







CyCADA方法:通过在多个损失函数上训练模型。总体思路为:特征级+像素级上的对齐+在对齐过程中保留数据中的语义信息(即将数据的类别信息考虑进来)
原理

我们看到训练的模型如上,总的来说,该论文需要在5个损失函数(如下)上训练模型,最终达到迁移学习的目的。
- 分类判别损失Ltask(ft,Gs_t(Xs),Ys)
- 原样本映射的目标样本的对抗损失(像素数级适应)Lgan
- 特征级适应损失Lgan
- 重构的原样本的循环损失Lcyc(Gs_t,Gt_s,Xt,Xs)
- 源图像和转化为目标图像后的语意一致性损失Lsem(Gs_t,Gt_s,Xt,Xs,fs)
而核心问题和其他论文一样,主要是同时学习分类器 f 、生成器 G、以及领域判别器D。
1、首先我们使用生成器Gs_t通过源域样本生成出与目标样本类似的结果,产生目标样本用于愚弄对抗判别器Dt。进行对抗域适应,损失函数如下:
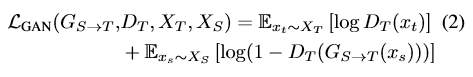
2、而学习一个
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4247
4247











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









