






深度优先搜索DFS
DFS就是深度搜索,深度搜索即一直找,一条路走到黑,如果是死胡同就回溯到拐弯的地方找第二个弯,其中重要的地方就是记录走过的路口,才能做到回溯。
广度优先搜索BFS
不含权重的代码
graph = {
'A':['C','B'],
'B':['A','C','D'],
'C':['A','B','D','E'],
'D':['B','C','E','F'],
'E':['C','D'],
'F':['D'],
}
class Solution(object):
#深度搜索,就是迭代到找不到就回溯,使用栈
def DFS(self,graph,s): #graph表示图表关系,s表示开始的节点
stack = [] #新建栈
stack.append(s) #将初始节点加入到栈中
seen = set() #建立一个集合,后续判断是否重复
seen.add(s)
while (len(stack) > 0):
vertex = stack.pop() #移出栈的最后一个元素
nodes = graph[vertex] #找到那个元素的相关节点并保存起来
for w in nodes:
if w not in seen: #如果节点不重复,就添加到栈中
stack.append(w)
seen.add(w)
print(vertex, end=" ")
#广度搜索,使用队列
def BFS(self,graph,s): #graph表示图表关系,s表示开始的节点
queue = [] #新建队列
queue.append(s) #将初始节点加入到队列中
seen = set() #建立一个集合,后续判断是否重复
seen.add(s)
while (len(queue) > 0):
vertex = queue.pop(0) #移出队列的第一个元素
nodes = graph[vertex] #找到那个元素的相关节点并保存起来
for w in nodes:
if w not in seen: #如果节点不重复,就添加到队列中
queue.append(w)
seen.add(w)
print(vertex, end=" ")
if __name__ == '__main__':
result = Solution()
result.DFS(graph,'A')
print("")
result.BFS(graph,'A')
含有权重的代码
def bfs(graph_to_search, initial_state, goal_state, verbose=False):
# this is a list of a list because we need to eventually return
# the entire PATH from the initial state to the goal state. So,
# each element in this list represents a path from the the initial
# state to one frontier node. We use the first element in each path
# to represent the cost.
frontiers = [[0, initial_state]] # the frontier list only has the initial state, with a cost of 0.
visited = []
while len(frontiers) > 0: # use while loop to iteratively perform search
if verbose: # print out detailed information in each iteration
print('Frontiers (paths):')
for x in frontiers:
print(' -', x)
print('Visited:', visited)
print('\n')
path = frontiers.pop(0) # Get the first element in the list
node = path[-1] # Get the last node in this path
if node in visited: # check if we have expanded this node, if yes then skip this
continue
action = graph_to_search[node] # get the possible actions
for next_node, next_cost in action:
new_path = path.copy()
new_path.append(next_node)
new_path[0] = new_path[0] + next_cost
if next_node in visited or new_path in frontiers:
continue # skip this node if it is already in the frontiers or the visited list.
# check if we reached the goal state or not
if next_node == goal_state:
goal_path = new_path[1:] #取出整个path
goal_cost = new_path[0] #取出所消耗的cost
return goal_path, goal_cost # if yes, we can return this path and its cost
else:
frontiers.append(new_path) # add to the frontiers
# after exploring all actions, we add this node to the visited list
visited.append(node)
return None
graph = {
'A': [('B', 1), ('D', 2)],
'B': [('A', 1), ('C', 4), ('D', 2)],
'C': [('B', 4)],
'D': [('A', 2), ('B', 2)]
}
path, cost = bfs(graph, 'A', 'C')
print('The solution is:', path)
print('The cost is:', cost)
这里的graph和前面一样,只不过按照元组的形式多了一个权重,
其中
我们每次把遍历的node的相关联的节点送进这个action里面,
遍历这个action,取出new_path和new_cost,并进行append和累加,
接下来判断展开的节点 如果已经存在,跳过,如果节点没展开过就,累加到frontiers里面,如果是目标节点就return path和cost出来
DFS
相较于前面的BFS只有这个不一样,一个BFS是广度优先,即数据结构中的队列,先进先出
DFS是深度优先,即数据结构中的栈,先进后出,
path = frontiers.pop(-1)
迪杰斯特拉算法
也叫做贪心算法,union cost,就是使得当前损耗是最小的,举例从A到C地,我们就是要每走一步,都要选取到下一个目的地最短的路径的节点去遍历,这个时候要选取最短的路径去遍历,要用到一个sort()函数,对队列里面的值进行排序,每次挑选最短的,然后pop第一个出来即pop(0)
sort() 方法是对原列表进行操作,而 sorted() 方法会返回一个新列表,不是在原来的基础上进行操作
def uniform_cost_search(graph_to_search, initial_state, goal_state, verbose=False):
