







domain adaptation 域适应技术
该技术主要用于迁移学习(transfer learning)
迁移学习:alphago能够下围棋,并且实践已经证明其具有很强的卫勤能力,但是这种能力能够在象棋上使用吗?人一旦小时候学会了骑自行车,长大后只需简单的学习,就能驾驶摩托车;网球运动员打羽毛球时,再简单的学习后,就能打的比普通人好;拉小提琴的音乐家,尽管专业不是二胡,但是拉起二胡的时候,起码会比普通人拉的好…这些都是迁移学习的例子,及机器具有举一反三的能力。
当某个领域没有足够多的数据的时候,而一个相似的领域已经比较成熟且有大量的数据,如何将这个成熟领域上的学习经验模型转移到数据少的领域,并达到较好的学习效果,便是迁移学习的主要目的,其解决了某个领域学习数据少的问题。
域适应技术(domain adaptation)是迁移学习(transfer learning)的一个子问题
参考链接:https://www.bilibili.com/video/BV1ct41167kV?p=1&vd_source=87fb4d71e6e8b656dcc7d14515f9577e
问题1:既然已经使用mobilenetv2做好了数据的识别,为何还要再做迁移学习域适应呢?每个人所绘制的数据分布不一样吗?
对于草图绘制系统,使用mobilenetv2,首先使用8~15这8个人的数据进行了训练,然后对其余人的所有数据进行识别,测试的结果并不是很理想,准确率基本上全是在90%以下,
在使用域适应的时候,初始网络的训练与mobilenetv2中使用的数据是一样的,但在域适应训练时候,使用的数据是很少的,测试集也仅仅只用了5张数据,CDAN/CDAN+E的无监督/有监督效果较好(测试数据的数据量比mobilenetv2中少很多,与之前mobilenetv2上的测试无法比较,因为没有控制变量)。
直接在8~15的数据上训练的网络,用于测试别人的数据,得到的效果比较差,但是使用别人的5/2/1张数据做了迁移学习域适应后,就会提升对新人数据的准确率,这就证明了迁移学习域适应在本项目中的必要性,同时,解决了新用户数据量少的问题。(缺点:如果让mobilenetv2训练后的网络直接测试5/2/1张数据呢?准确率会不会也变大?或者使用CDAN/CDAN+E测试每个人每个类更多的数据,准确率会不会下降)
研究意义:
对于一些复杂的草图,先设计一种类似的简单图形,然后迁移到对应的复杂图形的识别上,简单图形更容易绘制,不同人绘制的相同类别的识别率有高有低,这就说明不同人绘制的风格是不一样的。
参考链接:https://www.bilibili.com/video/BV1ct41167kV?p=1&vd_source=87fb4d71e6e8b656dcc7d14515f9577e
相关论文:Deep visual Domain Adaptation:a survey
迁移学习
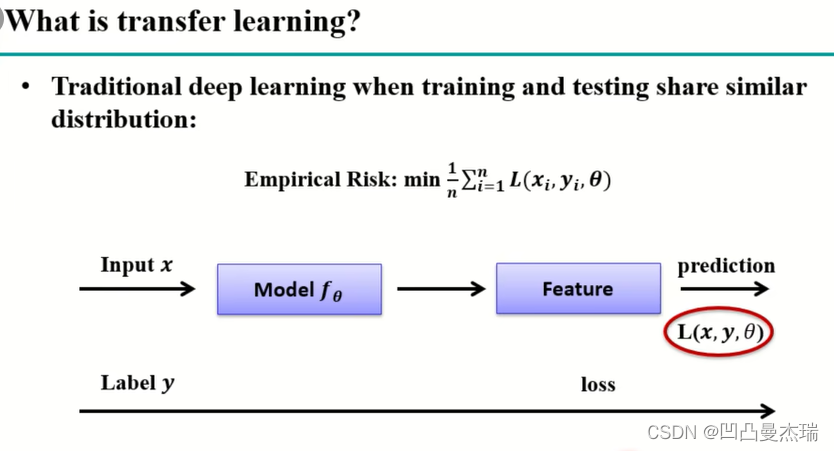
传统的deep learning:数据经过网络的运算,在各种loss的作用下,更改模型参数,模型参数不停的fine-tune(微调),提取数据特征,然后使用test数据测试,直至达到满意。
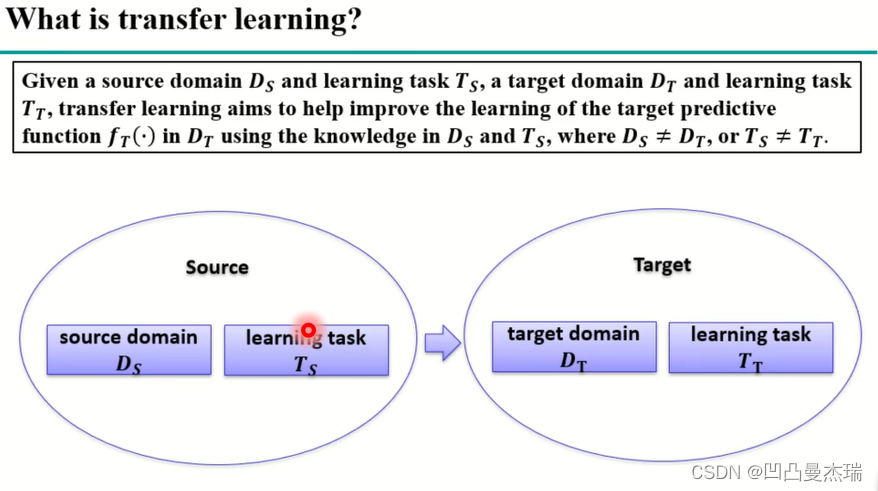
迁移学习中的Source和Target,是迁移学习中的两个域,一个是源域,一个是目标域,一般是不同分布的数据,但是又有一定的相似性,source源域中的数据大部分是对应着训练样本,目标域中的数据大部分是对应着测试样本。
在非深度学习的时候,2010~2012年,yang qiang发表了一篇关于关于迁移学习的综述:A survey on transfer learning.

该综述将对迁移学习提出了三大子问题,其中之一就是domain adaptation,在其所提到的场景中,domain adaptation的数据是不一样的,但是任务是一样的,即要么都是分类,要么都是回归,source domain中有大量标记好的数据,但是target domain中只有少量,或者完全没有标记好的样本(即任务相同,数据不同)。
简要说一下数据分布不同的例子:
参考论文:Deep visual domain adaptation:A survey(2018)

