






在我的一篇文章队列中,我简单地介绍了什么是队列,以及队列有哪些操作,一个数据结构能够被称为队列,它必须具备两个功能限制:数据只能在队尾插入,数据只能在队首删除。这两个功能限制注定了它只能顺序地处理队列里面的任务,但是有时候一个队列里的任务是有轻重缓急之分的,这样顺序处理显然是不合理的,我们要有选择地优先处理某些任务,优先队列就是这样一种可以有选择地处理队列中的任务的队列。
每一个数据结构都有一堆与之相绑定的操作,不同的数据结构有不同类型的操作,有不同数量的操作,它们都有一个最小数量的必须支持的操作来表明这个数据结构的类型,优先队列同样如此。
优先队列至少要支持下列两种操作:
- Insert:在队尾插入数据
- Delete_Min:找出队列中的最小元素,然后删除它。
我们下面就来介绍如何实现带有这两种功能的优先队列。
我们这里使用一个叫做二叉堆的结构来实现优先队列。什么是二叉堆(维基百科),这种二叉堆其实就是完全二叉树的特例,下面我们先介绍完全二叉树,然后在此基础上介绍二叉堆。
下图是一个完全二叉树的结构。

一项重要的观察发现,因为完全二叉树很有规律,所以它可以用数组实现,而不需要用指针,如下图所示,同一种颜色表示它们在树的同一层。
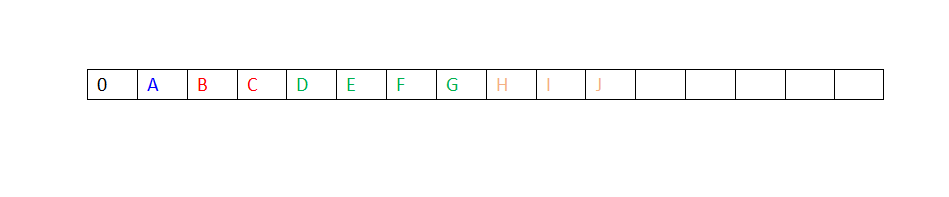
进一步观察,我们发现了如下十分有意思?的性质:对于数组上任意一个位置i上的元素,它的左儿子在位置2i上,右儿子在位置(2i + 1)上,它的父亲在位置i/2上,由于这些性质的存在,它的遍历十分方便。
介绍完完全二叉树后,我们下面就来介绍二叉堆相对于完全二叉树到底“特”在哪里。
还记得前面优先队列必须支持的两个功能吗,第一个插入Insert,这个功能在完全二叉树中的体现就是在数组的后面紧接着就插入元素,另一个是删除最小Delete_Min,这个功能要求我们保证所有结点都要比它的儿子小。这样可以实现快速的删除操作。这个性质叫做堆序性,当一个完全二叉树满足堆序性后,它将以一个常数时间删除最小元素。所以二叉堆就是一个满足堆序性的完全二叉树。如下图所示,左边的是二叉堆,右边的不是

二叉堆是实现优先队列的十分普遍的结构。
目前我们拥有了一个非常棒?的结构,我们现在要在这种结构上绑定一些功能来实现优先队列。
一、插入
为了保证插入之后这个结构仍然是一个完全二叉树,我们需要在数组的最后创建一个空穴用来存放这个数,如果这个数放在这个空穴中没有破坏二叉堆的堆序性,那么插入完成,如果堆序性被破坏了,我们就先不要把这个数放进去,而是先把空穴和它的父节点调换位置,然后继续判断该数插在空穴的当前位置有没有破坏二叉堆的堆序性,如果没有,插入完成,如果破坏了,就先不插入,而是继续将当前空穴与它的父节点调换位置,如此循环往复,直到空穴所在的位置被插入数据后不再破坏二叉堆的堆序性为止,这时候将数据插入空穴中,插入完成。还是那句话,没图说个JB,下图是对上述操作的演示。红色圈圈里是我们要插入的数据,亮绿色是我们创建的空穴

