







ASR介绍
自动语音识别 (Automatic Speech Recognition, ASR) , 通过计算机自动将人类口头语音转录为文本,此项技术在多个领域有着广泛的应用。
语音识别模型对比
Paraformer与SenseVoice介绍
Paraformer是一种非自回归端到端语音识别模型。非自回归模型相比于目前主流的自回归模型,可以并行的对整条句子输出目标文字,特别适合利用GPU进行并行推理。Paraformer是目前已知的首个在工业大数据上可以获得和自回归端到端模型相同性能的非自回归模型。
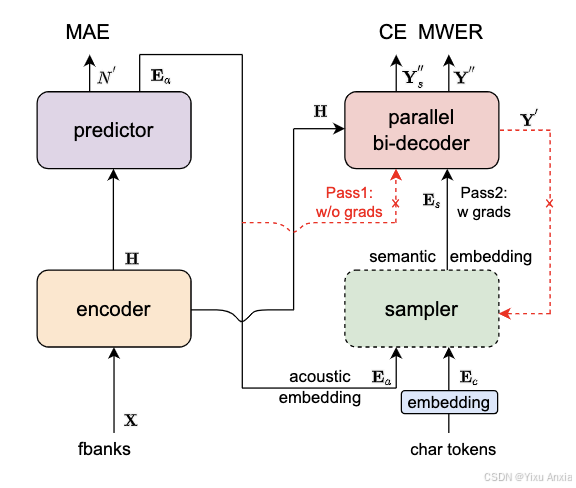
Paraformer模型结构如下图所示,由 Encoder、Predictor、Sampler、Decoder 与 Loss function 五部分组成。
- Encoder(编码器):与自回归模型保持一致,可以采用不同的网络结构,例如self-attention,conformer,SAN-M等。
- Predictor(预测器):结构为两层FFN,预测目标文字个数以及抽取目标文字对应的声学向量。该模块基于 Continuous integrate-and-fire (CIF) 的 预测器 (Predictor) 来抽取目标文字对应的声学特征向量,可以更加准确的预测语音中目标文字个数。
- Sampler(采样器):为无可学习参数模块,依据输入的声学向量和目标向量,生产含有语义的特征向量。通过采样,将声学特征向量与目标文字向量变换成含有语义信息的特征向量,配合双向的 Decoder 来增强模型对于上下文的建模能力。
- Decoder(解码器):结构与自回归模型类似,为双向建模(自回归为单向建模)。
- Loss function(损失函数):除了交叉熵(CE)与 MWER 区分性优化目标,还包括了 Predictor 优化目标 MAE。
SenseVoice 是具有音频理解能力的音频基础模型,包括语音识别(ASR)、语种
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