上图中前两行数据分别来自office31和手写数字集MNIST。

上图是将门牌号上的数字迁移到手写数字的识别上,蓝色表示门牌号数据的分布,红色表示手写数据的分布,没有进行域适应的时候,在svhn数据集训练的网络能够很好的划分svhn数据集(蓝色),即能够很好的提取svhn数据的特种,但对于目标域的数据集(红色)却不能很好的划分,域适应之后可以很好的划分,这说明使用svhn训练的网络在域适应后才能很好的提取MNIST数据集上的特征。
domain adaptation作为transfer learning的一个子问题,可以细分到很多方面
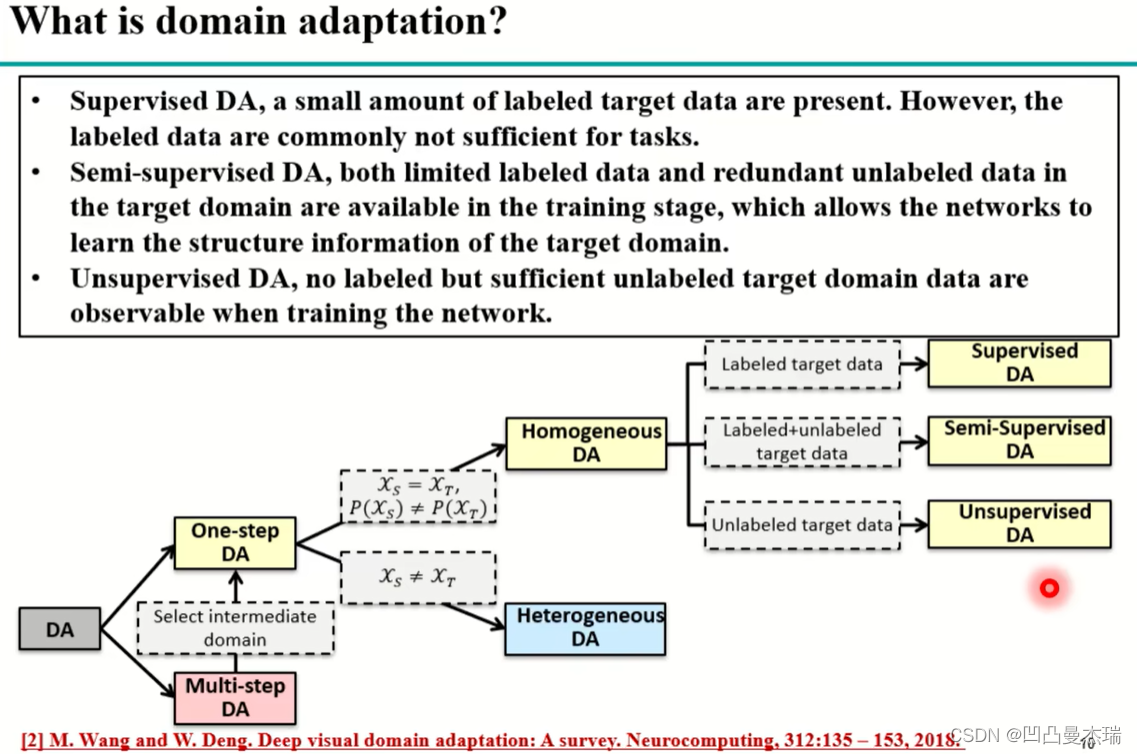
当源域和目标域的差距较大时,比如手写数字识别到人脸的识别,这种很大的迁移可以划分为多个阶段一步步的来,这种多步迁移(Multi-step DA)选择合适的中间域后就变成了单步迁移(One-step DA),单步迁移又可以根据数据的不同分为同构迁移(Homogeneous DA)和异构迁移(Heterogeneous DA),同构:数据空间一样,但数据分布不一样,异构:数据空间不一样,比图人脸和文字。
同构迁移(Homogeneous)中根据有标签数据和无标签数据的数量又可以分为有监督(Supervisedd DA),半监督(Semi-Supervised DA)和无监督域适应(Unsupervised DA,研究最多)。
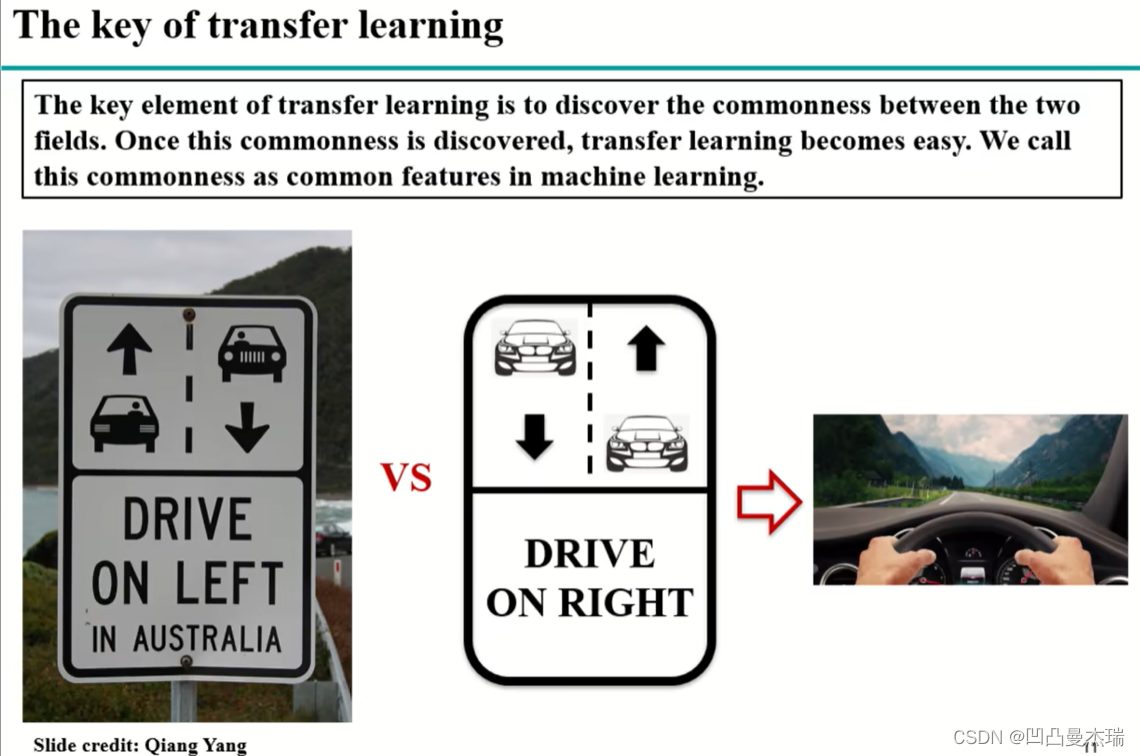
迁移学习的关键点:寻找数据的共同性,无论是左开车还是右开车,人都是在中间的。
yang qiang 在2010年的非深度迁移学习中(A survey on transfer learning)中提出了一些方法

traditional deep adaptation:
方法1:特征的适应,Feature adaptation
feature adaptation:将源域和目标域的特征提取到一个共同的特征空间里,在这个空间中源域和目标域的距离足够的近,二者足够的对齐,这样目标域的性能就会提升,上面SVHN-MNIST。
方法2:实例的适应,Instance adaptation
源域有部分数据和目标域比较像,对于越像的数据,给的权重越大,使用这些数据训练出来的模型在目标域上的效果就会比较好。
方法3模型的适应,Model adaptation
找到一些参数进行迁移,使得目标域的性能得到提升
上面三种都是非深度的迁移学习?。
2018年的一篇论文对深度学习域适应进行了综述(Deep visual domain adaptation:A survey):

