






来源丨机器之心
作者丨小舟、陈萍
这么美的照片竟然不是出自摄影师之手?!
在 2019 年举办的 GTC 大会上,英伟达展示了一款新的交互应用 GauGAN:利用生成对抗网络(GAN)将分割图转换为栩栩如生的图像。
时隔 2 年,英伟达官方推出了 GauGAN 的继任者 GauGAN2,允许用户创建不存在的逼真风景图像。GauGAN2 将分割映射、修复和文本到图像生成等技术结合在一个工具中,旨在输入文字和简单的绘图就能创建逼真的图像。
英伟达表示:「与类似的图像生成模型相比,GauGAN2 的神经网络能够产生更多种类和更高质量的图像。」用户无需绘制想象场景的每个元素,只需输入一个简短的短语即可快速生成图像的关键特征和主题。
例如输入「海浪打在岩石上」,模型会根据生成的内容逐渐进行相应的调整,以生成与描述匹配的逼真图像。
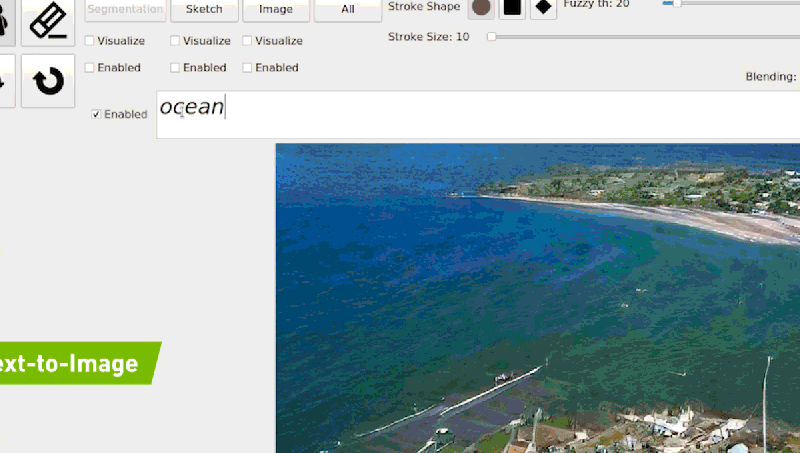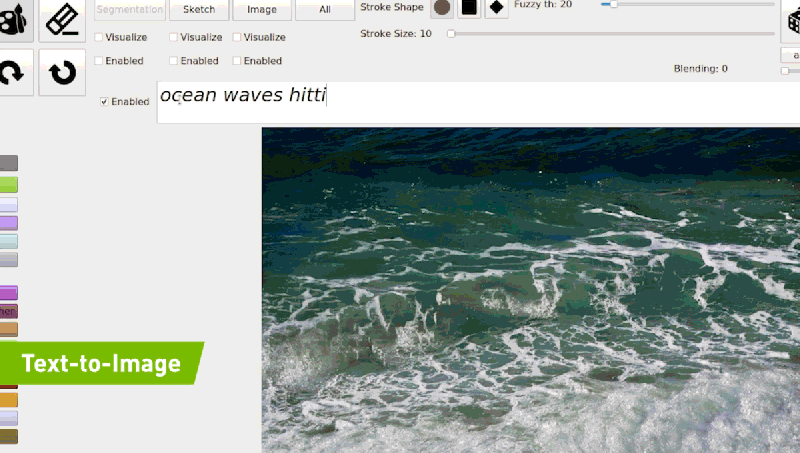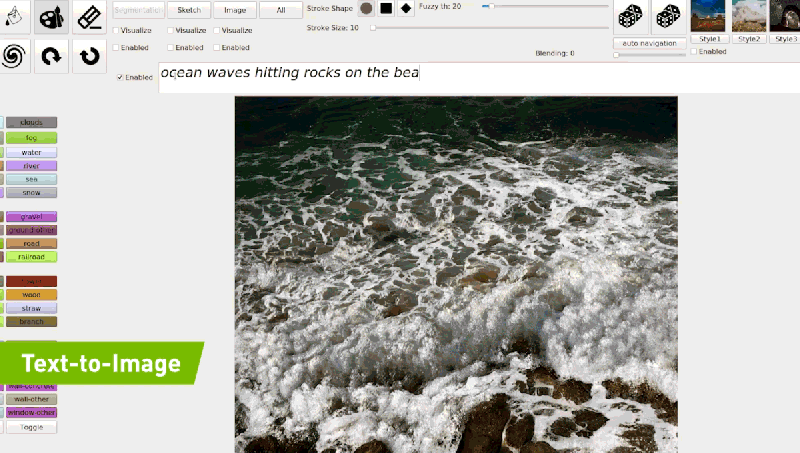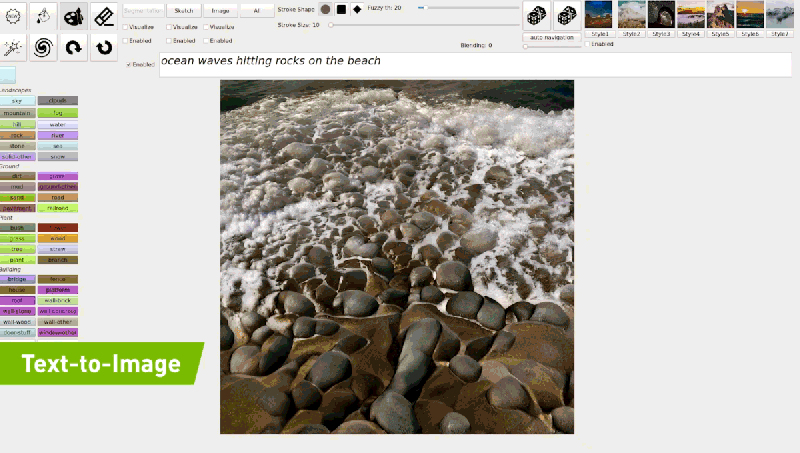
目前 GauGAN2 还在研发阶段,但英伟达已为用户提供了一个 demo 地址,可在线试玩。
试玩地址:https://www.nvidia.com/en-us/research/ai-demos/
简单输入几个关键词就能生成想要的风景图,看起来非常有趣。
GauGAN2 的生成模式
GauGAN2 现在有几种模式,可以从不同的输入生成逼真的图像。
