






0深度学习最令人兴奋的应用之一是智能照片美化,例如为黑白图像着色、破损图片修复以及去模糊等。
以黑白图像着色为例,通过将 AI 与照片着色相结合,即使不会使用Photoshop 等图片编辑工具,为黑白照片着色也可以一键完成。

这具体是如何实现的?下面就来告诉你!
1
颜色空间
当我们加载图像时,会得到一个3维(高度、宽度、颜色通道)数组,其中颜色通道的数据代表 RGB 颜色空间中的颜色,每个像素都有 3 个数字,表示该像素的红色、绿色和蓝色值。
在图1中,最左侧为原始图像,右边分别为红色、绿色和蓝色通道。为图片着色时,根据给定的黑白图片,需要判断每个位置的像素的RGB值分别是多少,颜色取值范围是0~255,即每个像素都存在一个256³ 的预测问题。

图1
CIE1976L*a*b*颜色空间,是1976年由国际照明学会(CIE)推荐的均匀色空间。该空间是三维直角坐标系统,以明度L*和色度坐标a*、b*来表示颜色在色空间中的位置。L*表示颜色的明度,此通道显示为黑白图像;a*正值表示偏红,负值表示偏绿;b*正值表示偏黄,负值表示偏蓝。图2表示L*a*b*颜色空间的每个通道。

图2
使用L*a*b*颜色空间为照片着色,为着色模型输入L* 通道,输出其他两个通道(a*,b*)的预测,其选择大约有 65000 个,远小于RGB颜色空间,因此我们可以选择使用L*a*b*颜色空间的数据作为照片着色模型的训练数据。
2
生成对抗网络
GAN(Generative Adversarial Networks,生成对抗网络)是生成模型的一种。
GAN网络结构中包含两个模型:“生成器”模型和“判别器”模型,“生成器”用来生成数据,“判别器”对数据的真伪进行判别。
在GAN模型训练时,如果把“生成器”看成是一个伪造名画的画家,那么“判别器”就是一个名画鉴别家。
初始阶段“生成器”技艺拙劣,伪造的名画非常轻易的被“判别器”识别为假画。“生成器”根据判别依据对自身造假能力进行提升。经过一段时间的“修炼”,“生成器”再次把伪造的名画交给“判别器”,“判别器”无法辨别真伪,于是学习更复杂的辨别技能,直到可以识别出伪造的名画。
接下来,“生成器”和“判别器”重复以上过程,进行新一轮学习。
"生成器"和“判别器”就是在一种对抗的状态中相互博弈、学习、成长,直到在规定条件下“判别器”无法判别“生成器”生成数据的真伪。
使用GAN实现照片着色,模型结构如图3所示。

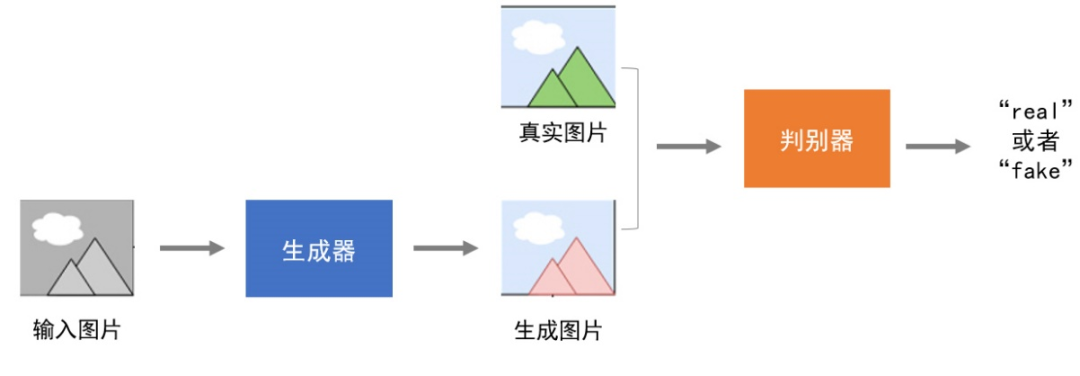
图3
使用来自 COCO数据集的 8,000 张图像进行训练,每轮训练时长约4分钟左右,经过100轮后,生成效果如图4所示。

