






来源丨DeepHub IMBA
编辑丨AIoT工业检测
点击进入—>3D视觉工坊学习交流群
GPU 计算与 CPU 相比能够快多少?在本文中,我将使用 Python 和 PyTorch 线性变换函数对其进行测试。
以下是测试机配置:
CPU:英特尔 i7 6700k (4c/8t) GPU:RTX 3070 TI(6,144 个 CUDA 核心和 192 个 Tensor 核心) 内存:32G 操作系统:Windows 10。
无论是cpu和显卡都是目前常见的配置,并不是顶配(等4090能够正常发货后我们会给出目前顶配的测试结果)。
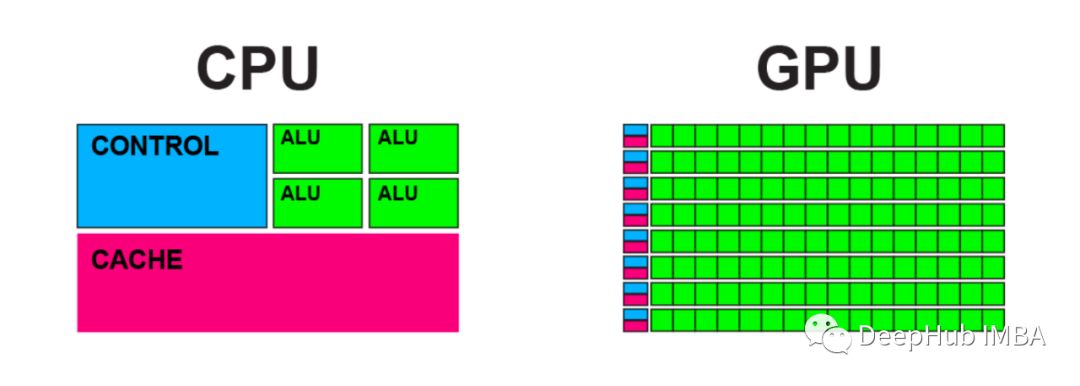
NVIDIA GPU 术语解释
CUDA 是Compute Unified Device Architecture的缩写。可以使用 CUDA 直接访问 NVIDIA GPU 指令集,与专门为构建游戏引擎而设计的 DirectX 和 OpenGL 不同,CUDA 不需要用户理解复杂的图形编程语言。但是需要说明的是CUDA为N卡独有,所以这就是为什么A卡对于深度学习不友好的原因之一。
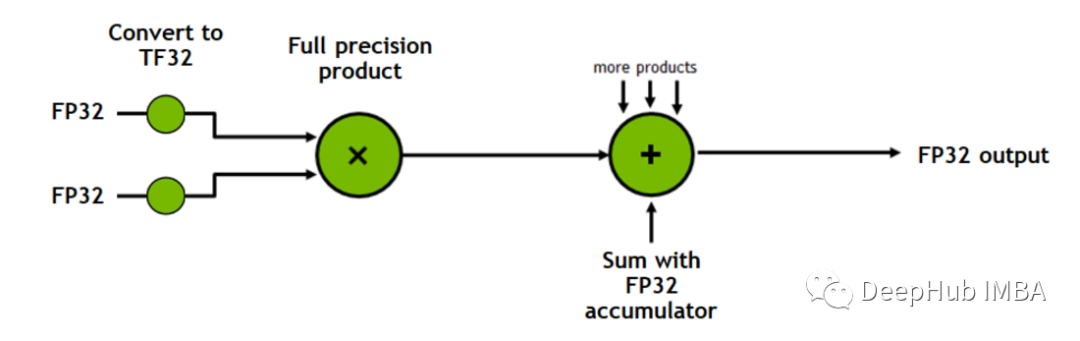
Tensor Cores是加速矩阵乘法过程的处理单元。
例如,使用 CPU 或 CUDA 将两个 4×4 矩阵相乘涉及 64 次乘法和 48 次加法,每个时钟周期一次操作,而Tensor Cores每个时钟周期可以执行多个操作。

