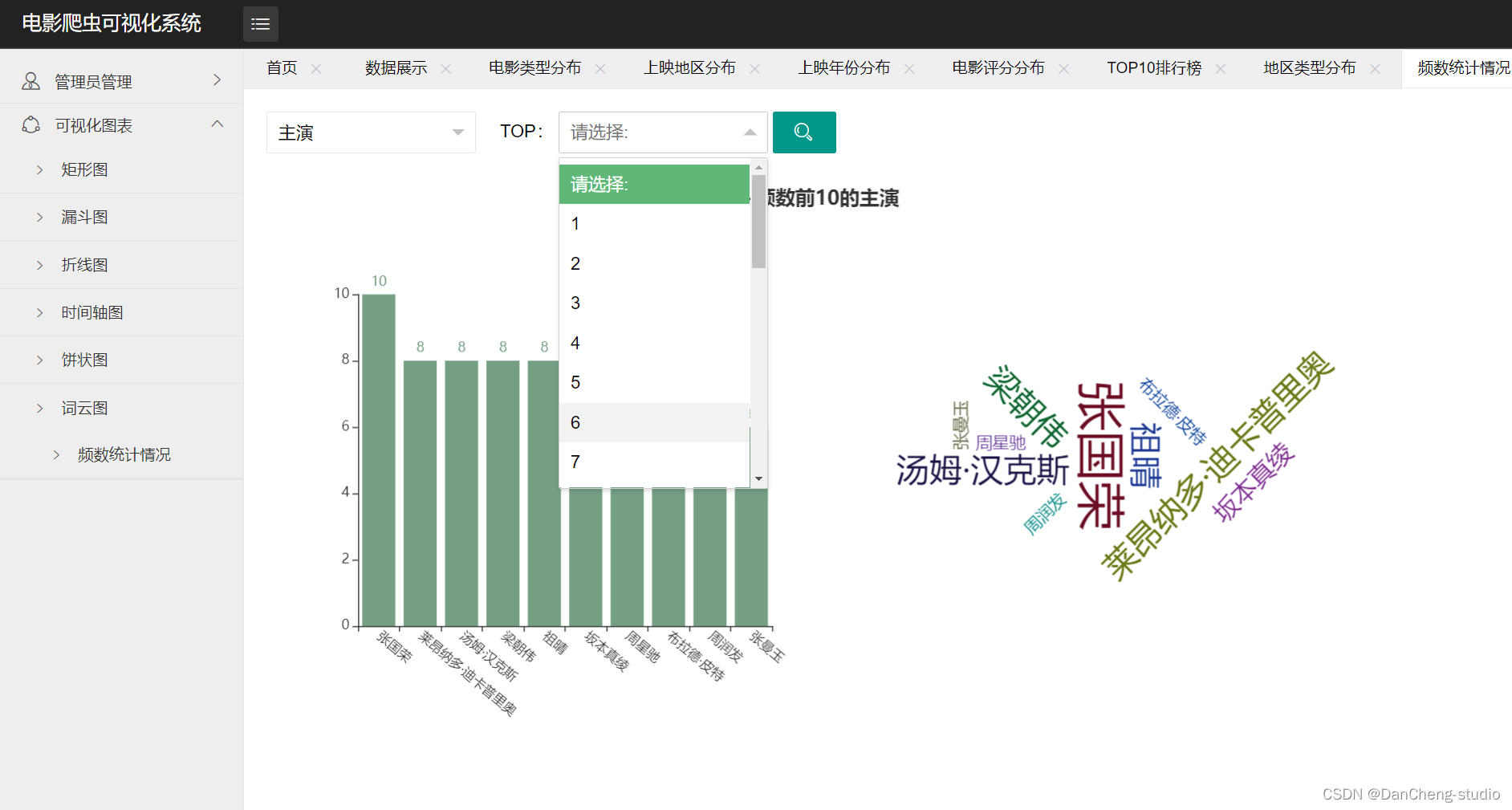
- 频数统计词云图:可根据主演、导演、编剧和电影排名生成相应的词云图
3 数据爬取
3.1 Requests
requests是Python用于网络请求的第三库,也是爬虫获取网络数据的重要工具,使用的时候需要导入
本项目中相关代码:
import requests
from bs4 import BeautifulSoup
from lxml import html
etree = html.etree
import csv
# 请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
}
hrefs = []
# 爬取豆瓣电影TOP250的url
# 获取电影详情页url
def get_film_url(url):
try:
r = requests.get(url, headers=headers)
selector = etree.HTML(r.text)
movie_hrefs = selector.xpath('//div[@class="hd"]/a/@href') # 电影的详情地址
for i in range(0, len(movie_hrefs)):
hrefs.append(movie_hrefs[i])
except Exception as e:
print(e)
# 保存电影链接url
def save_url():
try:
# 获取链接
for href in hrefs:
# 存入csv
file_path = "./豆瓣电影TOP250链接.csv"
with open(file_path, "a+", newline='', encoding='gb18030') as csvfile:
writer = csv.writer(csvfile)
writer.writerow([href])
except Exception as e:
print(e)
def main():
# 爬取豆瓣电影TOP250的url
for i in range(0, 250, 25):
url = "https://movie.douban.com/top250?start=" + str(i) + ""
get_film_url(url)
save_url()
if __name__ == '__main__':
main()
3.2 bs4
bs4即BeautifulSoup,是python种的一个库,最主要的内容就是从网页中抓取数据。
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
3.3 MySQL数据库
利用Pymysql,将爬取到的数据存入数据库中,相关代码如下:
# 打开数据库连接
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123456', db='douban', charset='utf8')
# 使用cursor方法创建一个游标
cursor = conn.cursor()
# # 执行sql语句
# query = 'insert into tb_film(url, filmname, score, showtime, genres, areas, mins, directors, scriptwriters, actors, comments) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)'
query = 'insert into tb_film(url, filmname, score, showtime, genres, areas, directors, scriptwriters, actors, comments) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)'
values = (
url, filmname, score, showtime, genres_list, area_list, directors_list, scriptwriters_list,
actors_list,
comment)
cursor.execute(query, values)
# 提交之前的操作,如果之前已经执行多次的execute,那么就都进行提交
conn.commit()
4 可视化技术
4.1 Flask
Flask是一个基于Werkzeug和Jinja2的轻量级Web应用程序框架。与其他同类型框架相比,Flask的灵活性、轻便性和安全性更高,而且容易上手,它可以与MVC模式很好地结合进行开发。Flask也有强大的定制性,开发者可以依据实际需要增加相应的功能,在实现丰富的功能和扩展的同时能够保证核心功能的简单。Flask丰富的插件库能够让用户实现网站定制的个性化,从而开发出功能强大的网站。