该论文中将深度迁移学习域适应分为三大类(这三大类主要还是基于特征的域适应):
扩展:深度学习中经常用到fine-tune(微调),发表于2014年的一篇论文**《How transferable are features in deep neural networks?》**对fine-tune进行了一个小的实验:
论文中,作者通过实验发现,深度神经网络的浅层所提取的特征更加general(整体的,普遍的,一般的,大概的,笼统的),即提取的特征比较边缘,比较通用,但是越到高层越专业化,越偏向于任务性,其特征中融入更多的domain的信息,即当使用源域数据训练深度网络的时候,更适用于源域。
论文中的实验:分别在数据集合A,B上训练两个网络A,B,然后将B的前三层拿走固定好,后5层继续用数据B训练,将这种组合训练后的网络作为B3B,最后对B3B所有的层作训练,作为B3B+;对于A,前三层直接拿过来,后5层用数据B训练,最后组成A3B,然后对所有的层适用数据B训练,作为A3B+。
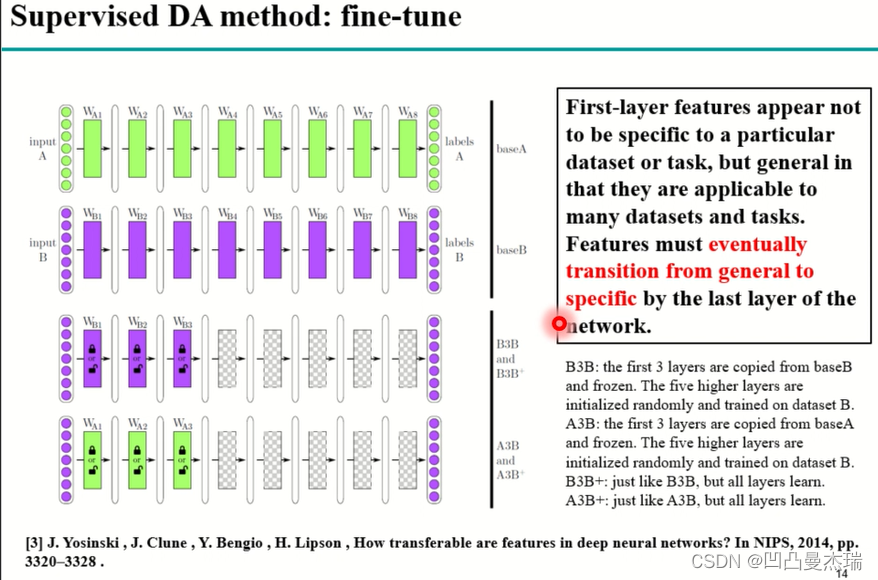
之后对B3B、B3B+、A3B、A3B+的每一层性能进行分析:

发现在B3B、A3B层的连接处(3~4),会出现性能的下降,这种脆弱的性能的下降称为co-adaptation(由于高层性能的专用化),对所有的层训练后,B3B+、A3B+中这种性能的下降会被弥补。
但是,大多数情况下是没有很多有标签数据的,是没有办法进行fine-tune的,因此无监督的域适应是很有必要的。
无监督域适应的大体思路:源域和目标域之间存在一定的距离,在数学公式中找到一个能很好的衡量两个域之间距离的度量公式(特征上),然后就将这种距离数字化了,数字化后就可以作为网络中的loss,然后让深度网络优化这个loss,让距离逐渐变小(很重要的思路):

MMD是一个比较重要的度量公式:
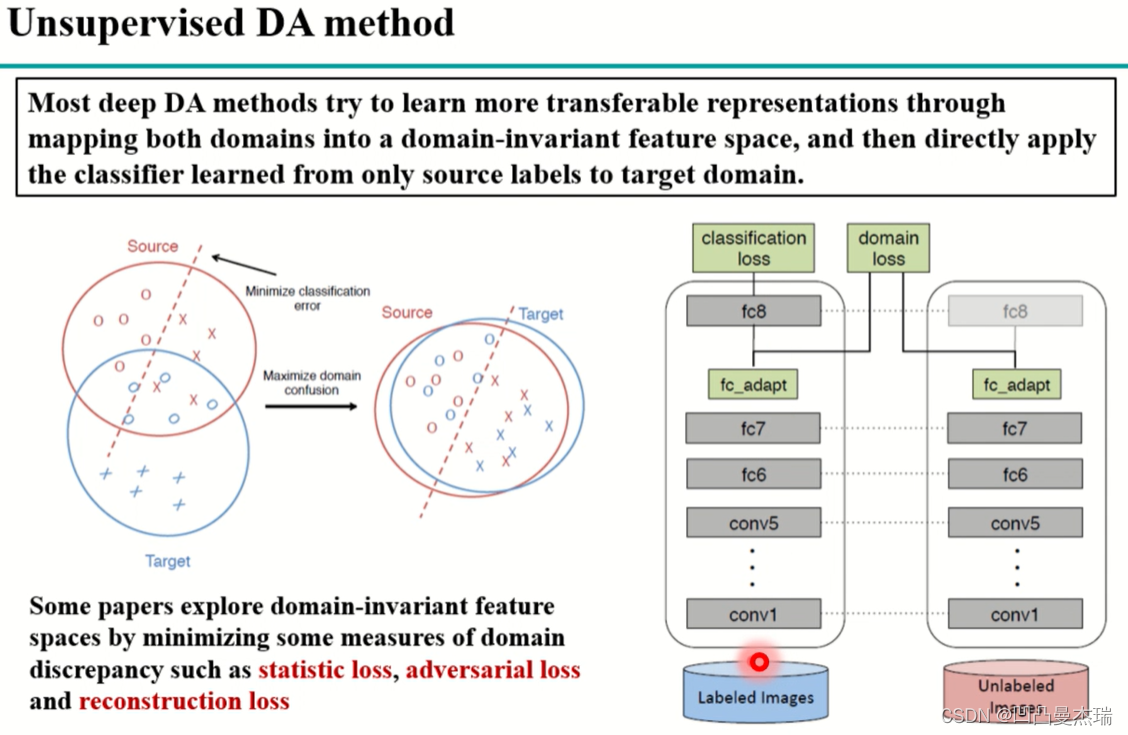
上图中的左侧,源域和目标域通过距离的度量,一步步接近,最后到达距离的最小值。图中的右侧是无监督域适应的一个例子:源域数据还是通过有标签的数据(labeled images)训练一个网络,目标域的数据是无标签的(unlabeled images),由于目标域的数据是无监督的,无法适用loss对模型进行微调。使用以下方法解决:首先,让源域和目标域网络保持参数一致,源域参数改变,目标域参数也改变;其次,在某一层,一般是高层,增加一个domain loss,计算源域和目标域之间的距离,classification loss和domain loss加在一起不断的在网络中回传微调,通过使domain loss不断的减小,最终源域训练的结果在目标域上也会有一个比较好的结果。

使用MMD的这种方式比较经典,称为DDC,相关论文**(Deep domain confusion:Maximizing for domain invariance,2014)**
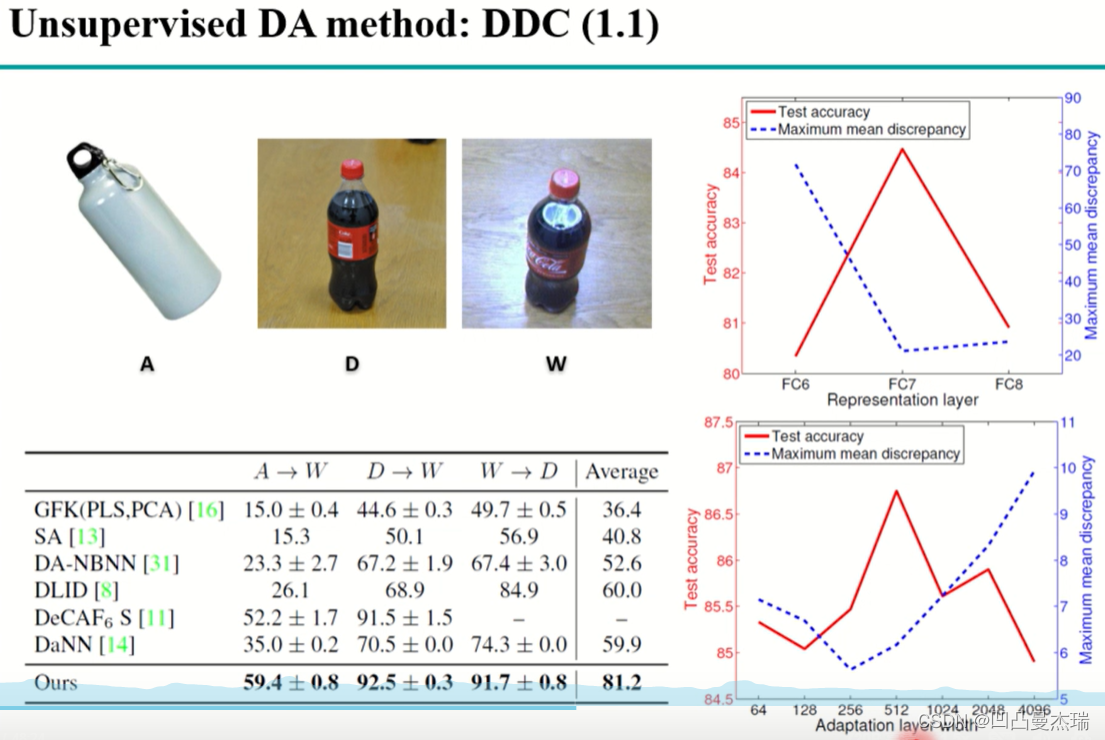
上述为非深度的迁移学习
还有基于DDC的改进(Learning transferable features with deep adaptation networks,2015)(经典):
既然特征的提取在高层比较明显,那么是否可以将倒数的基层都加上呢?(比上篇论文多加了几层)