上面的图来自 Nvidia 官方对 Tensor Cores 进行的介绍视频
CUDA 核心和 Tensor 核心之间有什么关系?Tensor Cores 内置在 CUDA 核心中,当满足某些条件时,就会触发这些核心的操作。
测试方法
GPU的计算速度仅在某些典型场景下比CPU快。在其他的一般情况下,GPU的计算速度可能比CPU慢!但是CUDA在机器学习和深度学习中被广泛使用,因为它在并行矩阵乘法和加法方面特别出色。
上面的操作就是我们常见的线性操作,公式是这个
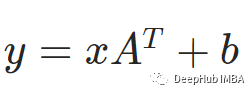
这就是PyTorch的线性函数torch.nn.Linear的操作。可以通过以下代码将2x2矩阵转换为2x3矩阵:
import torch
in_row,in_f,out_f = 2,2,3
tensor = torch.randn(in_row,in_f)
l_trans = torch.nn.Linear(in_f,out_f)
print(l_trans(tensor))CPU 基线测试
在测量 GPU 性能之前,我需要线测试 CPU 的基准性能。
为了给让芯片满载和延长运行时间,我增加了in_row、in_f、out_f个数,也设置了循环操作10000次。
import torch
import torch.nn
import timein_row, in_f, out_f = 256, 1024, 2048
loop_times = 10000现在,让我们看看CPU完成10000个转换需要多少秒:
s = time.time()
tensor = torch.randn(in_row, in_f).to('cpu')
l_trans = torch.nn.Linear(in_f, out_f).to('cpu')
for _ in range(loop_times):
l_trans(tensor)
print('cpu take time:',time.time()-s)
#cpu take time: 55.70971965789795可以看到cpu花费55秒。
GPU计算
为了让GPU的CUDA执行相同的计算,我只需将. To (' cpu ')替换为. cuda()。另外,考虑到CUDA中的操作是异步的,我们还需要添加一个同步语句,以确保在所有CUDA任务完成后打印使用的时间。
s = time.time()
tensor = torch.randn(in_row, in_f).cuda()
l_trans = torch.nn.Linear(in_f, out_f).cuda()
for _ in range(loop_times):
l_trans(tensor)
torch.cuda.synchronize()
print('CUDA take time:',time.time()-s)
#CUDA take time: 1.327127456665039并行运算只用了1.3秒,几乎是CPU运行速度的42倍。这就是为什么一个在CPU上需要几天训练的模型现在在GPU上只需要几个小时。因为并行的简单计算是GPU的强项。
如何使用Tensor Cores
CUDA已经很快了,那么如何启用RTX 3070Ti的197Tensor Cores?启用后是否会更快呢?在PyTorch中我们需要做的是减少浮点精度从FP32到FP16,也就是我们说的半精度或者叫混合精度:
s = time.time()
tensor = torch.randn(in_row, in_f).cuda().half()
layer = torch.nn.Linear(in_f, out_f).cuda().half()
for _ in range(loop_times):
layer(tensor)
torch.cuda.synchronize()
print('CUDA with tensor cores take time:',time.time()-s)
#CUDA with tensor cores take time:0.5381264686584473又是2.6倍的提升。
总结
在本文中,通过在CPU、GPU CUDA和GPU CUDA +Tensor Cores中调用PyTorch线性转换函数来比较线性转换操作。下面是一个总结的结果:
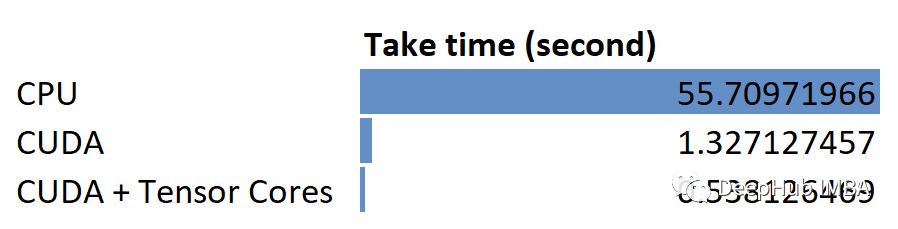
NVIDIA的CUDA和Tensor Cores确实大大提高了矩阵乘法的性能。
后面我们会有两个方向的更新:
1、介绍一些简单的CUDA操作(通过Numba),这样可以让我们了解一些细节。
2、我们会在拿到4090后发布一个专门针对深度学习的评测,这样可以方便大家选择购买。
本文仅做学术分享,如有侵权,请联系删文。
点击进入—>3D视觉工坊学习交流群
干货下载与学习
后台回复:巴塞罗那自治大学课件,即可下载国外大学沉淀数年3D Vison精品课件
后台回复:计算机视觉书籍,即可下载3D视觉领域经典书籍pdf
后台回复:3D视觉课程,即可学习3D视觉领域精品课程
3D视觉工坊精品课程官网:3dcver.com
1.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
2.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进
3.国内首个面向工业级实战的点云处理课程
4.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
5.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
6.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
7.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)8.从零搭建一套结构光3D重建系统[理论+源码+实践]
9.单目深度估计方法:算法梳理与代码实现10.自动驾驶中的深度学习模型部署实战11.相机模型与标定(单目+双目+鱼眼)12.重磅!四旋翼飞行器:算法与实战13.ROS2从入门到精通:理论与实战14.国内首个3D缺陷检测教程:理论、源码与实战15.基于Open3D的点云处理入门与实战教程16.透彻理解视觉ORB-SLAM3:理论基础+代码解析+算法改进重磅!粉丝学习交流群已成立
交流群主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、ORB-SLAM系列源码交流、深度估计、TOF、求职交流等方向。扫描以下二维码,添加小助理微信(dddvisiona),一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。
▲长按加微信群或投稿,微信号:dddvisiona3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、源码分享、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答等进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,6000+星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看,3天内无条件退款高质量教程资料、答疑解惑、助你高效解决问题觉得有用,麻烦给个赞和在看~
















 1657
1657

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