# this is a list of a list because we need to eventually return
# the entire PATH from the initial state to the goal state. So,
# each element in this list represents a path from the the initial
# state to one frontier node. We use the first element in each path
# to represent the cost.
frontiers = [[0, initial_state]] # the frontier list only has the initial state, with a cost of 0.
visited = []
while len(frontiers) > 0: # use while loop to iteratively perform search
if verbose: # print out detailed information in each iteration
print('Frontiers (paths):')
for x in frontiers:
print(' -', x)
print('Visited:', visited)
print('\n')
frontiers = sorted(frontiers, key=lambda x: x[0])
path = frontiers.pop(0) # Get the first path in the queue
node = path[-1] # Get the last node in this path
if node == goal_state:
goal_path = path[1:]
goal_cost = path[0]
return goal_path, goal_cost
if node in visited: # check if we have expanded this node, if yes then skip this
continue
actions = graph_to_search[node] # get the possible actions
for next_node, next_cost in actions:
new_path = path.copy()
new_path.append(next_node)
new_path[0] = new_path[0] + next_cost
if next_node in visited or new_path in frontiers:
continue # skip this node if it is already in the frontiers or the visited list.
frontiers.append(new_path) # add to the frontiers
# after exploring all actions, we add this node to the visited list
visited.append(node)
return None
Greedy Search 贪心检索
def greedy_search(graph_to_search, initial_state, goal_state, heuristics_function, verbose=False):
# this is a list of a list because we need to eventually return
# the entire PATH from the initial state to the goal state. So,
# each element in this list represents a path from the the initial
# state to one frontier node. We use the first element in each path
# to represent the cost.
frontiers = [[0, initial_state]] # the frontier list only has the initial state, with a cost of 0.
visited = []
while len(frontiers) > 0: # use while loop to iteratively perform search
if verbose: # print out detailed information in each iteration
print('Frontiers (paths):')
for x in frontiers:
print(' -', x)
print('Visited:', visited)
print('\n')
# get the nodes in frontiers to be expanded
frontier_heuristics = []
for x in frontiers:
frontier_heuristics.append(heuristics_function(x[-1]))
idx_to_pop = frontier_heuristics.index(min(frontier_heuristics))
path = frontiers.pop(idx_to_pop)
node = path[-1] # Get the last node in this path
if node in visited: # check if we have expanded this node, if yes then skip this
continue
actions = graph_to_search[node] # get the possible actions
for next_node, next_cost in actions:
new_path = path.copy()
new_path.append(next_node)
new_path[0] = new_path[0] + next_cost
if next_node in visited or new_path in frontiers:
continue # skip this node if it is already in the frontiers or the visited list.