本项目在Flask开发后端时,前端请求会遇到跨域的问题,解决该问题有修改数据类型为jsonp,采用GET方法,或者在Flask端加上响应头等方式,在此使用安装Flask-CORS库的方式解决跨域问题。此外需要安装请求库axios。
部分相关代码:
from flask import Flask
from flask import request, redirect
from flask import render_template, url_for
from flask_paginate import Pagination
from sqlalchemy import create_engine,Column,Integer,SmallInteger,String
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_base
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy()
from list_data import select_score, select_showtime, select_genres, select_areas, film_data
from genres import show_genres
from areas import show_areas
from showtime import show_showtime
from score import show_score
from timeline_score import show_score_top
from timeline_comment import show_comment_top
from select_showtime import select_showtime
from select_showtime import showtime_group
from film_search import film_search
app = Flask(__name__)
app.jinja_env.auto_reload = True
app.config['TEMPLATES_AUTO_RELOAD'] = True
#初始化数据库连接
engine = create_engine("mysql+pymysql://root:123456@localhost:3306/douban?charset=utf8",echo = True)
#创建缓存对象
Session =sessionmaker(bind=engine)
session =Session
#声明基类
Base = declarative_base()
#定义Film对象
#基于这个基类来创建我们的自定义类,一个类就是一个数据库表;
class Film(Base):
#表的名字
__tablename__= 'tb_film'
#表的结构
id = Column(Integer,primary_key=True,autoincrement=True)
url =Column(String(250))
filmname =Column(String(50))
score =Column(String)
comments =Column(Integer)
showtime =Column(Integer)
genres =Column(String(20))
areas =Column(String(20))
actors =Column(String(50))
directors =Column(String(50))
scriptwriters =Column(String(50))
@app.route('/')
def index():
# return render_template('pages/echarts/e1.html')
# return render_template('index.html')
return render_template('login.html')
@app.route('/register')
def register():
# return render_template('pages/echarts/e1.html')
# return render_template('index.html')
return render_template('register.html')
@app.route('/index')
def welcom2index():
# return render_template('pages/echarts/e1.html')
return render_template('index.html')
# return render_template('login.html')
@app.route('/welcome')