这种方法叫做上滤(percolate up),应该是很形象的叫法了?
下面是代码实现(包含优先队列的构建)
头文件
#ifndef BINARY_HEAP_H_INCLUDED
#define BINARY_HEAP_H_INCLUDED
#define MIN_SIZE 5
typedef struct Heap_Struct{
int capacity;
int size;
int *data;
}Priority_Queue;
void Insert(int data, Priority_Queue *H);
Priority_Queue *Initialize(int Max_Element);
#endif // BINARY_HEAP_H_INCLUDED
c文件
#include "binary_heap.h"
#include <stdio.h>
void Insert(int data, Priority_Queue *H)
{
int i;
for(i = ++H->size; H->data[i / 2] > data; i /= 2)
H->data[i] = H->data[i/2];
H->data[i] = data;
}
Priority_Queue *Initialize(int Max_Element)
{
Priority_Queue *H;
if(Max_Element < MIN_SIZE)
printf("Priority queue size is too small !");
H = (Priority_Queue *)malloc(sizeof(Priority_Queue));
if(H == NULL)
{
printf("Out of space !");
exit(1);
}
H->data = (int *)malloc((Max_Element + 1) * sizeof(int));
if(H->data == NULL)
{
printf("Out of space !!");
exit(1);
}
H->capacity = Max_Element;
H->size = 0;
H->data[0] = 0;
return H;
}
二、删除最小
由于前面插入的作用,我们可以很容易找到优先队列里面的最小元素,它就在根结点,也就是数组的第一个元素(其实是第二个,仔细观察前面那张数组图),但是当删除这个元素后,在根结点处产生一个空穴,由于现在少了一个元素,因此二叉堆中的最后一个元素X必须移动到二叉堆的某个地方,如果X可以被放到空穴中,那么删除结束,但是这一般不太可能直接就实现,我们一般的做法是将空穴的两个儿子中的较小的一个与空穴互换位置,这样空穴就在向下移动,重复该步骤,直到最后的元素X可以放入空穴。还是那句话,没图说个JB。下面是上面思路的图解
首先是删除最小元素后的状态,我们尝试将最后一个元素放进空穴,发现不满足堆序性要求,将空穴往下移动。(注意,这句话的中最后的“移动”操作是放在下一张图了)

移动完成后,我们再尝试将最后一个数放进空穴,发现还是不行,继续将空穴往下移动

再尝试,发现还是不行,继续向下移动

这次再放进去看看,OK成功了,删除结束

在最后一步的时候,我们发现,结点36只有左儿子,没有右儿子,也就是说它的右儿子即使有值也不应该参与比较,这会导致混乱,所以我们要对此进行一个判断,也就是如果2*i == size,即可判定这个结点只有左儿子,应当直接比较左儿子与当前结点值,而不用将右儿子与左儿子进行比较。这在下面的代码中有体现。还有一种思路就是如果删除前结点数是偶数,那么我们就在结尾处放一个比所有结点都要大的数,这样就不用进行多余的测试了。
下面是它的代码实现
int Delete_Min(Priority_Queue *H)
{
int i, child;
int Min_Element, Last_Element;
if(Is_Empty(H))
{
printf("Priority queue is empty !!\n");
return H->data[0];
}
Min_Element = H->data[1];//把被删除的元素保存起来
Last_Element = H->data[H->size];//把最后一个元素保存起来
H->size--;//二叉堆的大小减1
for(i = 1; i * 2 <= H->size/*当前空穴是否有左儿子*/; i = child)
{
//i在这里是空穴的当前位置
child = i*2;//给出它左儿子的位置
if(child != H->size && H->data[child + 1] < H->data[child])
child++;//当child == H->size,也就是当一个结点只有左儿子的时候,我们是不会进行这一步的。当左右儿子都存在的时候,我们就将它们进行比较,将较小的儿子记下来准备用来交换
if(Last_Element > H->data[child])//将当前空穴所在结点的待被交换的儿子的值与最后的结点值进行比较,如果最后结点值大,空穴就继续往下移动,如果最后结点值小,就结束循环
H->data[i] = H->data[child];
else
break;
}
H->data[i] = Last_Element;//把最后结点值移动到当前的空穴中
return Min_Element;//返回被删除的结点
}















 503
503











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