# check if we reached the goal state or not
if next_node == goal_state:
goal_path = new_path[1:]
goal_cost = new_path[0]
return goal_path, goal_cost # if yes, we can return this path and its cost
else:
frontiers.append(new_path) # add to the frontiers
# after exploring all actions, we add this node to the visited list
visited.append(node)
return None
贪心检索需要一个从当前目标出发到终点的一个信息值,还需要像union cost一样的权重,但是这里没有用到这个权重的大小,只是在找距离重点目标最小的值,所以在node前,会去找min的下标,然后返还给idx_to_pop,最后pop这个节点给node,接下来就跟之前一样。
这个算法有点像给了地图,然后我们在山顶,慢慢的按照地图标的高度慢慢的下降(梯度下降??),找到下山的最佳路径,只考虑我到终点的距离,不考虑其他因素
A* search
A = g + h*
A搜索A(A-Star) 算法是一种静态路网中求解最短路径最有效的直接搜索方法评价函数
f(n)=g(n)+h(n)h(n)的选取保证找到最短路径(最优解)的条件,关键在于估价函数f(n)的选取,也就是h(n)的选取距离估计与实际值越接近,估价函数取得就越好f(n)是从初始状态经由状态n到目标状态的代价估计,
-------------------------
g(n)是在状态空间中从初始状态到状态n的实际代价。
-------------------------
h(n)是从状态n到目标状态的最佳路径的估计代价。对于路径搜索问题,状态就是图中的结点,代价就是距离。
像上面贪心算法的题目一样,从A城市到B城市走了之后才知道我走了多少公里,有一个g,然后我知道我B城市距离目标城市的值是h(n),每一步都要使得这两个的和最小,这样就能够寻找到这个模型下的最佳路径
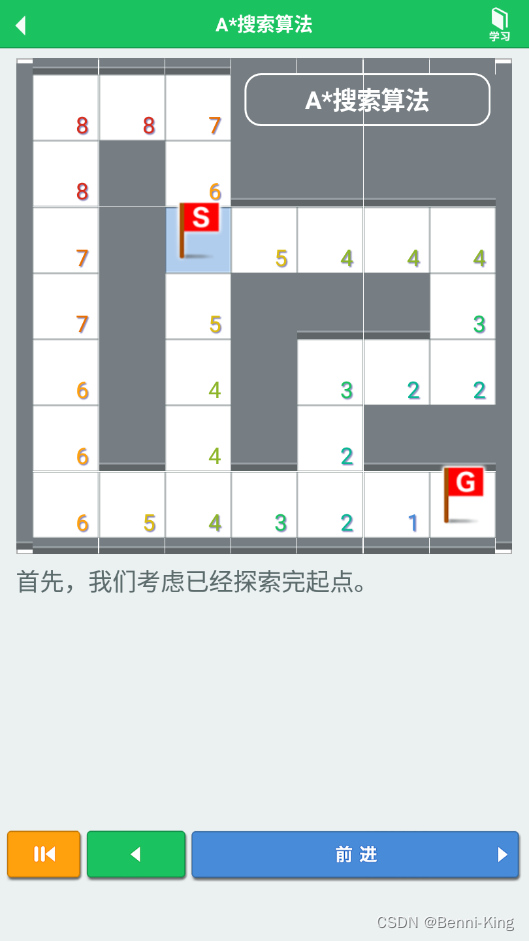
如果说我们的h,overestimate了,那可能会找出非最优解,甚至比其他算法更差,所以这种算法下不断调整h以找到最优解也是必须的,
关于代码,其实就是把贪心算法里面的距离目标的值加上当前权重的值,剩下的就和贪心算法的完全一样,取最小值的节点进行遍历
romanian_graph = {
'Arad': [('Zerind', 75), ('Sibiu', 140), ('Timisoara', 118)], # finish the remaining
'Zerind': [('Oradea', 71), ('Arad', 75)],
'Oradea': [('Zerind', 71), ('Sibiu', 151)],
'Sibiu': [('Fagaras', 99), ('Rimnicu Vilcea', 80), ('Oradea', 151), ('Arad', 140)],
'Timisoara': [('Lugoj', 111), ('Arad', 118)],
'Lugoj': [('Mehadia', 70), ('Timisoara', 111)],
'Mehadia': [('Drobeta', 75), ('Lugoj', 70)],
'Drobeta': [('Craiova', 120), ('Mehadia', 75)],
'Rimnicu Vilcea': [('Craiova', 146), ('Pitesti', 97), ('Sibiu', 80)],
'Fagaras': [('Sibiu', 99), ('Bucharest', 211)],
'Pitesti': [('Rimnicu Vilcea', 97), ('Craiova', 138), ('Bucharest', 101)],
'Craiova': [('Rimnicu Vilcea', 146), ('Drobeta', 120), ('Pitesti', 138)],
'Bucharest': [('Fagaras', 211), ('Pitesti', 101), ('Giurgiu', 90), ('Urzicenzi', 85)],
'Giurgiu': [('Bucharest', 90)],
'Urzicenzi': [('Bucharest', 85), ('Vaslui', 142), ('Hirsova', 98)],
'Vaslui': [('Urzicenzi', 142), ('Iasi', 92)],
'Iasi': [('Vaslui', 92), ('Neamt', 87)],
'Neamt': [('Iasi', 87)],
'Hirsova': [('Urzicenzi', 98), ('Eforie', 86)],
'Eforie': [('Hirsova', 86)],
}
def sld_to_bucharest(city):
"""This function returns the straight-line distance from the given city to Bucharest."""