def welcome():
print('done')
return render_template('pages/welcome.html')
@app.route("/page_none")
def page_none():
return render_template('page_none')
# 验证用户名和密码
@app.route('/login', methods=['POST'])
#@app.route('/index')
def login():
print(request.form['username'])
# 需要从request对象读取表单内容:
if request.form['username'] == 'admin' and request.form['password'] == '123456':
return render_template('index.html')
# 表单list
@app.route("/list")
@app.route("/list/")
def list(limit=10):
# 列表属性
t_low = select_score()[0]
t_high = select_score()[1]
t_showtime = select_showtime()
t_genres = select_genres()
t_areas = select_areas()
# 分页
# limit = 15
page = int(request.args.get("page", 1))
start = (page - 1) * limit
if request.args.get("low") or request.args.get("high") or request.args.get("showtime") or request.args.get("areas") or request.args.get("genres") or request.args.get("filmname"):
# 参数选择
r_low = request.args.get("low")
r_high = request.args.get("high")
r_showtime = request.args.get("showtime")
r_genres = request.args.get("genres")
r_areas = request.args.get("areas")
r_filmname = request.args.get("filmname")
# 返回数据
print("参数:{},{},{},{},{}".format(r_low, r_high, r_showtime, r_genres, r_areas,r_filmname))
print("参数1:{}".format(type(r_low)))
print("参数2:{}".format(len(r_low)))
r_films = film_data(low=r_low, high=r_high, showtime=r_showtime, genres=r_genres, areas=r_areas, filmname=r_filmname)[0]
r_row = film_data(low=r_low, high=r_high, showtime=r_showtime, genres=r_genres, areas=r_areas, filmname=r_filmname)[1]
# 分页
r_end = page * limit if r_row > page * limit else r_row
r_paginate = Pagination(page=page, total=r_row)
r_ret = r_films[start:r_end]
return render_template('pages/order/list.html', low=t_low, high=t_high, showtime=t_showtime, genres=t_genres,
areas=t_areas, films=r_ret, row=r_row,paginate=r_paginate)
else:
# 返回数据
films = film_data()[0]
row = film_data()[1]
end = page * limit if row > page * limit else row
paginate = Pagination(page=page, total=row)
ret=films[start:end]
print("res:{}".format(ret))
return render_template('pages/order/list.html', low=t_low, high=t_high, showtime=t_showtime, genres=t_genres,
