






点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:3D视觉工坊
添加小助理:dddvision,备注:方向+学校/公司+昵称,拉你入群。文末附行业细分群
扫描下方二维码,加入3D视觉知识星球,星球内凝聚了众多3D视觉实战问题,以及各个模块的学习资料:近20门视频课程(星球成员免费学习)、最新顶会论文、计算机视觉书籍、优质3D视觉算法源码等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

0.这篇文章干了啥?
这篇文章提出了一种基于视觉-语言模型的精心设计框架,通过引入窗口化自注意力机制和可学习提示,实现了在多个基准数据集上的异常检测任务。实验结果表明,该方法在图像级和像素级的异常检测任务中显著优于当前主流方法,验证了其在提高检测准确性和效率方面的有效性,并为未来进一步优化模型和扩展应用提供了重要的实证基础和研究方向。
下面一起来阅读一下这项工作~
1. 论文信息
论文题目:SOWA: Adapting Hierarchical Frozen Window Self-Attention to Visual-Language Models for Better Anomaly Detection
作者:Zongxiang Hu,Zhaosheng Zhang
论文链接:https://arxiv.org/pdf/2407.03634
2. 摘要
在工业制造中,视觉异常检测至关重要,但传统方法通常依赖于大量的正常数据集和定制模型,限制了可扩展性。近年来,大规模视觉语言模型的进展显著提升了零/少样本异常检测的能力。然而,这些方法可能未充分利用分层特征,可能会错过细微的细节。我们引入了基于CLIP模型的窗口自注意力机制,结合可学习的提示语,以在Soldier-Officer Window Self-Attention (SOWA)框架内处理多级特征。我们的方法在五个基准数据集上进行了测试,在18个指标中领先于现有的最先进技术。
3. 效果展示
Few-shot setting (K=4)的可视化结果。
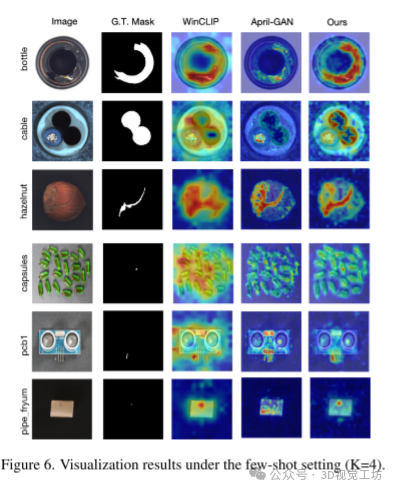 MVTec-AD数据集上的分层结果。一组图像展示了模型的实际输出,说明不同层级(H1到H4)如何处理各种特征模式。每行代表一个不同的样本,每列显示原始图像、分割蒙版、热图,以及来自H1到H4的特征输出和融合结果。
MVTec-AD数据集上的分层结果。一组图像展示了模型的实际输出,说明不同层级(H1到H4)如何处理各种特征模式。每行代表一个不同的样本,每列显示原始图像、分割蒙版、热图,以及来自H1到H4的特征输出和融合结果。

