







网页爬取的数据写入Excel
一般我们要爬取数据并保存持久化下来才可以进一步操作(分析),下面是爬取数据持久化的基本步骤:
首先,Python要读写Excel需要用到一个三方库openpyxl(只支持读写excel2007后版本,xlsx),xlrd / xlwt(这两个库处理xls,分别是读写),xlwings(支持新旧版本Excel),学会任意一个库的使用,其他都是如法炮制。
#先终端安装三方库
pip install xlwt
#或者安装另外一个库
pip install openpyxl
每个Excel就是一个工作簿,Workbook;
Excel => 工作簿 => Workbook,
新建一个Excel文件就是一个工作簿,
下面是每一个工作表(Sheet),一个工作簿可以n个工作表,
一个工作表里有行和列,每一个是一个单元格(Cell),这些记住了,方便你使用库写入Excel的流程。
#先建工作簿
wb = xlwt.WorkBook() #另外一个库的使用是很相似的 wb = openpyxl.WorkBook()
#再建工作表,test表名
sheet = wb.add_sheet(‘test’) #另外一个库的使用是很相似的 sheet = wb.create_sheet(‘test’)
#再把数据放入单元格,创建一个列表变量
lists = ['帅哥', '美女', '渣男', '渣女']
#通过write(行,列,内容)方法写进去
#Python内置方法enumerate
#Python的内置函数enumerate,enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
for list in lists:
sheet.wirte(0, index, list)
#另外一个库的使用是很相似的 sheet.cell(1, index, list) 不过第一行这里至少从1开始
#最后记得保存工作簿
wb.save(‘test.xls’) # 新版的Excel后缀是xlsx wb.save(‘test.xlsx’)
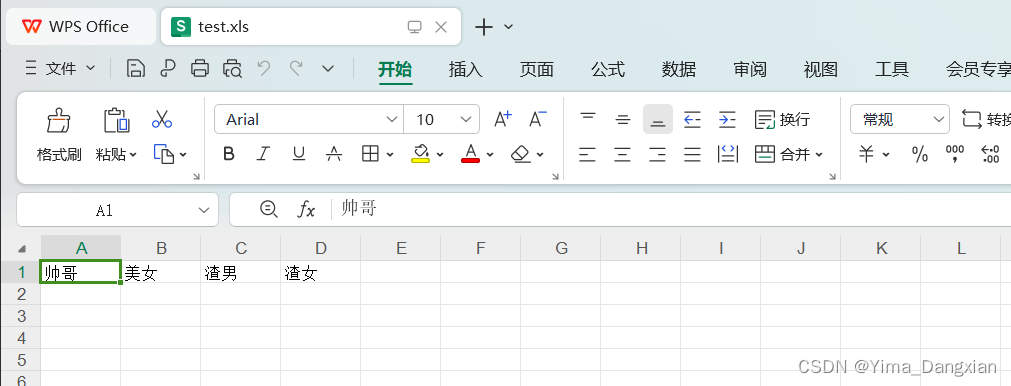
没制定路径最后会在项目根目录下创建这个Excel表,效果如下:
















 2286
2286











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