另一种改进:使用一个核函数映射到希尔伯特空间,那么用多个核函数会是什么结果呢?使用多个高斯核函数的线性组合,低阶矩和高阶矩都考虑进去。
还有一种改进:《Unsupervised domain adaptation with residual transfer networks》,2016(经典)
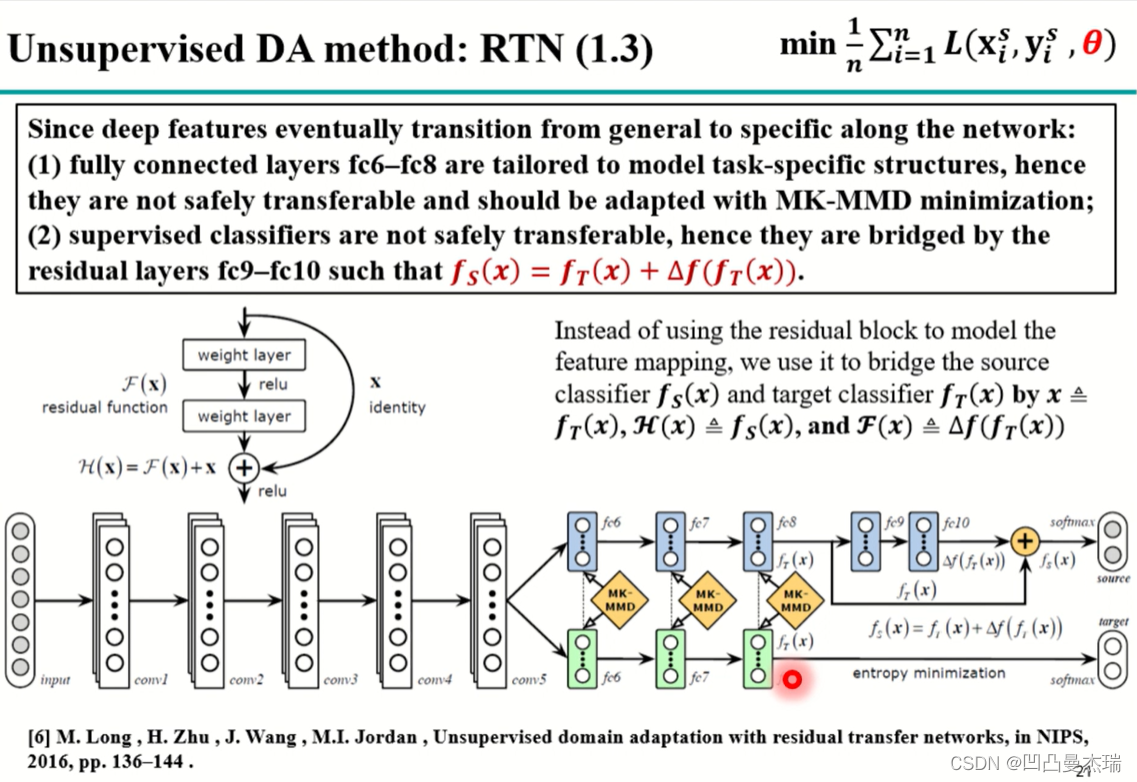
论文中假设特征没有拉的那么近,即没有对齐的那么好,就会导致在目标域上的结果不是很好,需要对源域的分类器参数进行改进。于是改论文中将参差网络加入模型中,fc8后直接定义目标域的分类器,fc9~fc10是为了学习源域和目标域之间的差异,将学到的差异加到分类器上,从而学习源域和目标域分类器的差异(非深度迁移学习中的特征,参数,实例的适应中特征适应和参数适应的结合)。
第4种改进:《Deep transfer learning with joint adaptation networks》(经典)
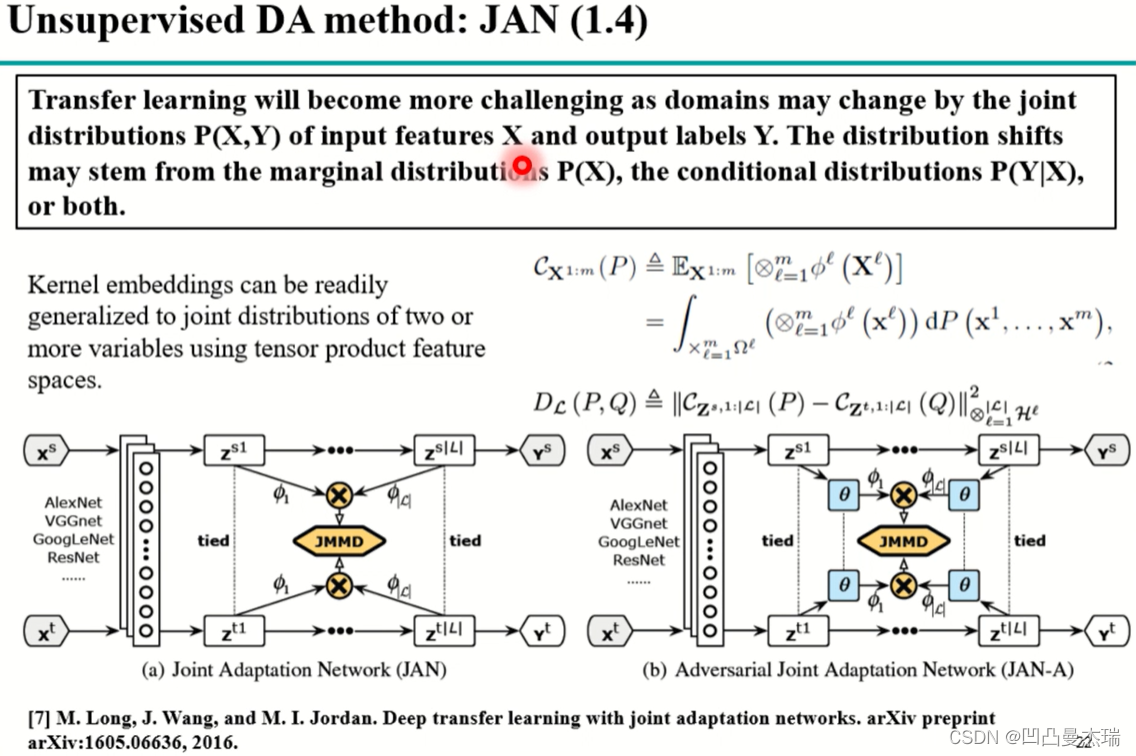
作者认为特征和label都会有差异,在一起就是联合差异,之前的DDC、DAN都只考虑边缘分布的差异,没有考虑条件分布的差异,通过设计JMMD(联合差异)的思想,通过内积映射核函数得到来联合分布,通过优化联合分布
去优化源域和目标域的特征和标签的联合分布。
还有一种基于对抗思想的DA:《Unsupervised domain adaptation by backpropagation》(经典)
除了MMD还有一种衡量方式H-divergence,这种思想启发于GAN,即对抗学习网络.