4. 主要贡献
提出了一个精心设计的框架,利用视觉语言模型的力量进行异常检测。
在多个基准数据集上进行了测试,表明与现有最先进技术相比,在异常分类和分割任务中表现出优越性。
验证了模型的工作机制,为未来研究提供了宝贵的见解。
5. 基本原理是啥?
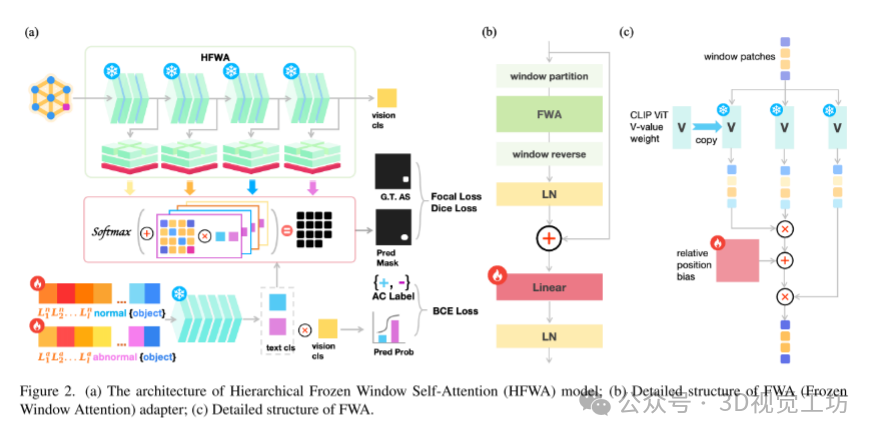
这篇文章的基本原理主要围绕着如何利用分层冻结窗口自注意力(HFWA)架构和可学习的文本提示模板来增强视觉-文本(ViT)模型在异常检测任务中的表现:
分层冻结窗口自注意力(HFWA)架构:
层次结构处理:文章引入了分层处理的概念,将图像特征分为浅层、中间层和深层。每一层都有特定的功能,比如浅层能够更好地捕捉局部特征,而深层则能整合更全局的语义信息。
冻结窗口自注意力机制:在每个ViT层之后加入了冻结窗口自注意力(FWA)适配器。这种机制通过在每个窗口内应用自注意力来增强局部特征的表达能力。自注意力能够在局部范围内捕捉到更丰富的上下文信息,有助于更准确地识别异常区域。
可学习的文本提示模板:
替代固定文本提示:传统的CLIP模型使用固定的文本提示,如“一张的照片”,这对于一般分类任务有效,但在异常检测中可能不足以捕捉异常和正常图像之间的细微差别。
引入可学习的文本提示:为了更好地适应异常检测的需求,本文引入了可学习的文本提示模板。这些模板通过对异常相关数据进行微调,能够生成更能够区分正常和异常情况的文本嵌入。例如,采用“异常这样的通用模板,而不是具体定义每种异常类型的模板,从而提高了模型对各种异常情况的适应能力和泛化能力。
结合视觉-文本信息:
特征融合:通过将ViT各层级的处理结果与文本提示的学习特征进行融合,形成最终的特征表示。这种融合不仅包括了图像本身的视觉特征,还包括了文本提示所提供的语义信息。这样的综合表示能够更好地描述图像中的正常和异常情况。
优化和评估:
损失函数设计:文章设计了结合了Focal Loss、Dice Loss和二元交叉熵损失的综合损失函数,用于优化模型的训练过程。这些损失函数能够处理类别不平衡和精确定义决策边界,提高了模型在异常检测任务中的稳健性和准确性。
评估方法:文章在多个标准数据集上进行了测试和评估,展示了该方法在异常分类和分割任务中相对于现有技术的优越性。

