







 本文介绍了几种常用的数据预处理方法,包括z-score标准化、Min-max标准化等,并通过sklearn库进行了实现。每种方法的特点及适用场景均有说明,还提供了可视化结果以便直观理解。
本文介绍了几种常用的数据预处理方法,包括z-score标准化、Min-max标准化等,并通过sklearn库进行了实现。每种方法的特点及适用场景均有说明,还提供了可视化结果以便直观理解。
1、概述
| 名称 | 计算方法 | 映射到[0,1] | 消除 量纲 | 差距 缩放 | 负数情况 可用? |
|---|---|---|---|---|---|
| min-max标准化 | 新 数 据 = ( 原 数 据 − 最 小 值 ) / ( 最 大 值 − 最 小 值 ) 新数据 = ( 原数据 - 最小值 ) / ( 最大值 - 最小值 ) 新数据=(原数据−最小值)/(最大值−最小值) | ✅ | ✅ | 放大 | ✅ |
| z-score标准化 | 新 数 据 = ( 原 数 据 − 均 值 ) / 标 准 差 新数据 = ( 原数据 - 均值 ) / 标准差 新数据=(原数据−均值)/标准差 | ❌ | ✅ | ✅ | |
| 中位数变零 | 新 数 据 = 原 数 据 − 中 位 数 新数据 = 原数据 - 中位数 新数据=原数据−中位数 | ❌ | ❌ | ✅ | |
| 众数变零 | 新 数 据 = 原 数 据 − 众 数 新数据 = 原数据 - 众数 新数据=原数据−众数 | ❌ | ❌ | ✅ | |
| max标准化 | 新 数 据 = 原 数 据 / 最 大 值 新数据 = 原数据 / 最大值 新数据=原数据/最大值 | ✅ | ✅ | 放大 | ❌ |
| 上限标准化 | 新 数 据 = 原 数 据 / 区 间 上 限 新数据 = 原数据 / 区间上限 新数据=原数据/区间上限 | ✅ | ✅ | 不变 | ❌ |
| 绝对值 | 新 数 据 = 原 数 据 的 绝 对 值 新数据 = 原数据的绝对值 新数据=原数据的绝对值 | ❌ | ❌ | ✅ | |
| 转成单位向量 | 新 数 据 = 原 数 据 / 向 量 的 模 新数据 = 原数据 / 向量的模 新数据=原数据/向量的模 | ✅ | 缩小 | ✅ |
2、sklearn实现
from sklearn.preprocessing import MinMaxScaler, StandardScaler
X = [[0.0, 1, 2],
[0.4, 1, 2],
[0.6, 9, 2],
[0.8, 9, 2]]
print(MinMaxScaler().fit_transform(X))
print(StandardScaler().fit_transform(X))
结果打印
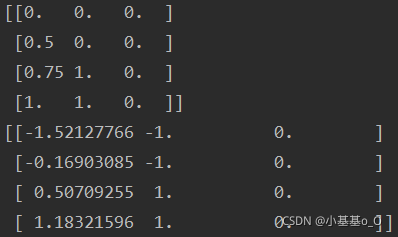
from pandas import DataFrame
def min_max(df: DataFrame, columns: list):
"""
输入DataFrame和需要标准化的列名的列表
返回标准化后的DataFrame
"""
from sklearn.preprocessing import MinMaxScaler
df[columns] = MinMaxScaler().fit_transform(df[columns])
return df
if __name__ == '__main__':
from numpy import nan
_df = DataFrame({
'name': ['A', 'B', 'C', 'D'],
'a': [.0, .4, .6, .8],
'b': [1, 1, nan, 9],
'c': [2, 2, nan, 2],
})
print(_df)
print(min_max(_df, _df.columns[1:]))
结果打印