GAN的思想:生成一张足够真的图片,通过判别器,让图片足够真到其无法区分是真的图还是假的图。在域适应中,当判别器无法判别生成的特征是源域的特征还是目标域的特征的时候,就成功了,这个时候源域和目标域的特征空间是一致的,源域数据上的网络在目标域上就可以使用了。
具体流程即上图中:首先前部分是共有的特征提取器feature extractor,这里输入源域和目标域数据;然后数据分流,源域走上面的线路,训练源域的分类器,用交叉熵softmax进行监督提高性能;目标域走下面的线路,一个域分类器,主要是二分类器,分离源域和目标域,同时这部分要和开始的特征提取要不断的增强,直到分不出源域和特征域,说明源域和特征域在该特征上的分布很像,这个时候就可以迁移了。
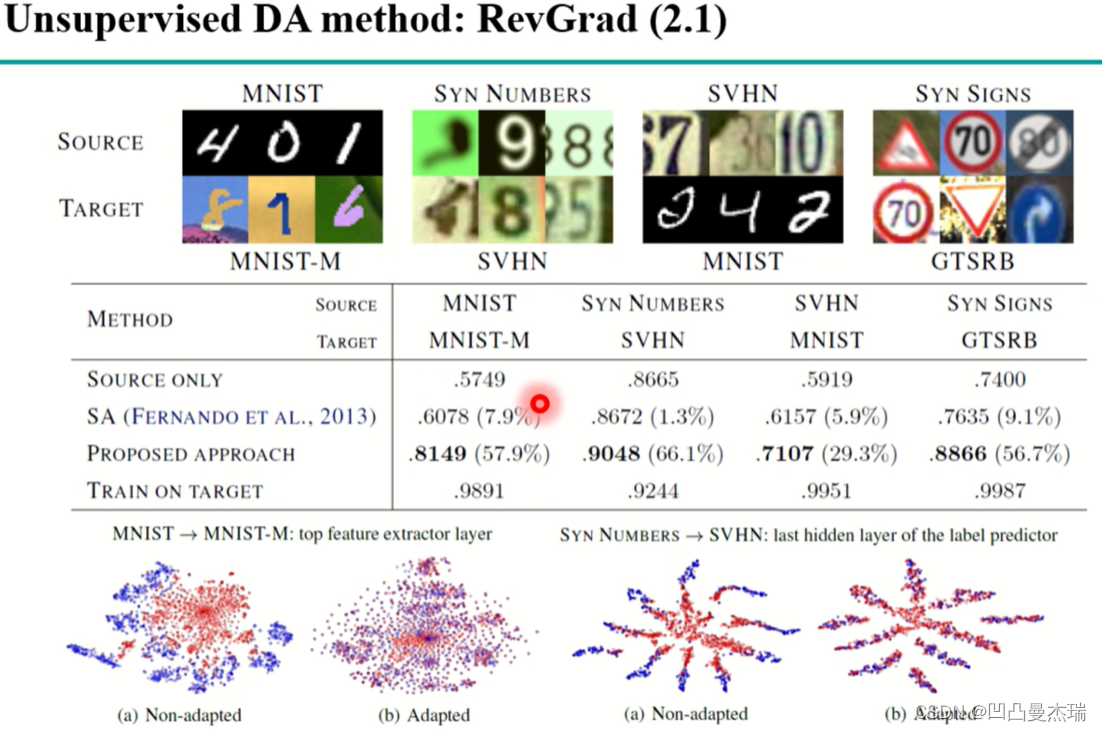
基于对抗的深度迁移学习在数据集上的测试。
DDC到DAN是单层变为多层,对抗网络中添加了一个判别器,可不可以添加多层判别器呢?
论文**《Collaborative and adversarial network for unsupervised domain adaptadion》2018(经典)**中提出了这样的方式。
深度网络不可能每一层都加上一个判别器,将多个层作为一个block,形成3~4个blocks(对抗)。
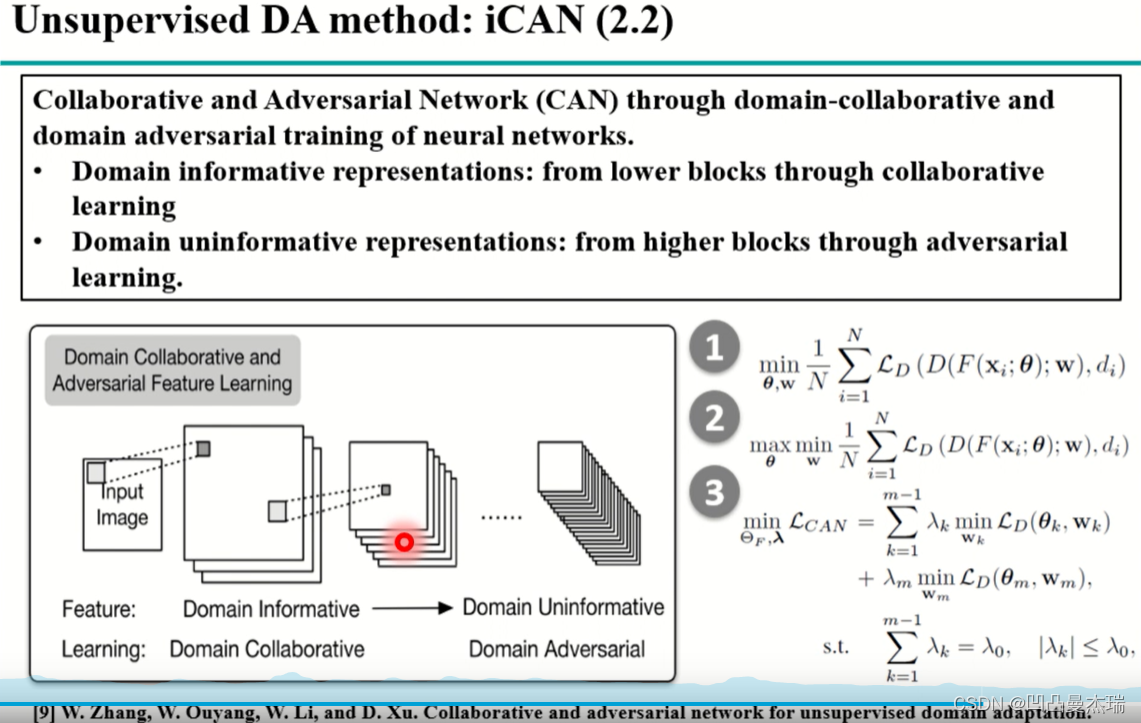
高层判别器:高层block中,特征应该与域的信息无关,在分不清源域和目标域的时候,才能在目标域上有很好的性能。
底层判别器:底层的block中,特征与域的信息有关,因为底层在提取边缘信息,并希望这些边缘信息能更好的学习目标域的特征。
前面的迁移学习使用的数据都是类似于office31或者手写数据集(0~9),这些数据的特征是:源域和目标域的数据类别是一样的,甚至类别的个数都一样。但现实生活中源域和目标域差别较大。
论文**《Multi-adversarial domain adaptation》2018**
当目标域是源域的子集的时候:
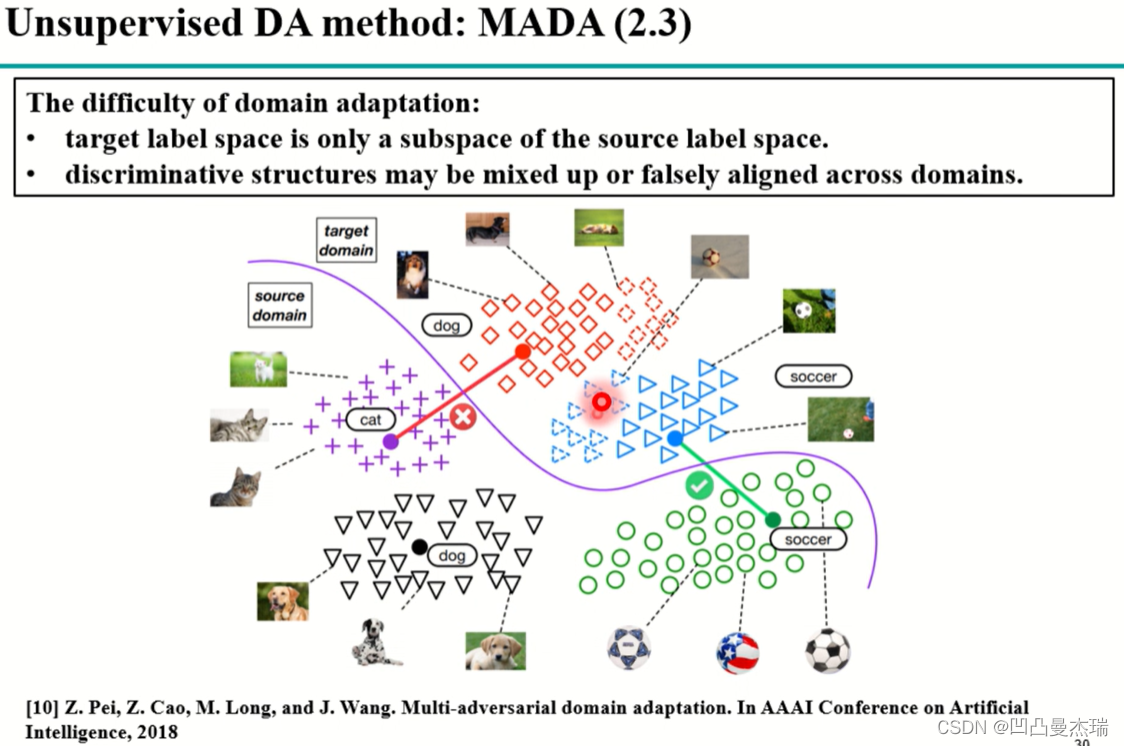