areas=t_areas, films=ret,row=row, paginate=paginate)
4.2 ECharts
ECharts(Enterprise Charts)是百度开源的数据可视化工具,底层依赖轻量级Canvas库ZRender。兼容了几乎全部常用浏览器的特点,使它可广泛用于PC客户端和手机客户端。ECharts能辅助开发者整合用户数据,创新性的完成个性化设置可视化图表。支持折线图(区域图)、柱状图(条状图)、散点图(气泡图)、K线图、饼图(环形图)等,通过导入 js 库在 Java Web 项目上运行。
数据预览
import pandas as pd
import json
# =============================================加载数据===================================
# 加载数据 --credits
credits = pd.read_csv('./tmdb_5000_credits.csv')
print('credits:\n', credits)
print('*' * 100)
print('credits:\n', credits.columns)
print('*' * 100)
print('credits:\n', credits.info())
print('*' * 100)
# 加载数据
movies = pd.read_csv('./tmdb_5000_movies.csv')
print('movies:\n', movies)
print('#' * 100)
print('movies:\n', movies.columns)
print('#' * 100)
print('movies:\n', movies.info())
print('#' * 100)
合并数据集
先将 credits 数据集和 movie 数据集中的数据合并在一起,再查看合并后的数据集信息
代码实现:
# (1)合并数据
# print(credits['crew'])
# credits 中存在 movie_id 和 title
# movies 中存在 id 和 title
# 将 credits 中的 movie_id 修改为 id
credits.rename(columns={'movie_id': 'id'}, inplace=True)
# print('credits的列索引:\n', credits.columns)
# 主键合并 ---on id 和 title
all_data = pd.merge(left=credits, right=movies, on=['id', 'title'], how='outer')
print('all_data:\n', all_data)
print('all_data:\n', all_data.columns)
print('all_data:\n', all_data.dtypes)
选取子集
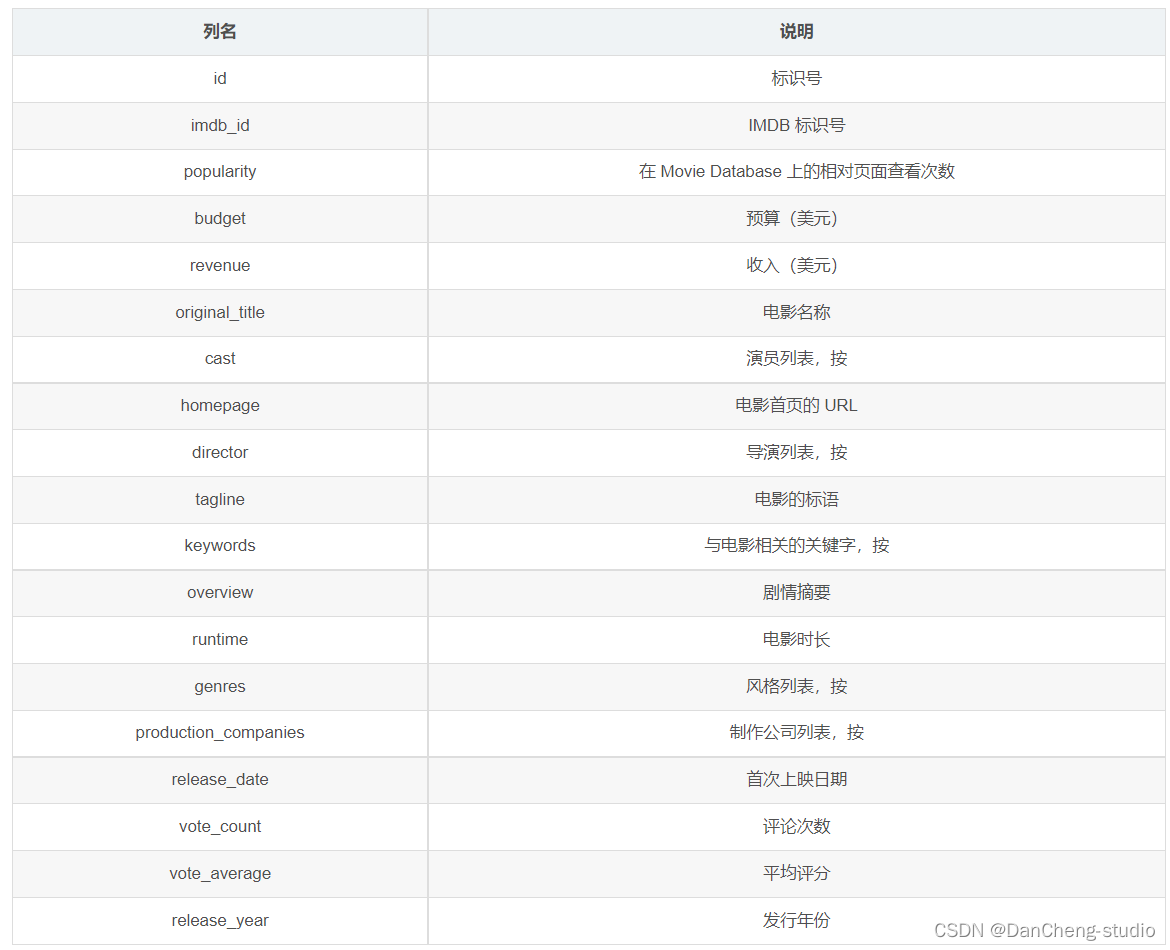
由于数据集中包含的信息过多,其中部分数据并不是我们研究的重点,所以从中选取我 们需要的数据:
代码实现:
# 筛选特征
all_data = all_data['original_title', 'crew', 'release_date', 'genres', 'keywords',
'production_companies', 'production_countries', 'revenue',
'budget', 'runtime', 'vote_average']
print('all_data的列索引:\n', all_data.columns)
print('all_data的形状:\n', all_data.shape)
由于后面的数据分析涉及到电影类型的利润计算,先求出每部电影的利润,并在数据集 data 中增加 profit 数据列
代码实现:
# 增加利润
all_data['profit'] = all_data['revenue'] - all_data['budget']
print('all_data的列索引:\n', all_data)
print('all_data的形状:\n', all_data)
缺失值处理
代码实现:
# 检测缺失值
# pd.isnull + sum
res_null = pd.isnull(all_data).sum()
print('缺失值检测结果:\n', res_null)
# 检测到 release_date 存在一个缺失值 ---针对方式:填充,查找具体的电影名称,根据电影名称查找上映时间
# a、确定bool数组
mask = all_data.loc[:, 'release_date'].isnull()
