







本系列文章由 @yhl_leo 出品,转载请注明出处。
文章链接: http://blog.csdn.net/yhl_leo/article/details/51416540
看到之前的一篇博文:深入MNIST code测试,接连有读者发问,关于其中的一些细节问题,这里进行简单的答复。
Tensorflow中提供的示例中MNIST网络结构比较简单,属于浅层的神经网络,只有两个卷积层和全连接层,我按照Caffe的网络结构绘制一个模型流程:
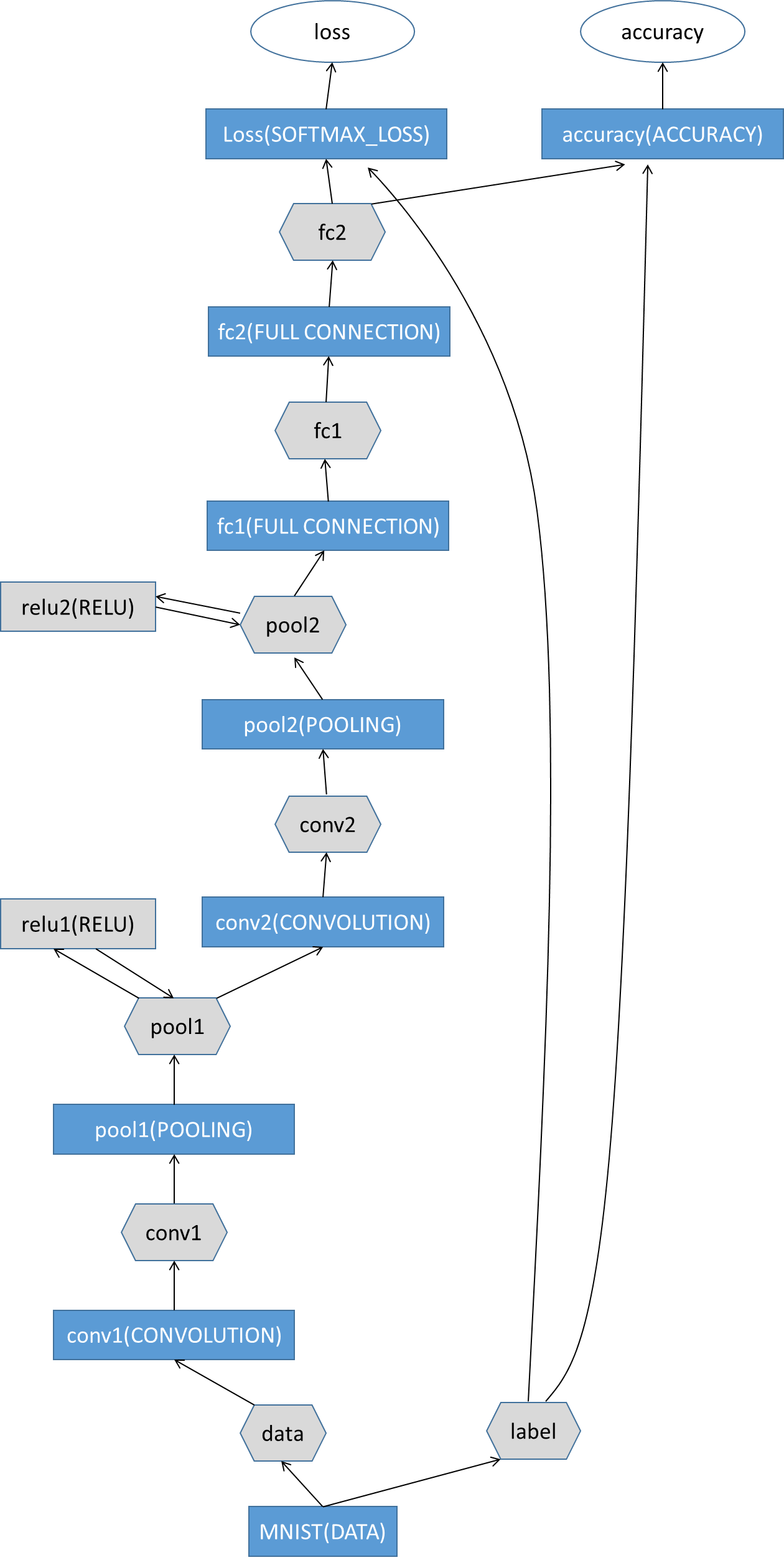
再附上每一层的具体参数网络(依旧仿照caffe的模式):