模式 1:输入简笔画。
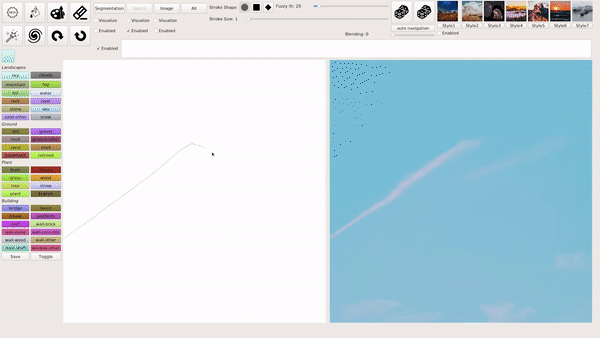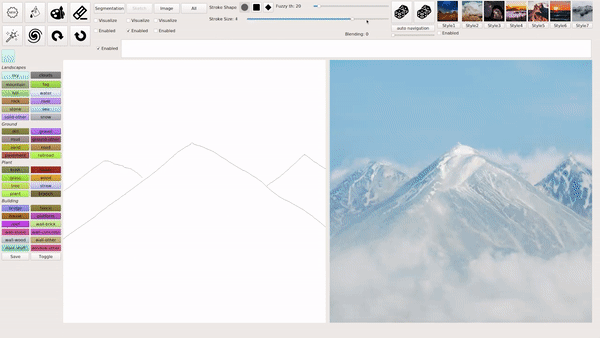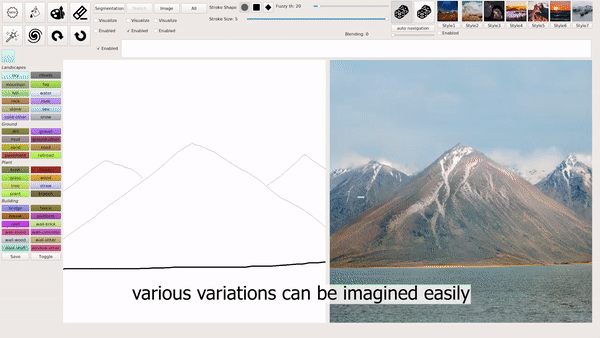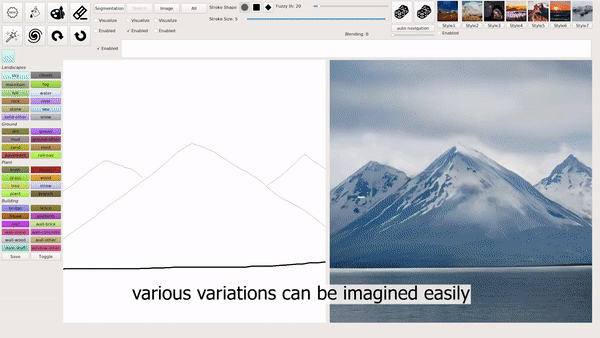
模式 2:输入文本。
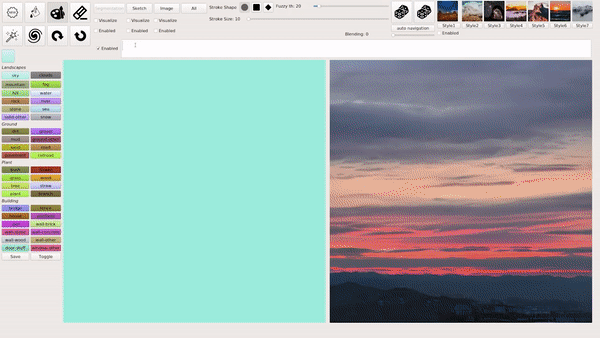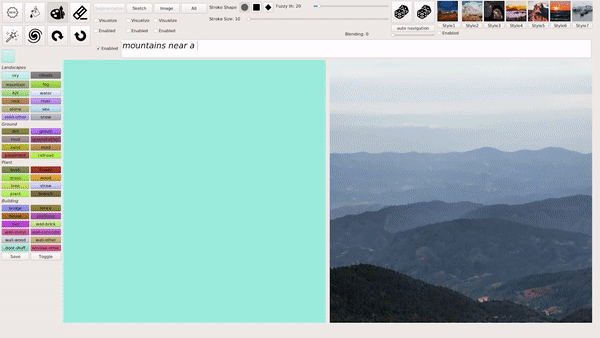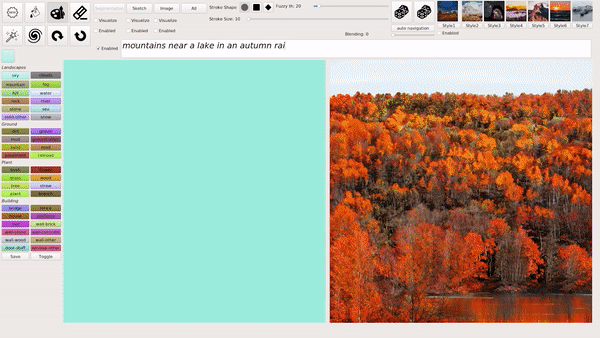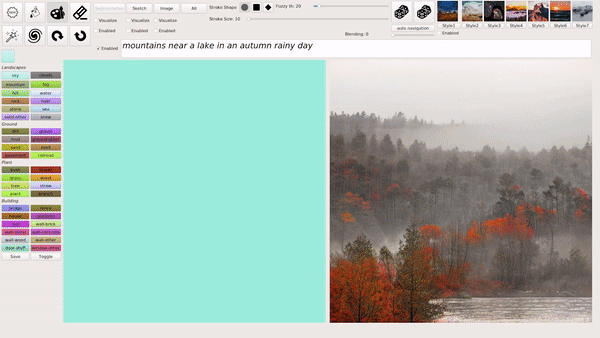