# b、根据bool数组来获取缺失值位置的电影名称
movie_name = all_data.loc[mask, 'title']
print('缺失上映日期的电影名称为:\n', movie_name)
# 缺失上映日期的电影名称为:
# 4553 America Is Still the Place
# Name: title, dtype: object
# 通过上网查询该电影的上映日期为:2014-06-01
# c 、 填充
all_data.loc[mask, 'release_date'] = '2014-06-01'
# 将 release_date 转化为 pandas支持的时间序列
all_data.loc[:, 'release_date'] = pd.to_datetime(all_data.loc[:, 'release_date'])
# 获取 发行年份
all_data.loc[:, 'release_year'] = all_data.loc[:, 'release_date'].dt.year
通过上面的结果信息可以知道:整个数据集缺失的数据比较少。 其中 release_date(首次上映日期)缺失 1 个数据,可以通过网上查询补齐这个数据,填补 release_date(首次上映日期)数据
数据格式转换
genres 列数据处理:
代码实现:
# 查看电影风格数据
print('电影风格:\n', all_data.loc[:, 'genres']) # json数据类型
# json.loads # 可以将json转化为python类型
# 将 all_data.loc[:, 'genres'] 由 json类型转化为 python类型
all_data.loc[:, 'genres'] = all_data.loc[:, 'genres'].transform(json.loads)
# 构建所有的电影的类型
all_movie_type = set()
# 定义一个函数,来提取电影类型
def get_movie_type(val):
"""
获取电影类型
:param val: 数据
:return: 提取之后的电影类型数据
"""
# 构建一个空列表,用来存储每一个电影的电影类型
type_list = []
# 遍历 列表
for item in val:
# 如果item存在
if item:
# 获取该电影的电影类型
movie_type = item['name']
# 将其加入到 type_list
type_list.append(movie_type)
# 将其加入到 all_movie_type
all_movie_type.add(movie_type)
return ','.join(type_list)
# 调用
all_data.loc[:, 'genres'] = all_data.loc[:, 'genres'].transform(get_movie_type)
print('获取电影类型之后的结果:\n', all_data.loc[:, 'genres'])
# 将所有的电影类型转化为 list
all_movie_type = list(all_movie_type)
# 遍历
for column in all_movie_type:
# 先增加
all_data.loc[:, column] = 0
# 构建bool数组
mask = all_data.loc[:, 'genres'].str.contains(column)
# 修改
all_data.loc[mask, column] = 1
print('all_data:\n', all_data)
数据可视化
绘制电影数据类型随时间变化趋势图
import matplotlib.pyplot as plt
# 创建画布
plt.figure()
# 默认不支持中文 ---修改RC参数
plt.rcParams['font.sans-serif'] = 'SimHei'
# 增加字体之后变得不支持负号,需要修改RC参数让其继续支持负号
plt.rcParams['axes.unicode_minus'] = False
# 构建横轴数据
x = groupby_year.index
for movie_type in groupby_year.columns:
# 构建纵轴数据
y = groupby_year[movie_type]
# 绘制折线图
plt.plot(x, y)
# 增加标题
plt.title('电影数据类型随时间变化趋势图')
# 设置图例
plt.legend(groupby_year.columns, fontsize='x-small')
# 设置纵轴名称
plt.ylabel('数量')
# 设置横轴名称
plt.xlabel('年份')
# 增加网络曲线
plt.grid(b=True, alpha=0.2)
# 保存图片
plt.savefig('./电影数据类型随时间变化')