3、代码+效果
z-score标准化
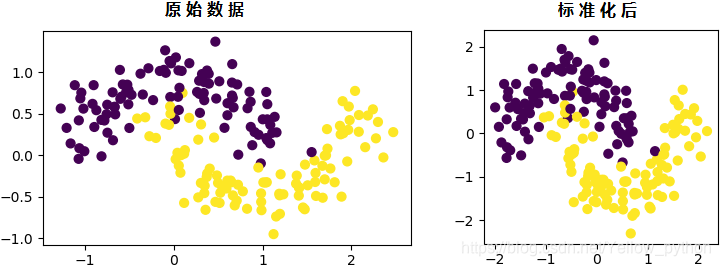
import matplotlib.pyplot as mp
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import make_moons
X, y = make_moons(200, noise=0.20) # 创建随机样本集
X_standard = StandardScaler().fit_transform(X) # z-score 标准化
mp.subplot(1, 2, 1)
mp.scatter(X[:, 0], X[:, 1], s=40, c=y)
mp.subplot(1, 2, 2)
mp.scatter(X_standard[:, 0], X_standard[:, 1], s=40, c=y)
mp.show()
Min-max标准化

import pandas as pd, matplotlib.pyplot as mp
# 造数据
df = pd.DataFrame({'name': list('ABCD'), 'value': [102, 100, 110, 101]})
# 0-1标准化
df['0-1'] = 0 if ((df['value'].max() - df['value'].min()) == 0) else (
(df['value'] - df['value'].min())
/
(df['value'].max() - df['value'].min())
)
# 可视化
mp.figure(num='Title', facecolor='lightgray', figsize=(6, 3))
# 左图:处理前
mp.subplot(1, 2, 1)
mp.title('origin', fontsize=12)
mp.bar(df['name'], df['value'], 0.2, color='dodgerblue', label='value')
mp.legend()
# 右图:【零一标准化】处理后
mp.subplot(1, 2, 2)
mp.title('0-1 standardization', fontsize=12)
mp.bar(df['name'], df['0-1'], 0.2, color='orangered', label='0-1')
mp.legend()
# 展示
mp.tight_layout() # 防止重叠
mp.show()
中位数变0
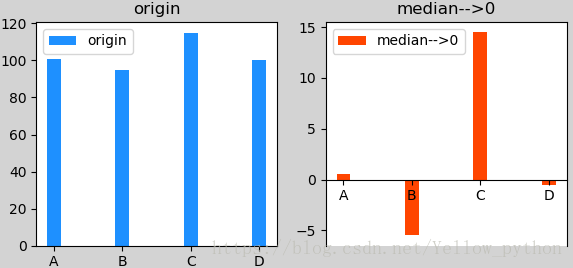
import pandas as pd, matplotlib.pyplot as mp
df = pd.DataFrame({'name': list('ABCD'), 'value': [101, 95, 115, 100]})
# 中位数变0
df['median-->0'] = ((df['value'] - df['value'].median()))
# 可视化
mp.figure(num='Title', facecolor='lightgray', figsize=(6, 3))
# 左图:处理前
mp.subplot(1, 2, 1)
mp.title('origin')
mp.bar(df['name'], df['value'], 0.2, color='dodgerblue', label='origin')
mp.legend()
# 右图:【中位数变0】处理后
mp.subplot(1, 2, 2)
mp.title('median-->0')
ax = mp.gca() # 获取当前坐标轴对象
ax.spines['bottom'].set_position(('data', 0)) # 将底边框置于数据坐标原点
mp.bar(df['name'], df['median-->0'], 0.2, color='orangered', label='median-->0')
mp.legend()
# 展示
mp.tight_layout() # 防止重叠
mp.show()
转单位向量
向量的模
from numpy import linalg # Linear Algebra
a = [3, 4]
linalg.norm(a) # 5.0
linalg.norm(a, ord=1) # 7.0
单位向量
import numpy as np
a = np.array([[2, 2, 2, 2], [3, 4, 0, 0]])
b = np.linalg.norm(a, axis=1).reshape(-1, 1)
c = np.divide(a, b) # a / b
print(b, c, sep='\n')
[[4.]
[5.]]
[[0.5 0.5 0.5 0.5]
[0.6 0.8 0. 0. ]]


















 1332
1332

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