例如上图中,目标域是狗,足球,是源域的一个子集,这个时候猫就会没有数据对齐,这个时候会出现以下现象:源域中的部分狗对齐到了猫,导致数据的对齐出现混乱。这个时候人们发现源域和目标域的对齐应该精细化到类别,而不是简单的整个域的对齐。《Multi-adversarial domain adaptation》2018
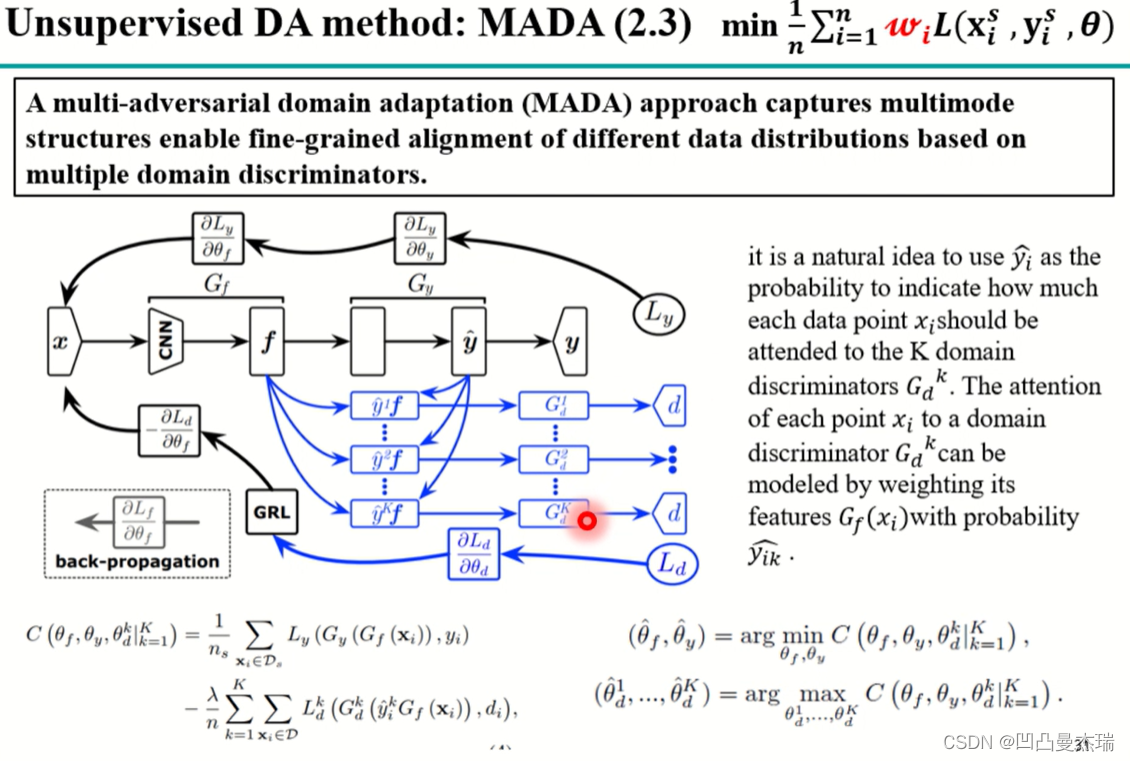
思想:将放在最后层的判别器分开为N个判别器,每个判别器
G
d
K
G_{d}^{K}
GdK对应一个子类
d
d
d,即类和类的对齐。引入语义信息的对齐,能让整个特征空间对的更齐。(语义信息:指明某个被划分的空间是什么,或者指明提取的特征,例如:这个特征对应是狗,这个特征对应是猫…)这就需要label,但是目标域中没有label。于是论文中提出一种方法(上图):首先跟传统的深度学习一样,将源域的数据输入到分类器提取到特征,输入到一个源域的分类器,同时目标域同时也输入到源域分类器,之后源域连接了一个softmax(softmax会输出一个该数据属于某个类的概率),得到的概率
y
^
\hat{y}
y^乘以特征
f
f
f输入到判别器
G
d
1
G^{1}_{d}
Gd1,当这个数据更像猫时候,就让其大概率对齐猫,更小的概率像狗时,小概率对齐狗。即目标域更像哪个源域,就让哪个源域发挥更大的作用(实例的对齐)。
另一种对齐方式不是上面那种细粒度的对齐:《Importance Weighted Adversarial Nets for Partial Domain Adaptation》(2018)
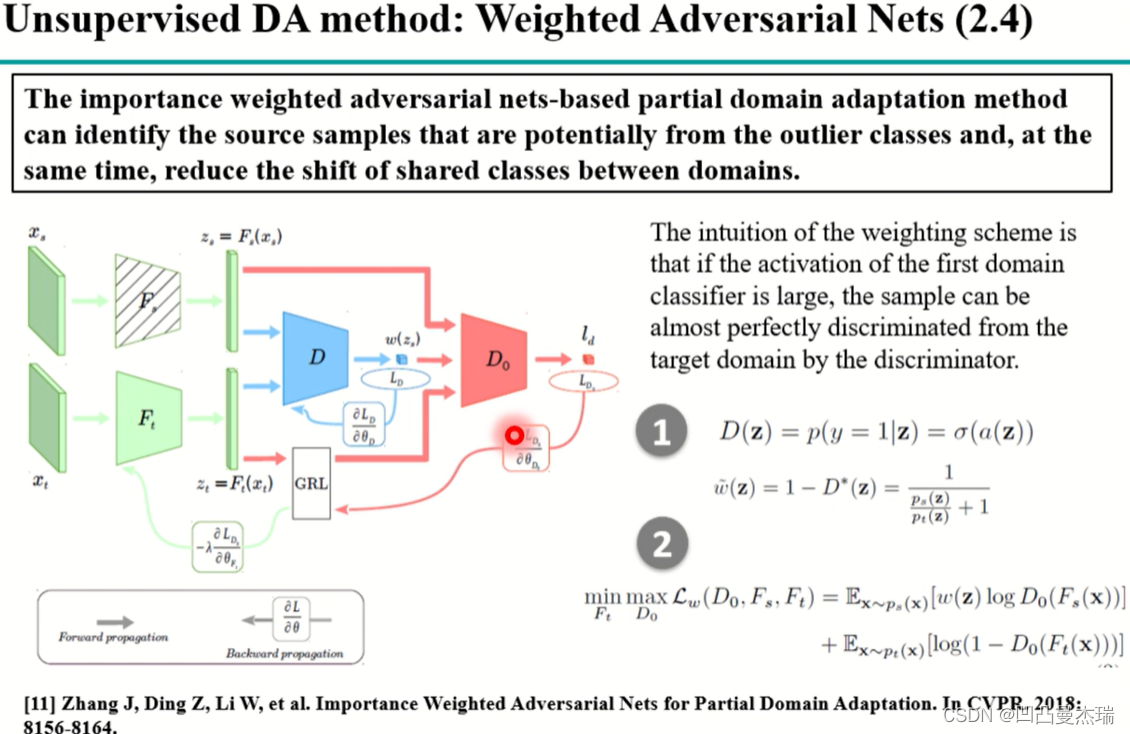
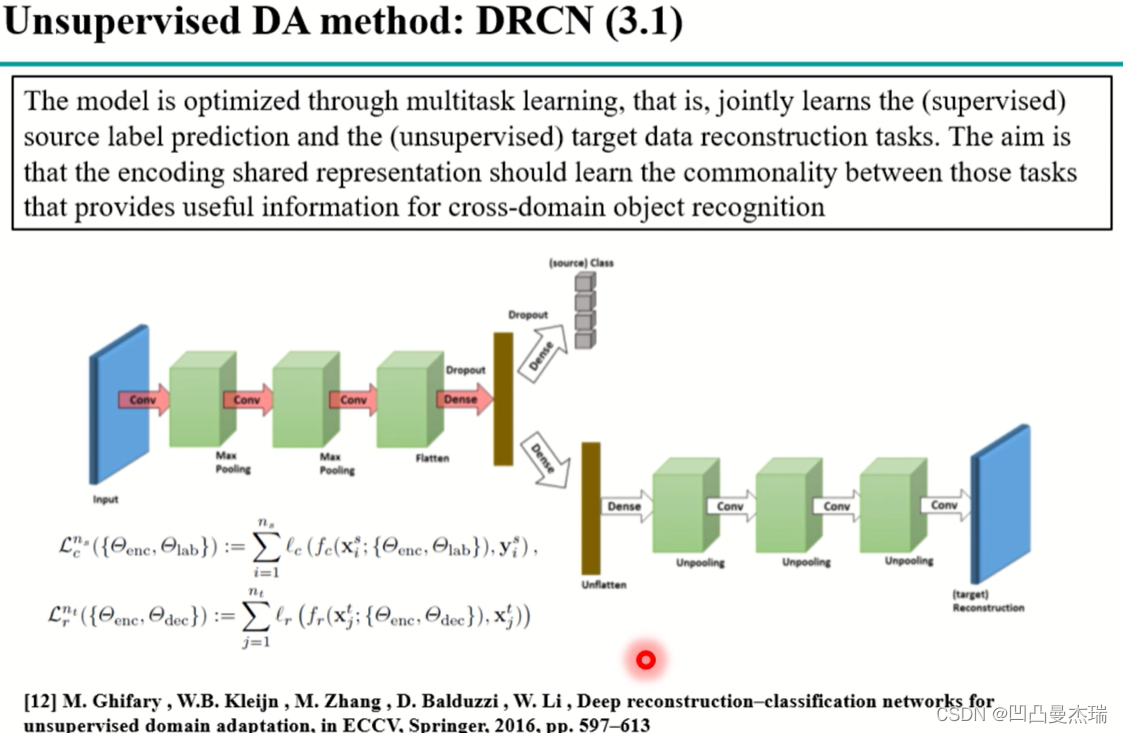
模型中在开始也是设置一个参数共享的特征提取器,源域和目标域都输入进去,然后编码成特征之后输入到源域分类器上去优化网络,第二部分做解码重构,使得特征重新解码后变回目标域的特征等信息,这两个部分,源域的分类器能让模型在源域上的分类变的更好,目标域重构使特征离目标域不会太远。
类似于上述的重构,还有一种利用编解码器的方法:《Domain separation networks》,2016
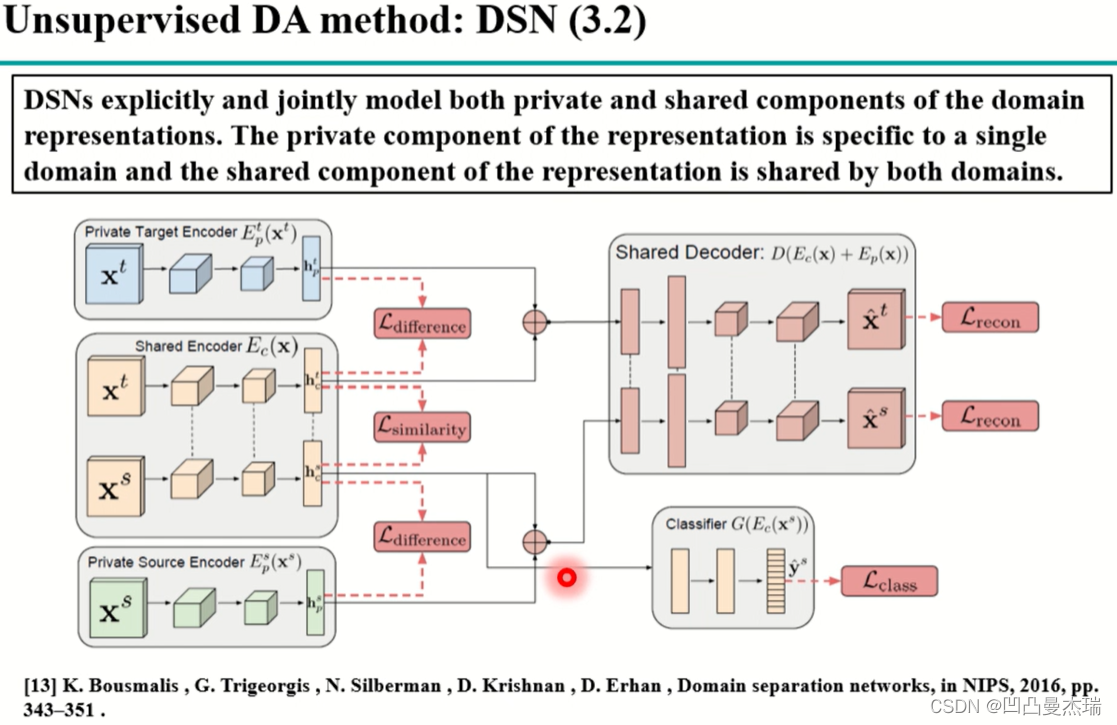

