






说到纯视觉的自动驾驶方案,大家第一个想到的就是Tesla吧。的确,早在2021年,Tesla就已经实现了纯视觉的BEV检测方案,而且效果非常好。

细心的同学可能发现了,这套BEV方案中将相机空间的图像转换到BEV空间的核心组件就是Transformer。
Transformer来源于自然语言处理领域,首先被应用于机器翻译。后来,大家发现它在计算机视觉领域效果也很不错,而且在各大排行榜上碾压CNN网络。
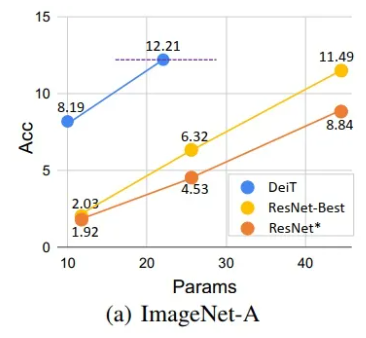
目标检测领域中,视觉Transformer不仅可以实现2D检测、3D检测,还可以实现多模态检测,BEV视角下的检测,性能也非常出色。

因此,掌握Transformer相关知识和工程基础成为了企业招聘算法工程师的一个技能要求点,也是简历上的一个很大的加分项。
然而,想要掌握基于Transformer的目标检测算法,有以下3个难点:
理解Transformer背后的理论基础,比如自注意力机制(self-attention), 位置编码(positional embedding),目标查询(object query)等等,网上的资料比较杂乱,不够系统,难以通过自学做到深入理解并融会贯通。
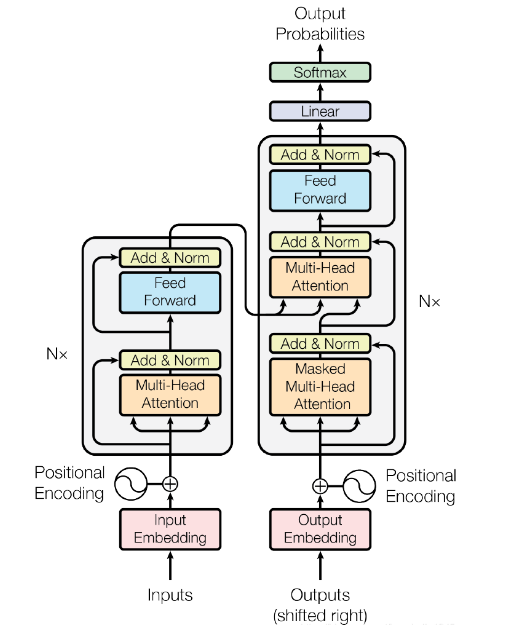
掌握基于Transformer的目标检测算法的思路和创新点,一些Transformer论文涉及的新概念比较多,话术没有那么通俗易懂,读完论文仍然不理解算法的细节部分。

Transformer代码不易看懂,因为作用机制与CNN有不少差别,所以完全理解代码并实践应用需要花费很大功夫。
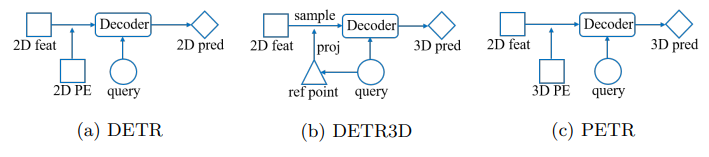
那么如何学习基于Tansformer的目标检测算法呢?
3D视觉工坊联合讲师「语嫣」,为大家精心准备了课程「目标检测中的视觉Transformer」,主要帮助各位同学解决以上这些难点。
不仅为大家详细讲解视觉Transformer的基础知识,各种经典的基于Transformer的目标检测算法,还配有代码解读和实践课程,让大家真正活学活用,理解和掌握这些知识理论。
实践部分

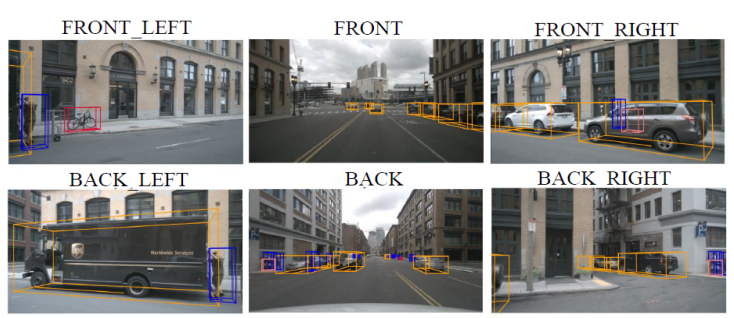










开课时间
2023年7月28日晚八点(周五),每周更新一章节。
课程答疑
本课程答疑主要在本课程对应的鹅圈子中答疑,学员学习过程中,有任何问题,可以随时在鹅圈子中提问。



















 739
739

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