sld = {
'Arad': 366,
'Bucharest': 0,
'Craiova': 160,
'Drobeta': 242,
'Eforie': 161,
'Fagaras': 176,
'Giurgiu': 77,
'Hirsova': 151,
'Iasi': 226,
'Lugoj': 244,
'Mehadia': 241,
'Neamt': 234,
'Oradea': 380,
'Pitesti': 100,
'Rimnicu Vilcea': 193,
'Sibiu': 253,
'Timisoara': 329,
'Urzicenzi': 80,
'Vaslui': 199,
'Zerind': 374
}
return sld[city]
def a_star_search(graph_to_search, initial_state, goal_state, heuristics_function, verbose=False):
# this is a list of a list because we need to eventually return
# the entire PATH from the initial state to the goal state. So,
# each element in this list represents a path from the the initial
# state to one frontier node. We use the first element in each path
# to represent the cost.
frontiers = [[0, initial_state]] # the frontier list only has the initial state, with a cost of 0.
visited = []
while len(frontiers) > 0: # use while loop to iteratively perform search
if verbose: # print out detailed information in each iteration
print('Frontiers (paths):')
for x in frontiers:
print(' -', x)
print('Visited:', visited)
print('\n')
# get the nodes in frontiers to be expanded
estimated_path_cost = []
for x in frontiers:
heuristic_value = heuristics_function(x[-1])
path_cost = x[0]
estimated_path_cost.append(heuristic_value+path_cost)
idx_to_pop = estimated_path_cost.index(min(estimated_path_cost))
path = frontiers.pop(idx_to_pop)
node = path[-1] # Get the last node in this path
if node == goal_state:
goal_path = path[1:]
goal_cost = path[0]
return goal_path, goal_cost
if node in visited: # check if we have expanded this node, if yes then skip this
continue
actions = graph_to_search[node] # get the possible actions
for next_node, next_cost in actions:
new_path = path.copy()
new_path.append(next_node)
new_path[0] = new_path[0] + next_cost
if next_node in visited or new_path in frontiers:
continue # skip this node if it is already in the frontiers or the visited list.
frontiers.append(new_path) # add to the frontiers
# after exploring all actions, we add this node to the visited list
visited.append(node)
return None
path, cost = a_star_search(romanian_graph, 'Arad', 'Bucharest', heuristics_function=sld_to_bucharest, verbose=False)
print('The solution is:', path)
print('The cost is:', cost)
若h过预估
如果h过预估,回导致找出来的路径可能不是最小值,大家可以试试用下面这个过预估的,就是把估计值都乘以2,试一下,出来的并不是最佳路径,没有正常情况下的好
def overestimate_sld_to_bucharest(city):
"""This function returns the straight-line distance from the given city to Bucharest."""
sld = {
'Arad': 366,
'Bucharest': 0,
'Craiova': 160,
'Drobeta': 242,
'Eforie': 161,
'Fagaras': 176,
'Giurgiu': 77,
'Hirsova': 151,
'Iasi': 226,
'Lugoj': 244,
'Mehadia': 241,
'Neamt': 234,
'Oradea': 380,
'Pitesti': 100,
'Rimnicu Vilcea': 193,
'Sibiu': 253,
'Timisoara': 329,
'Urzicenzi': 80,
'Vaslui': 199,
'Zerind': 374
}
return 2*sld[city]
一个挺好玩的网站,这上面有上述几种检索方式的代码可视化解析
检索方式可视化解析

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









