






标题:LiStereo: Generate Dense Depth Maps from LIDAR and Stereo Imagery
作者:Junming Zhang, Manikandasriram Srinivasan Ramanagopal, Ram V asudevan and Matthew Johnson-Roberson
来源:2020 IEEE International Conference on Robotics and Automation (ICRA)
编译:姚潘涛
审核:柴毅,王靖淇
本文转自泡泡机器人SLAM

摘要

准确的环境深度图对于自主机器人和车辆的安全运行至关重要。当前,使用激光雷达(LIDAR)或双目匹配算法来获取这种深度信息。但是,高分辨率激光雷达价格昂贵,并且在大范围内会产生稀疏的深度图。双目匹配算法能够生成更密集的深度图,但在远距离上通常不如LIDAR准确。本文将这些方法结合在一起以生成高质量的密集深度图。与以前使用真值标签进行训练的方法不同,该模型采用了自我监督的训练过程。实验表明,所提出的方法能够生成高质量的密集深度图,并且即使在低分辨率输入下也能稳定运行。这显示了通过将较低分辨率的激光雷达与双目系统配合使用并保持高分辨率的同时,可以降低成本的潜力。

贡献

提出了一个模型,该模型以双目图像和LIDAR导出的稀疏深度图为输入,并输出准确的密集深度图。
可以以自我监督的方式训练提出的模型,从而避免了收集大量地面真相标签的成本。
实验表明,就较稀疏的输入深度图而言,双目图像优于单目图像,并且可以通过使用分辨率较低的LIDAR来降低成本。
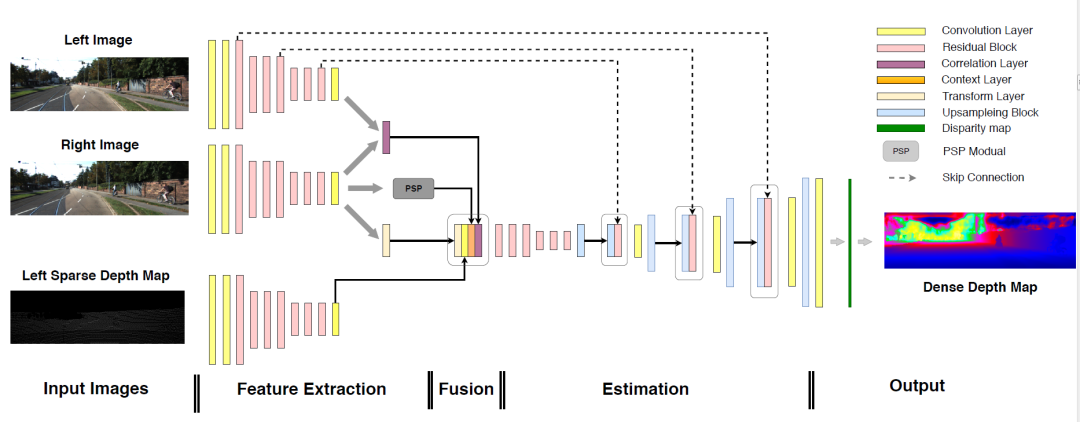
图1 提出的模型的体系结构。我们模型的管道包括以下部分。(a)输入:校正后的立体图像和相应的左稀疏深度图。(b)特征提取:从双目图像和稀疏深度图中提取特征。相关层计算从一侧到另一侧的相关性。左侧的彩色图像中的特征由转换层处理,以为以后的传感器融合做准备。PSP模块用于合并更多上下文信息。(c)融合:通过级联融合深度图的相关信息和特征。(d)估计:处理融合信息以执行深度估计。(e)输出:生成密集的深度图和视差图。输出深度图被着色以更好地显示。
表1 与其他在KITTI基准深度完成任务上受监督的方法进行比较。“ LiStereo”是指以立体图像为输入的建议模型。“ LiMono”是指拍摄单眼图像的模型。“测试集”是指在KITTI测试集上报告的结果。“分割测试集”是指根据第4.1节中介绍的KITTI验证集在分割测试集上报告的结果。“ with GT”是指使用地面真实标签的训练模型。对于立体信息,我们提出的方法优于仅具有单眼信息的模型。
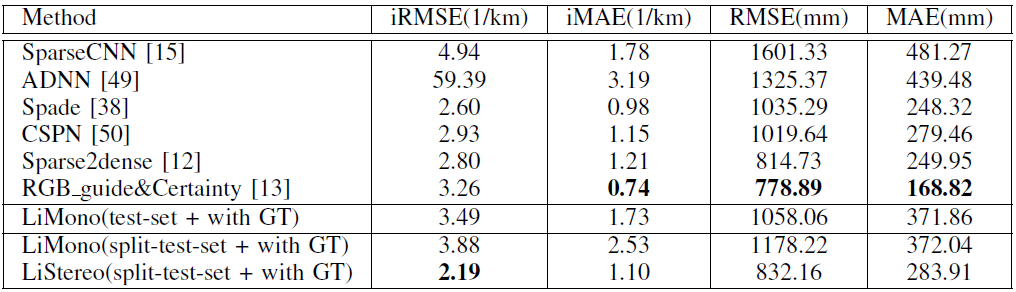
表2 与其他自我监督方法在KITTI基准深度完成任务上的比较。“ LiStereo”是指以立体图像为输入的建议模型。“测试集”是指在KITTI测试集上报告的结果。“分割测试集”是指根据第4.1节中介绍的KITTI验证集在分割测试集上报告的结果。“无GT”是指自我监督训练方式的训练模型。利用立体信息,我们提出的方法优于使用时间帧训练的Sparse2Dense。Sparse2Dense在拆分测试集和测试集上的类似结果证明了我们在第4.1节中介绍的拆分验证集策略的合理性。