6. 实验结果
实验设置和数据集:
数据集选择:研究使用了五个主要的基准数据集,包括 MVTec-AD、VisA、BTAD、DAGM 和 DTDSynthetic。
数据集描述:
MVTec-AD:包含15种对象,分辨率在7002到9002像素之间,训练集仅包含正常样本,测试集包含正常和异常样本。
VisA:包含12种对象,图像大小约为1.5K × 1K像素,遵循相同的训练和测试结构。
BTAD:真实世界的工业数据集,包括2830张三种工业产品的图像,重点关注身体和表面缺陷。
DAGM:包含人工生成的图像,模拟真实世界问题,分为十个子集,每个子集包含1000张无缺陷和标记缺陷的图像。
DTD-Synthetic:包含合成的图像异常,图像大小从180 × 180到384 × 384像素不等,提供多样的纹理和方向样本。
竞争方法和基准:
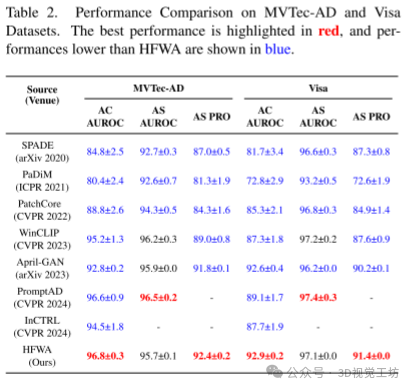
竞争模型:作者将他们的模型与WinCLIP和April-GAN进行了比较。
评估方法:作者还与多个著名的异常检测方法进行了比较,包括 SPADE、PaDiM、PatchCore、PromptAD 和 InCTRL。
评估指标:
AUROC:使用接收者操作特征曲线下面积(AUROC)作为主要的性能指标,评估异常检测的图像级和像素级任务。
AP 和 PRO:使用平均精度下面积(AP)和区域重叠(PRO)作为补充评估指标,尤其适用于精确的异常定位。
模型和训练细节:
模型结构:采用了CLIP作为主干网络,使用ViTL/14@336作为骨干,分为四个阶段(H1到H4)。
训练细节:在MVTec-AD测试数据上进行了微调,并在其他数据集上进行了评估,使用了Adam优化器、学习率为1e-3、批大小为8进行了一个epoch的训练。
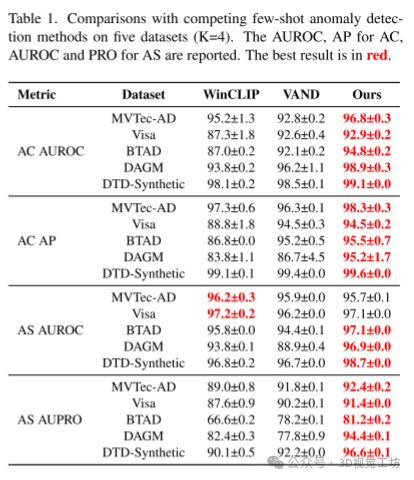
主要结果:
定量结果:在表格1中展示的结果表明,作者的方法在多个数据集和评估指标上表现出色。例如,在MVTec-AD数据集上,作者的方法在图像级别的AUROC分数达到了96.8%,比WinCLIP高出1.6个百分点,比VAND高出4.0个百分点。
像素级结果:作者的方法在像素级别的表现也显著优于竞争方法,特别是在AS PRO评估中,作者的方法在精细的异常定位上表现出了卓越的性能。
机制分析:
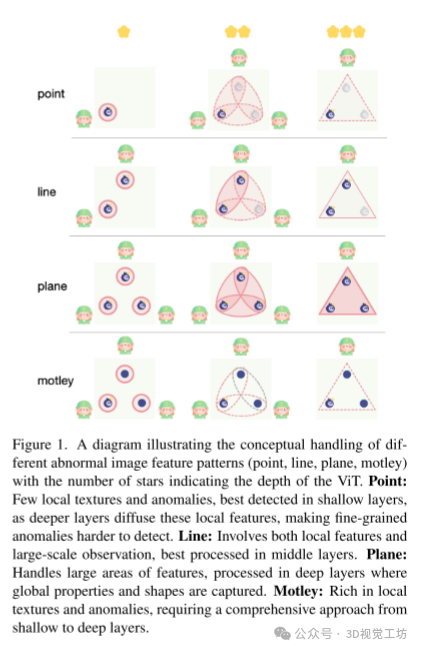
图像特征处理:通过图1和图7展示了模型在不同层次处理不同图像特征模式(点、线、平面、杂色)的能力。这些分析验证了模型在处理复杂图像场景中的有效性。
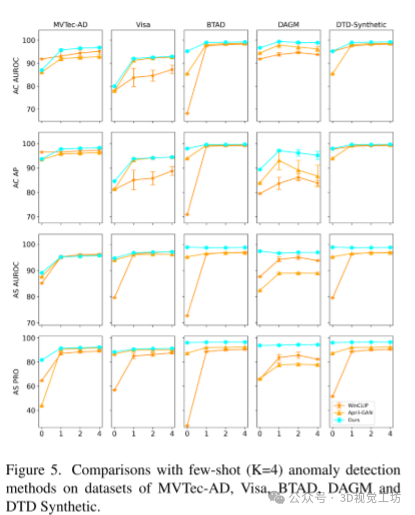
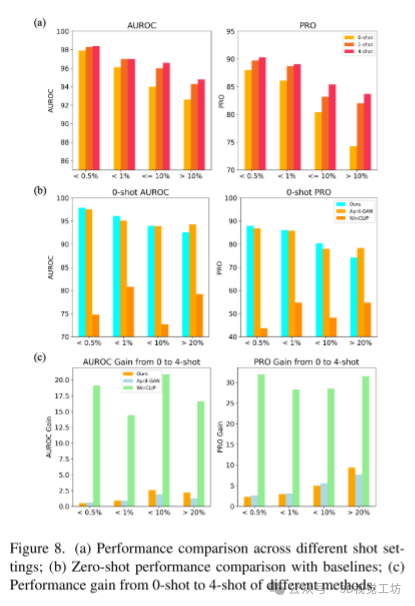
性能分析:
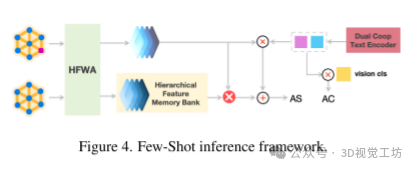
零和少样本学习:图5和图8展示了模型在零样本和少样本学习中的表现,结果表明少样本学习显著提升了模型对大型异常的检测能力。
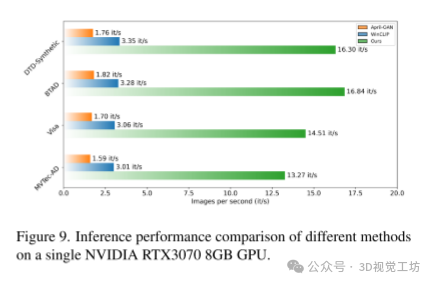
推理速度:
效率:作者的方法在推理速度方面表现出较高的效率,相比April-GAN和WinCLIP,具有更快的处理速度,这得益于窗口化自注意力机制和冻结权重的应用。
7. 总结 & 未来工作
本文提出了基于视觉-语言模型的精心设计的异常检测框架。通过引入窗口自注意机制和可学习提示,我们的方法在不同层次上自适应地聚焦于相关特征,提高了异常检测的准确性。实验表明,该方法在多个基准数据集上优于当前的最先进技术,显著改善了异常分类和分割任务。我们的研究验证了模型的有效性,并为该领域未来研究提供了宝贵的方向。
本文仅做学术分享,如有侵权,请联系删文。
3D视觉工坊交流群
目前我们已经建立了3D视觉方向多个社群,包括2D计算机视觉、大模型、工业3D视觉、SLAM、自动驾驶、三维重建、无人机等方向,细分群包括:
2D计算机视觉:图像分类/分割、目标/检测、医学影像、GAN、OCR、2D缺陷检测、遥感测绘、超分辨率、人脸检测、行为识别、模型量化剪枝、迁移学习、人体姿态估计等
大模型:NLP、CV、ASR、生成对抗大模型、强化学习大模型、对话大模型等
工业3D视觉:相机标定、立体匹配、三维点云、结构光、机械臂抓取、缺陷检测、6D位姿估计、相位偏折术、Halcon、摄影测量、阵列相机、光度立体视觉等。
SLAM:视觉SLAM、激光SLAM、语义SLAM、滤波算法、多传感器融合、多传感器标定、动态SLAM、MOT SLAM、NeRF SLAM、机器人导航等。
自动驾驶:深度估计、Transformer、毫米波|激光雷达|视觉摄像头传感器、多传感器标定、多传感器融合、自动驾驶综合群等、3D目标检测、路径规划、轨迹预测、3D点云分割、模型部署、车道线检测、Occupancy、目标跟踪等。
三维重建:3DGS、NeRF、多视图几何、OpenMVS、MVSNet、colmap、纹理贴图等
无人机:四旋翼建模、无人机飞控等
除了这些,还有求职、硬件选型、视觉产品落地、最新论文、3D视觉最新产品、3D视觉行业新闻等交流群
添加小助理: dddvision,备注:研究方向+学校/公司+昵称(如3D点云+清华+小草莓), 拉你入群。