现在再来解释一些读着的疑问:
在卷积层
conv1和conv2中的32/64是什么,怎么来的?这里它们指的其实就是卷积核的数量,这里卷积核设置参数为[5,5,1,32], strides=[1,1,1,1], padding='SAME',分别解释一下:[5,5,1,32]:卷积核为5x5的窗口,因为输入图像是一通道灰度图像,所以第三参数为1,使用彩色图像时,一般设置为3,最后32就是指卷积核的数量,为什么要使用这么多卷积核呢?我理解的是,每种卷积只对某些特征敏感,获取的特征很有限,因此将多种不同的卷积核分别对图像进行处理,就能获得更多的特征。每个卷积核按照规则扫描完图像后,就输出一张特征图像(feature map),因此32也指输出的特征图。strides=[1,1,1,1]:指卷积窗口的滑动方式,这里是指逐像素滑动。padding='SAME':所谓的padding是为了解决图像边缘部分的像素,很容易想象,当卷积窗口不是一个像素大小时,图像边缘的部分区域是不能覆盖的(或者说卷积窗口覆盖该像素时,部分窗口已经位于图像区域以外了),很简单的做法是先将图像的拓展一下,使得位于边缘区域的像素也能进行卷积。SAME就是一种padding方法,即图像向四周拓展kernel_width/2和kernel_height/2个像素。那么这里输出的特征图像的大小就为:28x28x32。- 同理
[5,5,32,64]可以理解。
关于
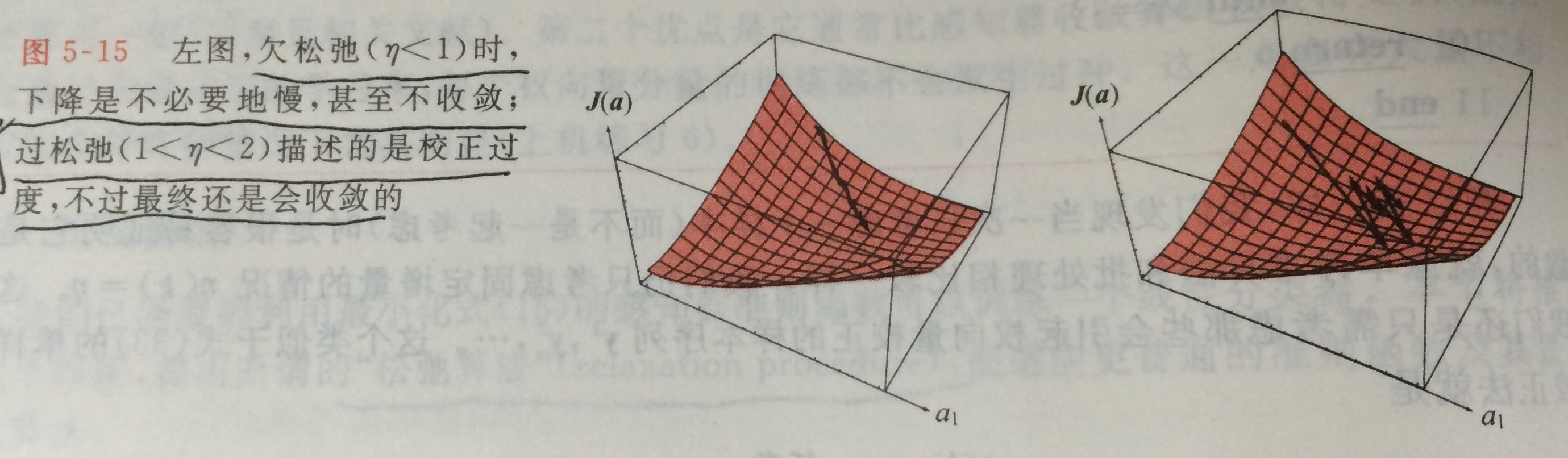
batch大小,我也没有深入了解过,浅显的理解为:训练样本有几万张,如果一起进行结算,其中的矩阵太过庞大,对于计算机来讲非常有压力,所以分批进行,这里的50就是指每一批的训练子数据的大小。至于训练20000次,是否会导致同一个样本的重复训练?答案是绝对的,机器学习中,有bagging,random forests中有提到这方面的知识,想了解的话,可以自己阅读相关论文。关于训练中准确度反复的现象,这是在正常不过的,要真正理解,首先需要自行补习关于梯度下降算法的原理(这里不详细介绍),一般来讲,我们希望优化算法在最少步骤下收敛到理想的结果,但是难点在于如何在每一步优化的过程中提供最优的学习率,简单的做法是给定固定的”学习率“,例如这里设置的学习率是
1e-3,这样做虽然不能保证每一步的优化是最优的,但是从大量的训练测试来看,整体趋势是朝着我们所想要的方向。最后附上一张图:
- 关于dropout,是为了避免神经网络训练过程中由于数据样本的不足,导致的过拟合问题。推荐阅读论文:Dropout: A Simple Way to Prevent Neural Networks from Overfitting
解释的比较简单,有不准确的地方请指正,希望能帮到有疑惑的读者,如有其它疑惑,大家一起探讨。















 468
468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