该方法较上一个更复杂,思路:将目标域和源域的样本拆成两个部分,一部分是域私有的包含了域的特定信息,另一部分是共有的,包含了域的共有特征;对于共有的特征,在源域训练好后就可以在目标域上使用,但怎么分的更好,需要约束。即让私有和共有的特征更正交,即更不一样,这样私有和共有就会分开;分开的同时,这两个特征重新结合后,经过decoder后能重构原样本,即重要的信息没有损失;对于共同特征的和特有的特征,分别有difference和similarity损失函数。
深度学习层面的迁移学习大致分为三类,这三大类还是基于特征的域适应
1.基于差异的域适应(Discrepancy-based DA)
2.基于对抗的域适应(Adversarial-based DA)
3.基于重构的域适应(Reconstruction DA)
除了上面的三大类,还有一些小类的方式:

论文**《Asymmetric tri-training for unsupervised domain adaptation》 2017**
在对数据打标签上提出了新的方法:最容易想到的是在源域上训练的网络能在目标域上对每个数据使用softmax输出一个像每个类的概率值,可以使用这种方式对目标域的数据打标签,然后使用打了标签的目标域数据有监督训练网络,最终形成对目标域的识别网络,但有个问题是:用源域数据训练的网络在目标域上的识别本来就不好,label不可靠,有可能造成负迁移,即迁移偏了。于是就出现使用**伪标签**的方法,即训练两个不相关的正交分类器,当这两个不相关的分类器对同一个数据都认为是A类的时候,就可以认为该数据是A类,那么这些数据就可以拿去训练网络,反复跌打,最终用于目标域的识别。
另一种**伪标签的方法:《Progressive feature alignment for unsupervised domain adaptation》2018**
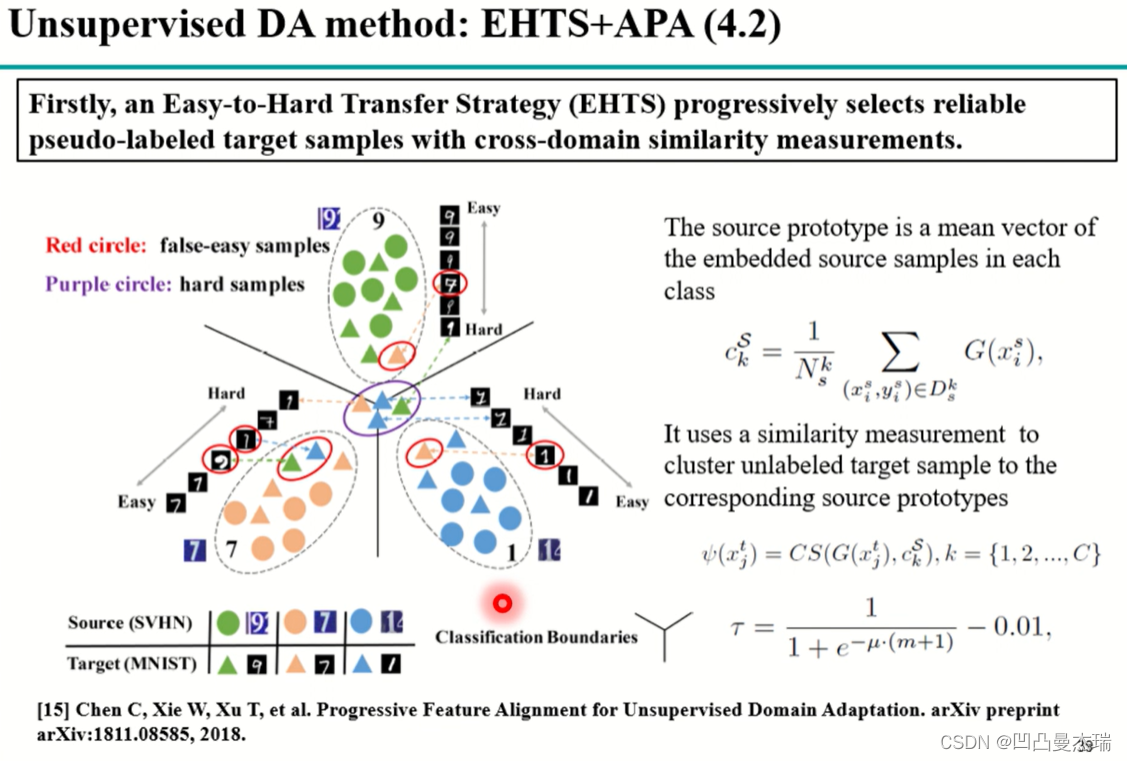
该论文中,模型使用源域数据训练好网络后,提取平均特征,将该特征作为类的类中心,目标域的特征和源域的平均特征做余弦相似度,相似度越大,目标域的相似度是属于这个label的,前提是目标域和源域类别相同。对于label是否可靠,要使用一个阈值判断,合格后在用于fine-tune网络。