图4
模型对图像中一些最常见的物体能够完成基本着色,例如天空、树木等,但无法为稀有物体着色。同时,还存在一些颜色溢出和圆形颜色块,着色效果不理想。
因此,需要改变我们的策略!
3
自注意力生成对抗网络
在介绍新的解决方案之前先来区分两个概念:着色和恢复。
着色严格来说是将照片从单色变为可信的颜色,着色是一个“不受约束”的问题,很多东西(例如衣服)没有一种准确的颜色。因此着色是一个艺术创作的过程,神经网络对此很难做到令人满意。
恢复是替换图片中的丢失和损失,使图片变得完整如新。恢复中解决褪色问题在没有原始参照物的情况下,等同于着色,都是不受约束的艺术创作。
综上所述,在评估着色和恢复效果时,如果人们看到生成的图片时无法觉察出图片被处理过,并且能从中感到愉悦,则认为着色和恢复工作完成。
那么新的着色策略是什么呢?
“生成器”采用与U-Net结构类似的U形神经网络,如图5所示。
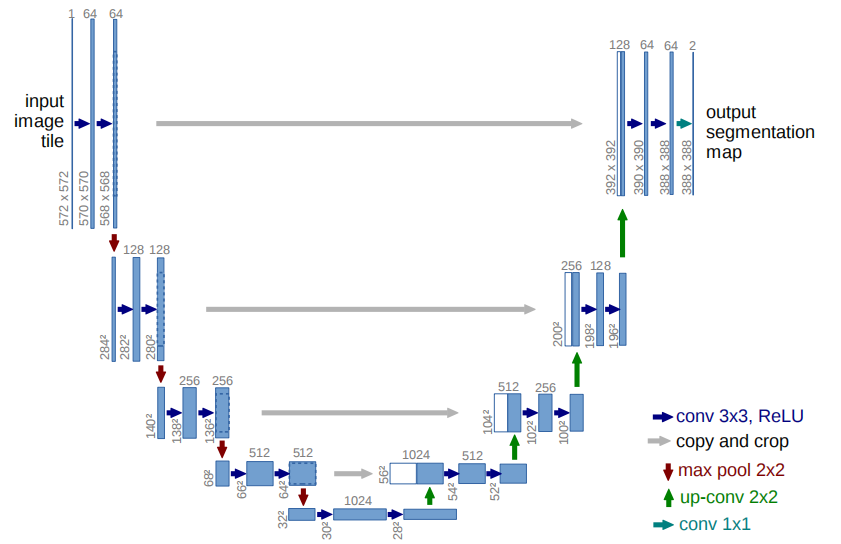
图5
为此“生成器”输入灰度图,左侧提取图像特征对内容进行识别,右侧根据内容识别结果还原并对结果进行着色。
“判别器”使用Critic卷积神经网络,它在输出层是卷积而不是线性层,它很大(宽),但很简单。它输入图像,输出一个分数值,表示真实度。
新的解决方案中最重要的就是Self-Attention GAN(自注意力生成对抗网络)的应用,把注意力机制放到“生成器”和“判别器”中。
使用基础GAN生成图像的细节把控不好,原因主要是使用卷积神经网络的图像生成,基本上都是依据局部感受野,以局部感受为主,缺少全局或其他信息,因此只在低分辨率中以点状的形式生成高分辨率细节。
如图6所示,对于花朵的着色存在不均匀的问题,其他地方也出现了错误的颜色。

图6
自注意力机制在模拟远程依赖性的能力、计算效率和统计效率之间展现出更好的平衡。自注意力机制将所有位置处的特征的加权和作为该位置的响应,其中权重 (或注意向量 ) 仅以较小的计算成本来计算。
Self-Attention GAN将Self-Attention机制引入卷积GAN,可以很好的处理长范围、多层次的依赖,生成图像时很好地协调每一个位置的细节和远端的细节,“判别器”还可以更准确地对全局图像结构实施复杂的几何约束。
以下是一些生成案例。
1)奥黛丽·赫本

图7
2)冬季马路上骑车的人

 图8
图8
3)花

 图9
图9
4)草地上的小狗

 图-10
图-10
5)中国江南水乡

 图11
图11
虽然有的生成图片中还存在一些异常,例如奥黛丽·赫本的耳朵后面皮肤颜色,但是整体效果已经非常不错,注意力层在颜色的一致性和总体质量上的表现有很大的惊喜。
除了自动着色,图像超分辨率、去模糊等也是 GAN 的重要关注领域。
图像超分辨率可以通过上采样从低分辨率图像生成高分辨率图像,图像去模糊中“生成器”用于生成清晰图像,以下是部分基于GAN的去模糊案例。

图12

图13
日前,由达内教育创始人、董事长韩少云,达内教育集团技术研发副总裁、AI研究院院长郑政等联合编著的《计算机视觉应用与实战》正式发售,其中就详细讲解了以上技术。
这是达内教育“人工智能应用与实战系列”教材的第一本书籍,致力于帮助读者快速掌握计算机视觉的实战技能,为高薪就业加码。

《计算机视觉应用与实战》主要围绕计算机视觉在农业、医学、工业等领域的案例,如植物病虫害检测、眼底血管图像分割、口罩佩戴检测等进行讲解,理论结合实际,采用大量插图,辅以实例,可以帮助读者快速理解计算机视觉若干模型和算法的基本原理与关键技术。
此外,《计算机视觉应用与实战》中的理论知识与实践的重点和难点部分均采用微视频的方式进行解读,可以降低读者的学习成本,高效领会核心要素。
据《人工智能就业数据图鉴》报告显示,人工智能行业仍处在人才求职竞争蓝海,热招岗位Top 100中,技术岗和非技术岗占比是6:4,对于非人工智能相关专业的求职者,仍有进入人工智能行业的机遇和空间。
截止目前,达内教育已累计帮助超过100万学员成功进入国内外知名的IT互联网企业就职。作为专业学习和参考用书,《计算机视觉应用与实战》是初学者了解人工智能通用性知识、高效掌握实操性技能的媒介!

快快扫码抢购吧!
免费送书啦!
在文章底部留言,即可参加活动
留言获赞最高前五名粉丝将各赠一本
《计算机视觉应用与实战》
包邮到家
开奖时间:6月26日晚八点
本文仅做学术分享,如有侵权,请联系删文。
3D视觉精品课程推荐:
1.面向自动驾驶领域的多传感器数据融合技术
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进
4.国内首个面向工业级实战的点云处理课程
5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)9.从零搭建一套结构光3D重建系统[理论+源码+实践]
10.单目深度估计方法:算法梳理与代码实现11.自动驾驶中的深度学习模型部署实战12.相机模型与标定(单目+双目+鱼眼)13.重磅!四旋翼飞行器:算法与实战14.ROS2从入门到精通:理论与实战
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。
▲长按加微信群或投稿
▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款
圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~













 13万+
13万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