这种输入文本生成匹配图像的模式也是 GauGAN2 主要的创新,生成的图像会根据逐渐输入的文本不断发生变化,最终生成和文本匹配最佳的图像。
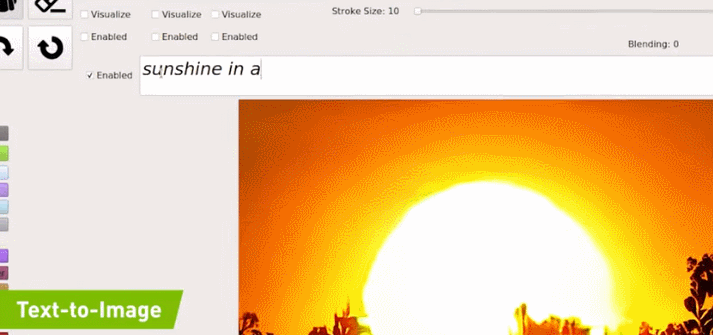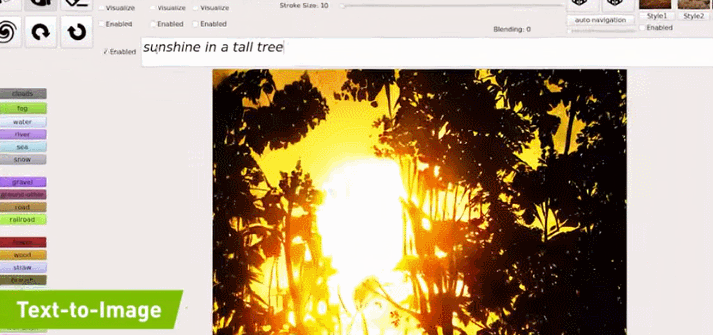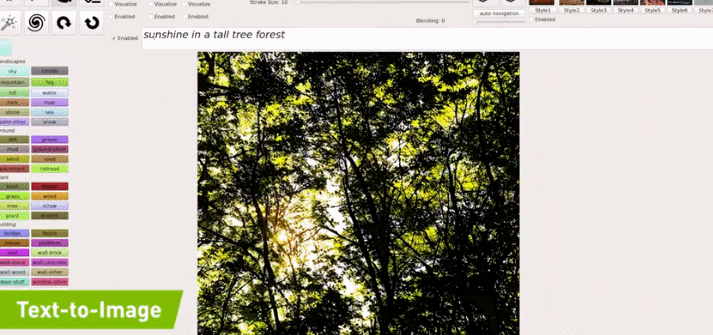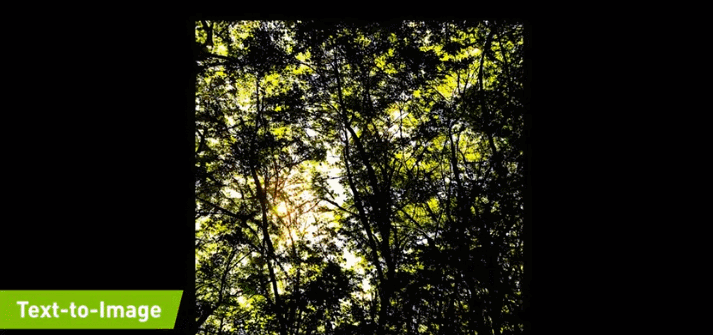
例如在下图的示例中,文本首先输入「sunshine(阳光)」,生成的图像中就只出现了一个太阳;之后继续输入「a tall tree(高树)」,图像中就出现了树(且为顶部树枝,匹配「高树」);最后,输入的全部文本是「sunshine in a tall tree forest」,意为「透过森林的阳光」,GauGAN2 最终生成的图像与之相匹配:
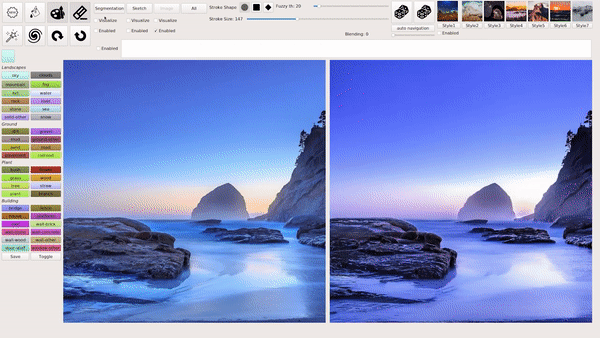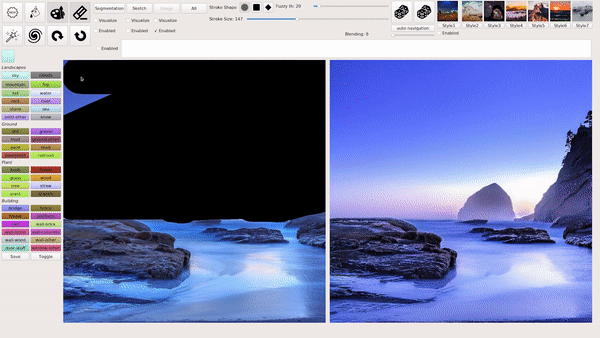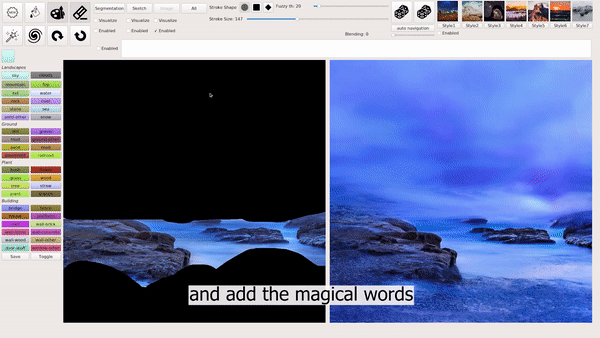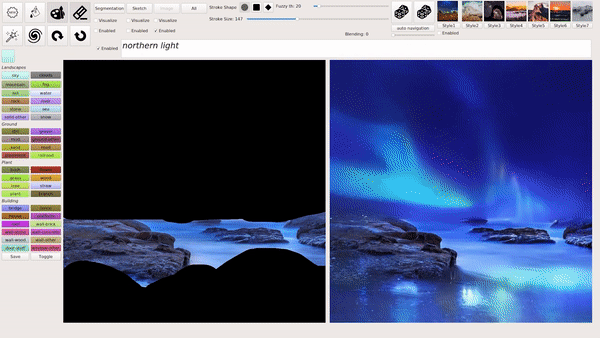
模式 3:输入图像并编辑部分内容。
例如,抹掉想要移除的内容,在生成的图像中会保留剩余的部分,并自动补全出多种新的完整图像:
此外,第一版 GauGAN 的涂鸦模式在 GauGAN2 也同样适用。