人脸识别的综述:《Deep face recognition:A survey》2018
人脸识别种族差异,需要迁移学习:《Racial Faces in-the-Wild:Reducing Bias by Deep Unsupervised Domain Adaptation》2018
思考:图像识别技术和域适应技术都比较成熟了,对于该项目,除了这些,还牵扯到的一个就是图像的输入算法,类似于汉字的输入法,绘图过程中不需要完全绘制出图形,系统就能识别出用户想输入的东西
域适应上,用户的第一张图像,可以按照之前的经验直接识别(这个过程就类似普通的迁移学习中第一张图的迁移),或者按照对抗的思想,第一张既采用之前的经验学习,还要将这张图片与之前的已经学习到的经验进行对比,从这个过程中逐步形成对新用户数据的特征提取,
对抗的思想就是生成器和判别器不断的相互作用,直到生成器生成的图片判别器无法识别是生成器生成的还是原始的数据
…转到迁移学习,再转到域适应,然后深度域适应,就深度域适应中的方法进行研究分析
论文《Deep Visual Domain Adaptation: A Survey》中这样提到:
the discrepancy-based approaches have been studied for years and
produced more methods in many research works, whereas the
adversarial-based and reconstruction-based approaches are a
relatively new research topic but have recently been attracting
more attention.
基于差异的方法已经被很多人研究,基于对抗和重构的思想近几年刚引起关注,对抗技术有多种,用哪一种呢?。
草图稀疏性,对于草图,相较复杂的彩色图像和专业素描,尽管草图线条简单,细节较少,
相关中文文献整理
基于深度学习的手绘草图生成、识别及应用研究(2020)
对于深度神经网络训练的理解:类似于Alexnet和ResNet等常用的深度神经网络,其网络的结构是固定的,需要用户根据需要,对训练的损失函数等公式以及网络使用多少层,每层多少输入输出这些东西进行选择,以及训练的方式,数据的划分需要根据使用场景合理的选择。
博士论文中的草图,是由自然图像采用一定的方式转化为草图得到的,这种方式能解决草图数据不足的问题
用户画了两三张图,用深度网络提取深度特征(之前有很多数据,浅层的特征是通用的,已经提取过了),然后基于该策略,使用某种方法,对仅有的两三张图,固定住某些特征不变,将这两三张图经过一定的算法进行变形生成新的图片(在这里我们可以称这种数据为伪数据),伪装成该用户的图片,以提高系统对该用户的数据识别率。这是一个很重要的思虑。或者说,在某些特定的位置对图像进行变换(这种思想模拟了人的大脑的想象这一功能,升生活种的一些事情会在人的梦中发生一些改变,这就是人的想象在根据先前的经验创造新的数据)。
思考:深度网络已经提取出某些特征,固定这些特征后生成的图片,深度网络还会学习到新的特征吗?如果学习到新的特征,会与用户的一样吗?就草图而言,人的绘制风格的种类有多少种呢?
论文《Domain Adaptation for Visual Applications: A Comprehensive Survey》
对浅层的域适应技术分类
基于实例的重新加权法















 1252
1252











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









