







前面学了那么多,我们还没有上手写过代码,现在我们来学习如何用flink实现流式的WordCount程序。
准备工作
- java开发环境,推荐Intellij IDEA。
- netcat程序。
- 如果是windows系统,可以到https://eternallybored.org/misc/netcat/网站下载netcat,并解压配好环境变量即可;
- 如果是centos系统,直接yum install -y nc即可;
- pom文件配置
<!-- Apache Flink dependencies --> <!-- These dependencies are provided, because they should not be packaged into the JAR file. --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_${scala.binary.version}</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients_${scala.binary.version}</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency> - log4j文件配置
rootLogger.level = INFO rootLogger.appenderRef.console.ref = ConsoleAppender appender.console.name = ConsoleAppender appender.console.type = CONSOLE appender.console.layout.type = PatternLayout appender.console.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
生成主类,简单测试
代码如下:
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class WordCountTest {
public static void main(String[] args) throws Exception {
// 1. 获取流任务执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置并行度为1
env.setParallelism(1);
// 2. 输入,这里使用了自带的socket输入,监听ip地址为hadoop001,端口号为9999
DataStream<String> source = env.socketTextStream("hadoop001", 9999);
// 3. 数据转换处理,这里暂时省略
// 4. 输出,这里使用了自带的控制台输出,因为没有数据处理过程,那就是直接将输入的字符串输出到控制台
source.print("input");
// 5. 执行流任务
env.execute("word count test");
}
}
整个代码分为5部分:
- 获取流任务执行环境
- 获取数据输入
- 数据转换处理
- 数据输出
- 启动流任务
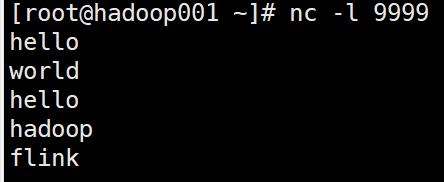
我们启动下socket输入,在shell中输入nc -l 9999,如下:

然后再ide中启动程序,

可以看到最后一行,连接到了hadoop001:9999,在等待输入。
我们回到刚刚输入nc -l 9999的shell,输入"hello",“world”,“hello”,“hadoop”,“flink”,如图:
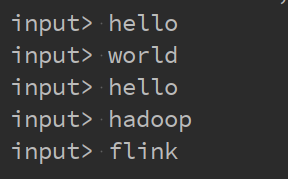
回到ide中,可以看到输出如下:
好,到这里都符合我们的预期。接下来我们再进一步,实现WordCount。
WordCount实现
实现WordCount的主要逻辑如下:
- 获取word
- 将word转换为(word, 1)
- 对数据按照word分组
- 对分组后的数据按后面的count数汇总
代码如下:
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class WordCountTest {
public static void main(String[] args) throws Exception {
// 1. 获取流任务执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置并行度为1
env.setParallelism(1);
// 2. 输入,这里使用了自带的socket输入,监听ip地址为hadoop001,端口号为9999
DataStream<String> source = env.socketTextStream("hadoop001", 9999);
// 3. 数据转换处理
DataStream<Tuple2<String, Integer>> counted = source
// 将word转换为(word, 1)
.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String word) throws Exception {
return Tuple2.of(word, 1);
}
})
// 对数据按照word分组
.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> record) throws Exception {
return record.f0;
}
})
// 对分组后的数据按后面的count数汇总
.sum(1)
;
// 4. 输出,这里使用了自带的控制台输出,将结果输出到控制台
counted .print("output");
// 5. 执行流任务
env.execute("word count test");
}
}
我们再次开启nc,启动程序,输入"hello",“world”,“hello”,“hadoop”,“flink”,可以看到结果输出如下:
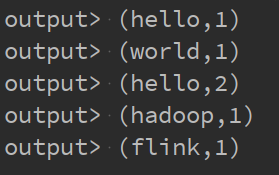
每输入一个word,就会对这个word统计一次,输入两个hello的时候,结果输出了(hello,2),而其它word只输入了一次,所以都是1。















 769
769











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