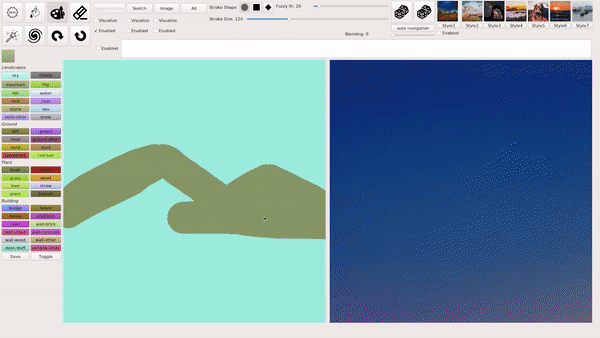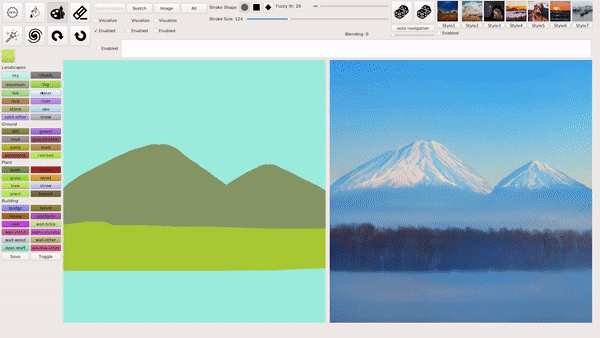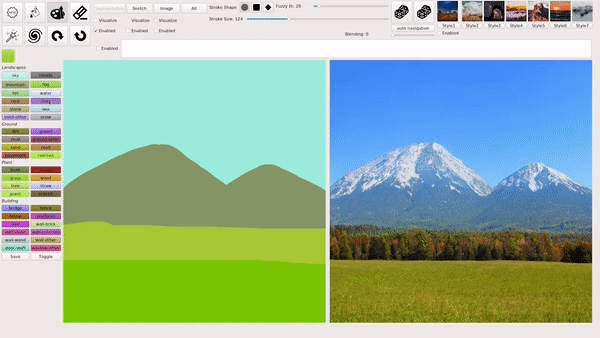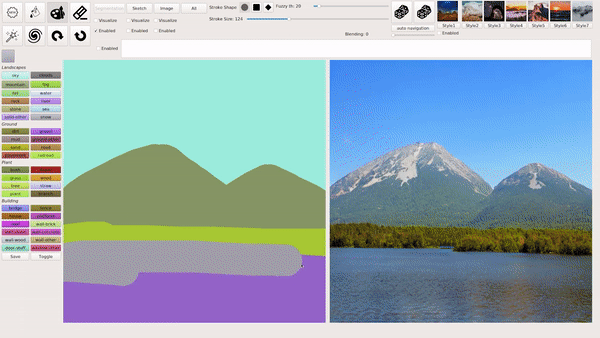
上述几种模式也可以混合叠加使用,例如在用涂鸦绘画等生成图像后,输入文本进行相应的修改,下图就生成了一座阳光下的「空中楼阁」:
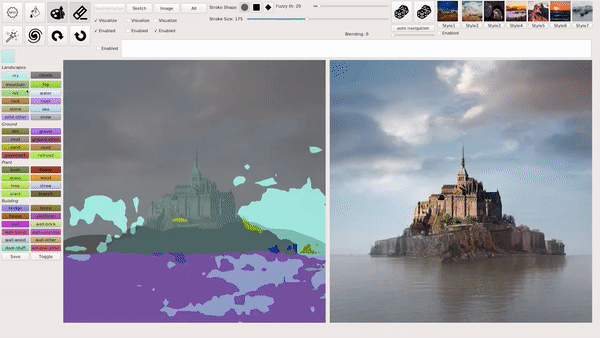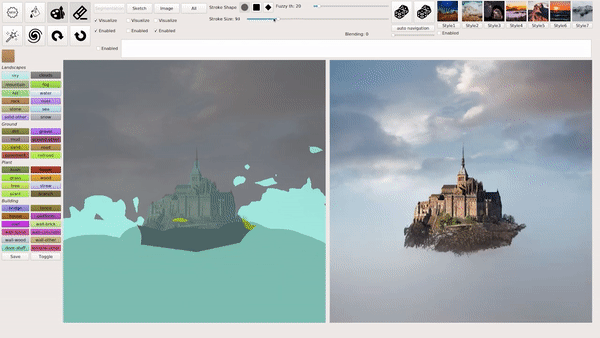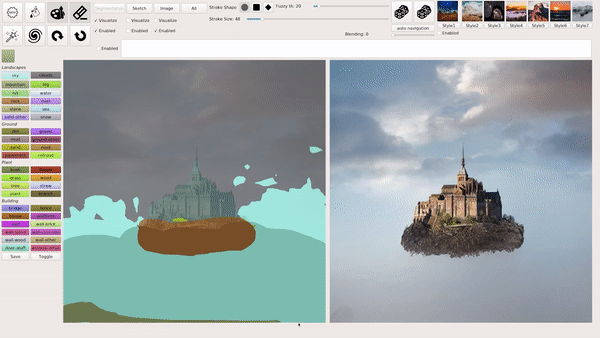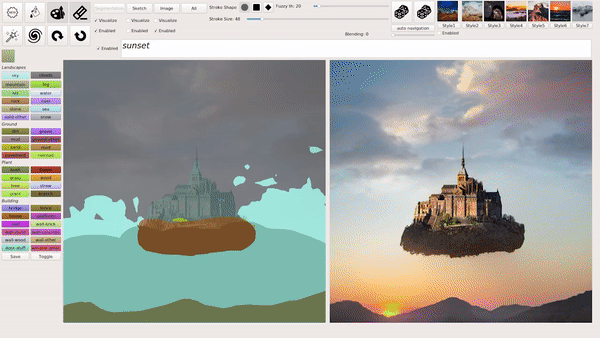
从文本生成图像,如何实现?