# 展示
plt.show()
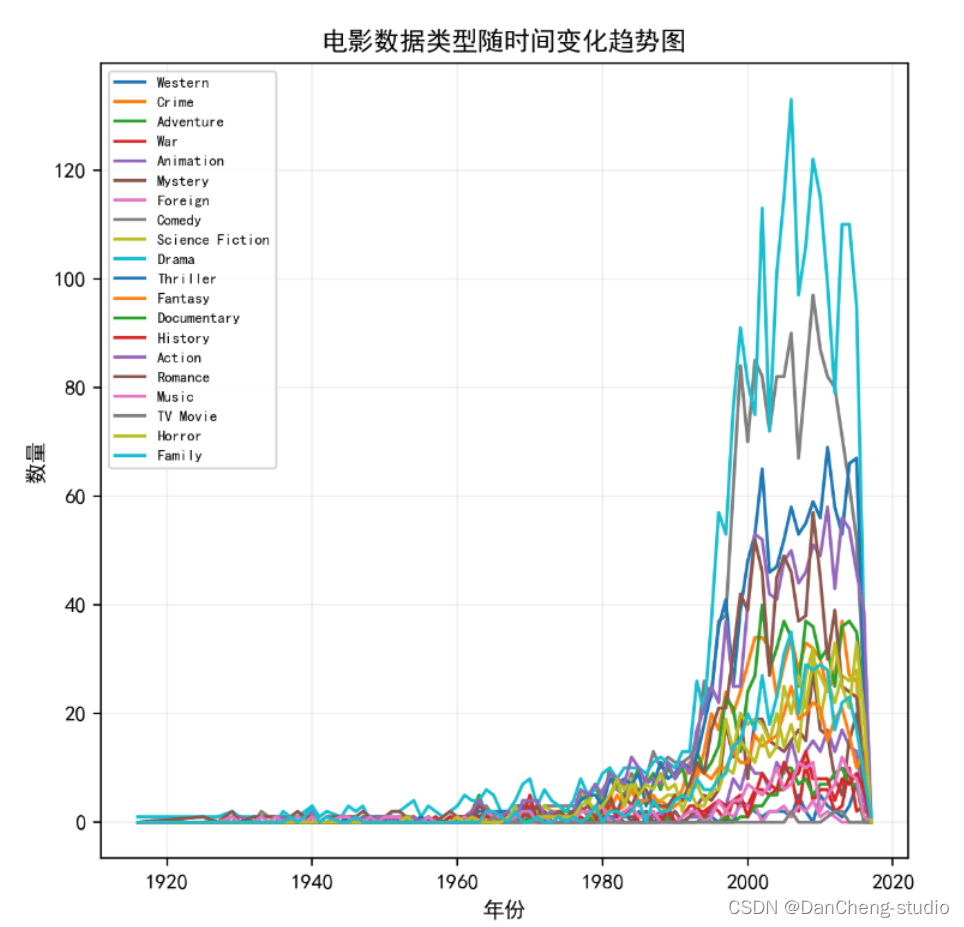
分析结论: 从图中观察到,随着时间的推移,所有电影类型都呈现出增长趋势,尤其是 1992 年以 后各个类型的电影均增长迅速,其中 Drama(戏剧)和 Comedy(喜剧)增长最快,目前仍是最热 门的电影类型
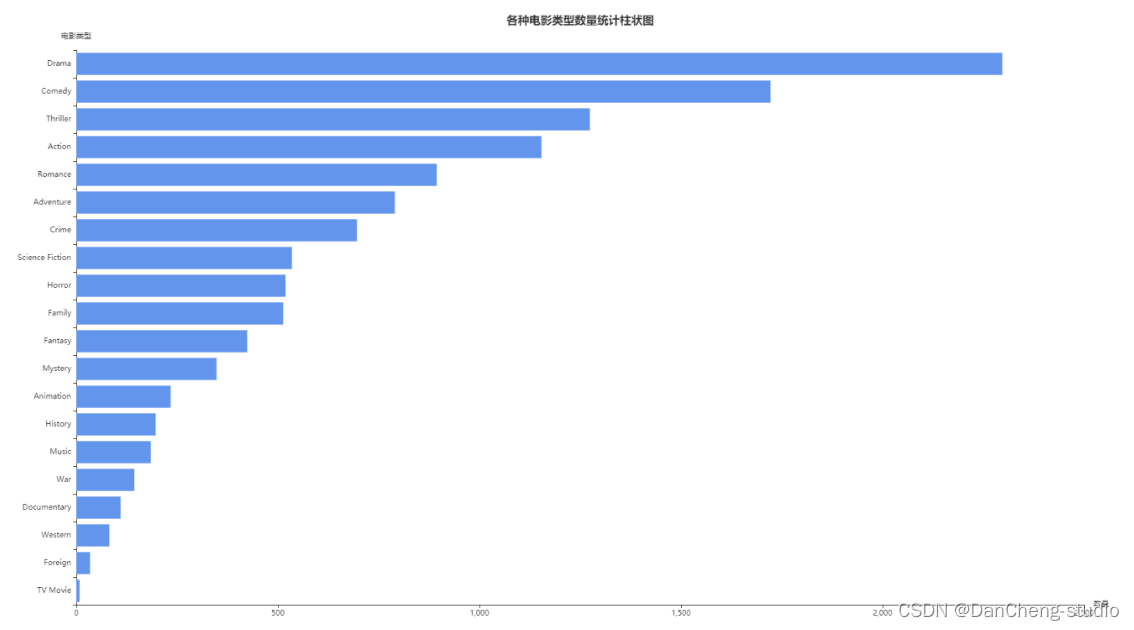
绘制各种类型电影数量的统计柱状图
绘制各种电影类型的占比饼图
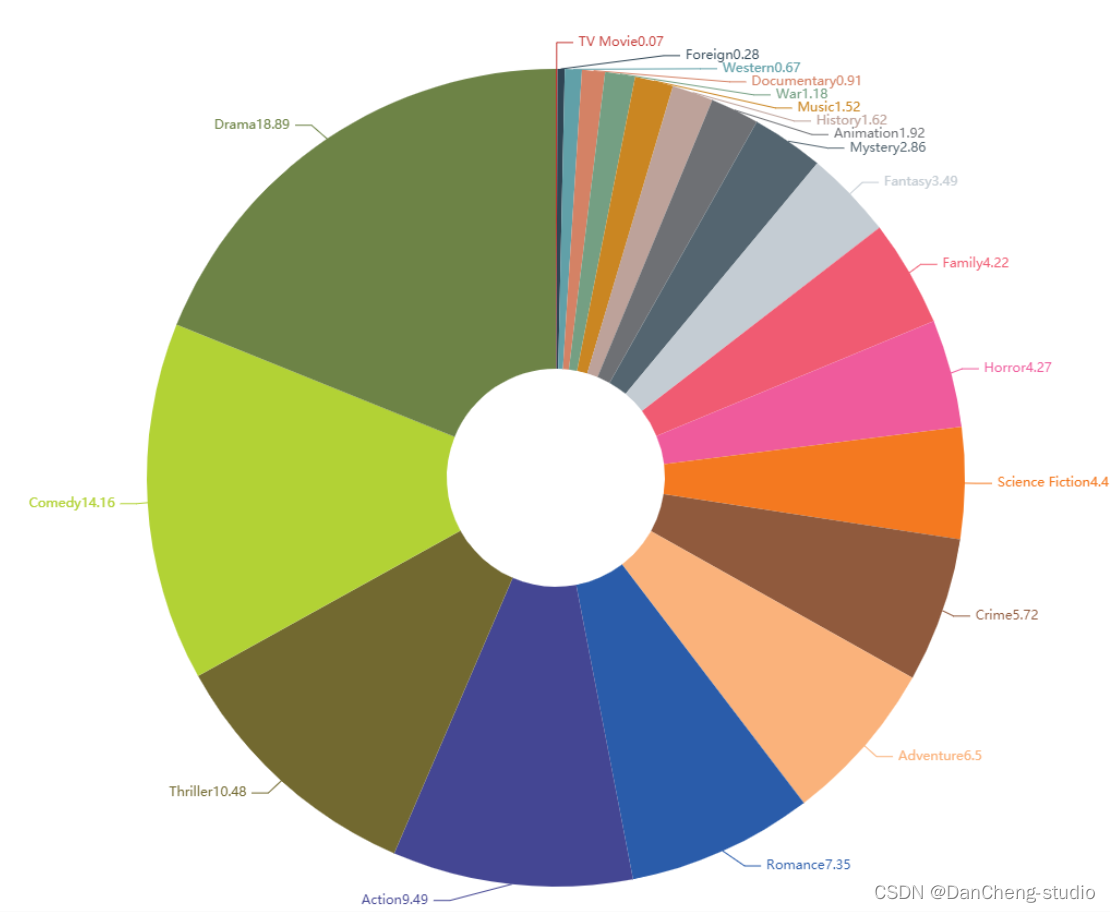
电影类型平均利润数据可视化
# 可视化 ---比 各种电影类型 的 平均利润 ---柱状图
# Pyecharts
# 实例化对象
bar = Bar(
# 初始化配置
init_opts=opts.InitOpts(
width='900px',
height='600px',
theme="white"
)
)
# 添加数据
bar.add_xaxis(
xaxis_data=res_series.index.tolist()
)
bar.add_yaxis(
series_name=' ',
yaxis_data=[float('%.2f' % i) for i in (res_series / 1000000)],
color='#6495ED'
)
# 设置全局配置
bar.set_global_opts(
# 标题
title_opts=opts.TitleOpts(
title='各种电影类型利润统计柱状图',
# subtitle='广州分校Python0421班级'
pos_left='center',
pos_top='3%'
),
# 图例
legend_opts=opts.LegendOpts(
is_show=False,
),
# 横轴坐标设置
xaxis_opts=opts.AxisOpts(
name='利润(百万)'
),
# # 坐标系设置
yaxis_opts=opts.AxisOpts(
name='电影类型'
)
)
# 设置系列配置
bar.set_series_opts(
label_opts=opts.LabelOpts(
is_show=True,
position='right',
color='#000000',
formatter='{c}'
)
)
# 反转坐标轴
bar.reversal_axis()
# 生成文件
bar.render('./各种电影类型利润统计柱状图.html')
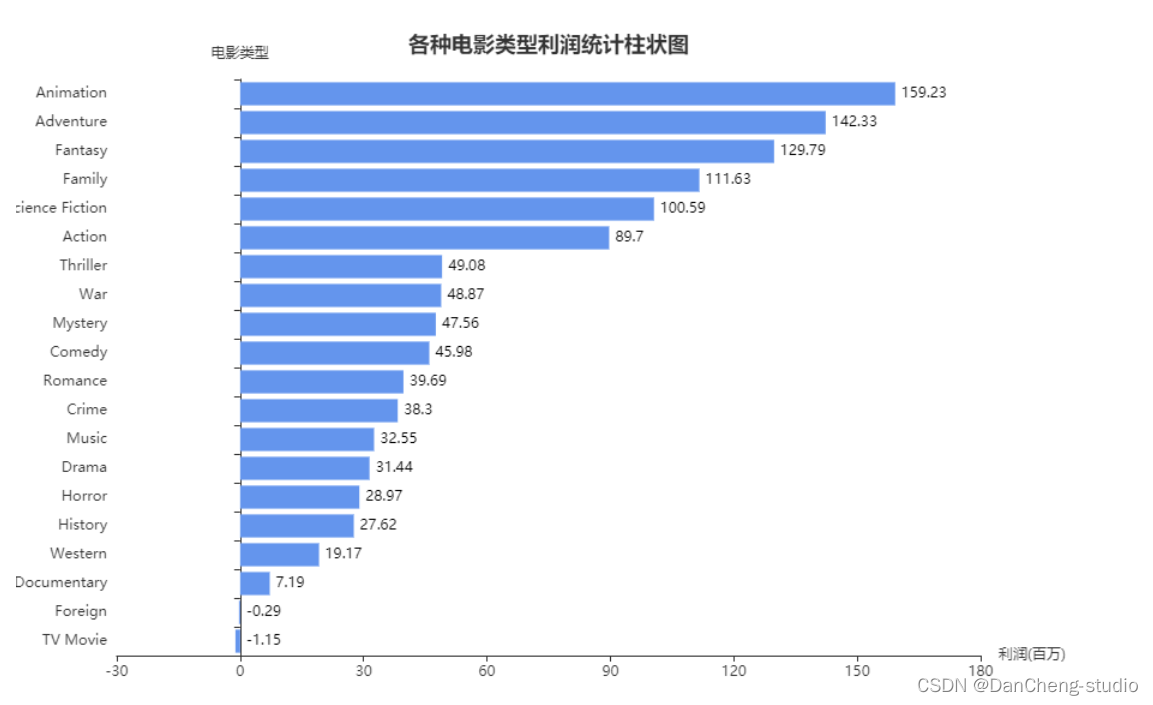
分析结论:
从图中观察到,拍摄 Animation、Adventure、Fantasy 这三类电影盈利最好,而拍摄 Foreign、TV Movie 这两类电影会存在亏本的风险
未完待续。。。。。。
补充:不做成web系统
** 数据预览**
import pandas as pd
import json
# =============================================加载数据===================================
# 加载数据 --credits
credits = pd.read_csv('./tmdb_5000_credits.csv')
print('credits:\n', credits)
print('*' * 100)
print('credits:\n', credits.columns)
print('*' * 100)
print('credits:\n', credits.info())
print('*' * 100)
# 加载数据
movies = pd.read_csv('./tmdb_5000_movies.csv')
print('movies:\n', movies)
print('#' * 100)
print('movies:\n', movies.columns)
print('#' * 100)
print('movies:\n', movies.info())
print('#' * 100)
合并数据集
先将 credits 数据集和 movie 数据集中的数据合并在一起,再查看合并后的数据集信息
代码实现:
# (1)合并数据
# print(credits['crew'])
# credits 中存在 movie_id 和 title
# movies 中存在 id 和 title
# 将 credits 中的 movie_id 修改为 id
credits.rename(columns={'movie_id': 'id'}, inplace=True)