3D视觉工坊知识星球
3D视觉从入门到精通知识星球、国内成立最早、6000+成员交流学习。包括:星球视频课程近20门(价值超6000)、项目对接、3D视觉学习路线总结、最新顶会论文&代码、3D视觉行业最新模组、3D视觉优质源码汇总、书籍推荐、编程基础&学习工具、实战项目&作业、求职招聘&面经&面试题等等。欢迎加入3D视觉从入门到精通知识星球,一起学习进步。

3DGS、NeRF、结构光、相位偏折术、机械臂抓取、点云实战、Open3D、缺陷检测、BEV感知、Occupancy、Transformer、模型部署、3D目标检测、深度估计、多传感器标定、规划与控制、无人机仿真、三维视觉C++、三维视觉python、dToF、相机标定、ROS2、机器人控制规划、LeGo-LAOM、多模态融合SLAM、LOAM-SLAM、室内室外SLAM、VINS-Fusion、ORB-SLAM3、MVSNet三维重建、colmap、线面结构光、硬件结构光扫描仪,无人机等。

3D视觉相关硬件
| 图片 | 说明 | 名称 |
|---|---|---|
 | 硬件+源码+视频教程 | 精迅V1(科研级))单目/双目3D结构光扫描仪 |
 | 硬件+源码+视频教程 | 深迅V13D线结构光三维扫描仪 |
 | 硬件+源码+视频教程 | 御风250无人机(基于PX4) |
 | 低成本+体积小 +重量轻+抗高反 | YA001高精度3D相机 |
 | 抗高反+无惧黑色+半透明 | KW-D | 高精度3D结构光 开源相机 |
 | 硬件+源码 | 工坊智能ROS小车 |
 | 配套标定源码 | 高精度标定板(玻璃or大理石) |
| 添加微信:cv3d007或者QYong2014 咨询更多 | ||
点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
3D视觉科技前沿进展日日相见 ~


















 1214
1214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