从 2019 年开始,英伟达开始改进 GauGAN 系统,该系统由超过一百万个公共 Flickr 图像训练而成。与 GauGAN 一样,GauGAN2 可以理解雪、树、水、花、灌木、丘陵和山脉等物体之间的关系,例如降水类型随季节变化的事实。
GauGAN2 作为生成对抗网络 (GAN) 的一种变体,由生成器和鉴别器组成。生成器用于获取样本,例如获取与文本配对的图像,并预测可能与图片中元素(例如山水、树木)对应的数据。生成器试图通过「欺骗」鉴别器来进行训练,鉴别器则用于评估预测结果是否真实。虽然 GAN 的转换最初质量很差,但它随着鉴别器的反馈而不断改进。
与 GauGAN 不同的是,GauGAN2 是在 1000 万张图像上训练而成——可以将自然语言描述转换成风景图。GauGAN2 在单个模型中结合了分割映射、修复和文本到图像的生成。它不仅可以创建逼真的图像,艺术家还可以使用它来描绘超凡脱俗的风景,即实际中并不存在的艺术场景。
例如星球大战系列中塔图因星有两个太阳。借助 GauGAN2 只需输入文本「desert hills sun」来创建一个起点,之后用户可在已有一个太阳的情况下快速绘制草图,生成想要的效果。
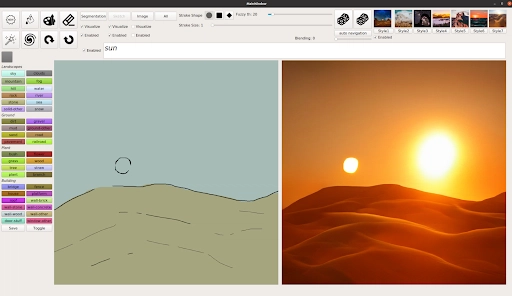
这是一个迭代的过程,用户在文本框中键入的每个词都会为 AI 创建的图像添加更多内容,因而 GauGAN2 才能随着输入文本而不断变换图像。
GauGAN2 背后的 AI 模型使用 NVIDIA Selene 超级计算机,在 1000 万张高质量风景图像上进行了训练,这是一个 NVIDIA DGX SuperPOD 系统,是世界上最强大的 10 台超级计算机之一。GauGAN2 还借助神经网络来学习词汇与其对应的视觉效果之间的联系,例如「冬天」、「有雾」等。
面向实际应用
GauGAN2 从实用的角度讲是视觉创意生成器,在电影、软件、视频游戏、产品、时尚和室内设计中具有潜在应用。英伟达声称第一版 GauGAN 已被用于为电影和视频游戏创建概念艺术。类似地,GauGAN2 未来也将提供开源代码并投入应用。
与 GauGAN2 类似,今年年初 OpenAI 发布了号称图像版 GPT-3、120 亿参数的 DALL-E,后者可以将以自然语言形式表达的大量概念转换为合适的图像,效果十分惊艳。
此类生成模型的一个缺点是可能存在偏见。例如在 DALL-E 中,OpenAI 使用 CLIP 模型来提高生成图像质量,但几个月前有研究发现 CLIP 存在种族和性别偏见问题。
英伟达暂不会对 GauGAN2 是否存在偏见给出回应。英伟达发言人表示:「该模型有超过 1 亿个参数,训练时间不到一个月(还在 demo 阶段),训练图像来自专有的风景图像数据集。因此 GauGAN2 只专注于风景,研究团队还对图像进行审核以确保图片中没有包含人的场景。」这将有助于减少 GauGAN2 的偏见。
参考链接:https://blogs.nvidia.com/blog/2021/11/22/gaugan2-ai-art-demo/
本文仅做学术分享,如有侵权,请联系删文。
3D视觉精品课程推荐:
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进
4.国内首个面向工业级实战的点云处理课程
5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、可答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