# print('credits的列索引:\n', credits.columns)
# 主键合并 ---on id 和 title
all_data = pd.merge(left=credits, right=movies, on=['id', 'title'], how='outer')
print('all_data:\n', all_data)
print('all_data:\n', all_data.columns)
print('all_data:\n', all_data.dtypes)
选取子集
由于数据集中包含的信息过多,其中部分数据并不是我们研究的重点,所以从中选取我 们需要的数据:
代码实现:
# 筛选特征
all_data = all_data['original_title', 'crew', 'release_date', 'genres', 'keywords',
'production_companies', 'production_countries', 'revenue',
'budget', 'runtime', 'vote_average']
print('all_data的列索引:\n', all_data.columns)
print('all_data的形状:\n', all_data.shape)
由于后面的数据分析涉及到电影类型的利润计算,先求出每部电影的利润,并在数据集 data 中增加 profit 数据列
代码实现:
# 增加利润
all_data['profit'] = all_data['revenue'] - all_data['budget']
print('all_data的列索引:\n', all_data)
print('all_data的形状:\n', all_data)
缺失值处理
代码实现:
# 检测缺失值
# pd.isnull + sum
res_null = pd.isnull(all_data).sum()
print('缺失值检测结果:\n', res_null)
# 检测到 release_date 存在一个缺失值 ---针对方式:填充,查找具体的电影名称,根据电影名称查找上映时间
# a、确定bool数组
mask = all_data.loc[:, 'release_date'].isnull()
# b、根据bool数组来获取缺失值位置的电影名称
movie_name = all_data.loc[mask, 'title']
print('缺失上映日期的电影名称为:\n', movie_name)
# 缺失上映日期的电影名称为:
# 4553 America Is Still the Place
# Name: title, dtype: object
# 通过上网查询该电影的上映日期为:2014-06-01
# c 、 填充
all_data.loc[mask, 'release_date'] = '2014-06-01'
# 将 release_date 转化为 pandas支持的时间序列
all_data.loc[:, 'release_date'] = pd.to_datetime(all_data.loc[:, 'release_date'])
# 获取 发行年份
all_data.loc[:, 'release_year'] = all_data.loc[:, 'release_date'].dt.year
通过上面的结果信息可以知道:整个数据集缺失的数据比较少。 其中 release_date(首次上映日期)缺失 1 个数据,可以通过网上查询补齐这个数据,填补 release_date(首次上映日期)数据
数据格式转换
genres 列数据处理:
代码实现:
# 查看电影风格数据
print('电影风格:\n', all_data.loc[:, 'genres']) # json数据类型
# json.loads # 可以将json转化为python类型
# 将 all_data.loc[:, 'genres'] 由 json类型转化为 python类型
all_data.loc[:, 'genres'] = all_data.loc[:, 'genres'].transform(json.loads)
# 构建所有的电影的类型
all_movie_type = set()
# 定义一个函数,来提取电影类型
def get_movie_type(val):
"""
获取电影类型
:param val: 数据
:return: 提取之后的电影类型数据
"""
# 构建一个空列表,用来存储每一个电影的电影类型
type_list = []
# 遍历 列表
for item in val:
# 如果item存在
if item:
# 获取该电影的电影类型
movie_type = item['name']
# 将其加入到 type_list
type_list.append(movie_type)
# 将其加入到 all_movie_type
all_movie_type.add(movie_type)