表3 损耗权重的消融研究。光度损失确实有助于完成稀疏输入的深度,将β= 0和β= 0.5时的RMSE从1970mm减小到1277mm。但是,过多的光度损失会使结果变得更糟。α= 1,γ= 0.01,β= 0.5的模型获得最低的RMSE。

表4 常规卷积和稀疏不变卷积的消融研究。所有型号均以立体图像作为输入。“转化”是指使用常规卷积层的模型。“稀疏转换”是指将常规卷积层替换为LIDAR分支中的稀疏不变卷积层的模型。“ with GT”是指使用地面真实标签训练的模型。“无GT”是指以自我监督的方式训练的模型。结果报告在第4.1节介绍的拆分测试集中。就RMSE而言,它显示出规则卷积比稀疏不变卷积更好的结果。


图2 不同级别的输入稀疏性的定性结果。该模型以自我监督的方式进行训练。从左到右:对应的左彩色图像,原始稀疏深度图的预测密集深度图,稀疏度为0.1的输入预测的密集深度图,稀疏度输入为0.01的预测密集的深度图。输入更密集时,将显示更多详细信息。
表5 训练期间不同级别的输入稀疏度上的误差。报告了监督模型和自我监督模型的RMSE(mm)。表格中的稀疏度(LoS)表示从原始深度图采样的有效像素的比率。


图3 在训练和推理过程中,不同级别的输入稀疏性上的误差。X轴表示输入稀疏度,Y轴表示RMSE(mm)。“ LiStereo”是指我们提出的模型。“ LiMono”是指将单目图像作为输入的模型。“ Sparse2Dense”是指[12]提出的模型。“不带GT”是指以自我监督的方式训练模型,“带GT”是指使用地面真相标签训练的模型。(a)训练中的误差。根据第4.1节中介绍的拆分验证集评估结果。对于图中的每个数据点,使用X轴指定的某些输入稀疏度对模型进行训练和评估。(b)推论过程中的错误。根据第4.1节中介绍的拆分验证集评估模型。我们使用原始深度图训练模型,但是在推理过程中以不同的稀疏度输入输入深度图。稀疏2密度的结果是通过使用[12]中已发布的预训练模型获得的。这两张图都表明,我们提出的模型对于稀疏输入具有鲁棒性,并且具有拍摄从低分辨率激光雷达生成的深度图的潜力。
本文仅做学术分享,如有侵权,请联系删文。
下载1
在「3D视觉工坊」公众号后台回复:3D视觉,即可下载 3D视觉相关资料干货,涉及相机标定、三维重建、立体视觉、SLAM、深度学习、点云后处理、多视图几何等方向。
下载2
在「3D视觉工坊」公众号后台回复:3D视觉github资源汇总,即可下载包括结构光、标定源码、缺陷检测源码、深度估计与深度补全源码、点云处理相关源码、立体匹配源码、单目、双目3D检测、基于点云的3D检测、6D姿态估计源码汇总等。
下载3
在「3D视觉工坊」公众号后台回复:相机标定,即可下载独家相机标定学习课件与视频网址;后台回复:立体匹配,即可下载独家立体匹配学习课件与视频网址。
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的知识点汇总、入门进阶学习路线、最新paper分享、疑问解答四个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近3000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、可答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~ 


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