return ','.join(type_list)
# 调用
all_data.loc[:, 'genres'] = all_data.loc[:, 'genres'].transform(get_movie_type)
print('获取电影类型之后的结果:\n', all_data.loc[:, 'genres'])
# 将所有的电影类型转化为 list
all_movie_type = list(all_movie_type)
# 遍历
for column in all_movie_type:
# 先增加
all_data.loc[:, column] = 0
# 构建bool数组
mask = all_data.loc[:, 'genres'].str.contains(column)
# 修改
all_data.loc[mask, column] = 1
print('all_data:\n', all_data)
数据可视化
绘制电影数据类型随时间变化趋势图
import matplotlib.pyplot as plt
# 创建画布
plt.figure()
# 默认不支持中文 ---修改RC参数
plt.rcParams['font.sans-serif'] = 'SimHei'
# 增加字体之后变得不支持负号,需要修改RC参数让其继续支持负号
plt.rcParams['axes.unicode_minus'] = False
# 构建横轴数据
x = groupby_year.index
for movie_type in groupby_year.columns:
# 构建纵轴数据
y = groupby_year[movie_type]
# 绘制折线图
plt.plot(x, y)
# 增加标题
plt.title('电影数据类型随时间变化趋势图')
# 设置图例
plt.legend(groupby_year.columns, fontsize='x-small')
# 设置纵轴名称
plt.ylabel('数量')
# 设置横轴名称
plt.xlabel('年份')
# 增加网络曲线
plt.grid(b=True, alpha=0.2)
# 保存图片
plt.savefig('./电影数据类型随时间变化')
# 展示
plt.show()
分析结论: 从图中观察到,随着时间的推移,所有电影类型都呈现出增长趋势,尤其是 1992 年以 后各个类型的电影均增长迅速,其中 Drama(戏剧)和 Comedy(喜剧)增长最快,目前仍是最热 门的电影类型
绘制各种类型电影数量的统计柱状图
绘制各种电影类型的占比饼图
电影类型平均利润数据可视化
# 可视化 ---比 各种电影类型 的 平均利润 ---柱状图
# Pyecharts
# 实例化对象
bar = Bar(
# 初始化配置
init_opts=opts.InitOpts(
width='900px',
height='600px',
theme="white"
)
)
# 添加数据
bar.add_xaxis(
xaxis_data=res_series.index.tolist()
)
bar.add_yaxis(
series_name=' ',
yaxis_data=[float('%.2f' % i) for i in (res_series / 1000000)],
color='#6495ED'
)
# 设置全局配置
bar.set_global_opts(
# 标题
title_opts=opts.TitleOpts(
title='各种电影类型利润统计柱状图',
# subtitle='广州分校Python0421班级'
pos_left='center',
pos_top='3%'
),
# 图例
legend_opts=opts.LegendOpts(
is_show=False,
),
# 横轴坐标设置
xaxis_opts=opts.AxisOpts(
name='利润(百万)'
),
# # 坐标系设置
yaxis_opts=opts.AxisOpts(
name='电影类型'
)
)
# 设置系列配置
bar.set_series_opts(
label_opts=opts.LabelOpts(
is_show=True,
position='right',
color='#000000',
formatter='{c}'
)
)
# 反转坐标轴
bar.reversal_axis()
# 生成文件
bar.render('./各种电影类型利润统计柱状图.html')
5 最后
**毕设帮助, 选题指导, 项目分享: ** https://gitee.com/yaa-dc/warehouse-1/blob/master/python/README.md














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









