






点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:3D视觉工坊
添加小助理:dddvision,备注:方向+学校/公司+昵称,拉你入群。文末附3D视觉行业细分群
扫描下方二维码,加入3D视觉知识星球,星球内凝聚了众多3D视觉实战问题,以及各个模块的学习资料:近20门视频课程(星球成员免费学习)、最新顶会论文、计算机视觉书籍、优质3D视觉算法源码等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!
0. 这篇文章干了啥?
高清(HD)地图被认为是确保自动驾驶车辆安全有效导航的关键因素。它们通过提供关于地图实例的详细位置和语义信息,有助于精确规划和避障。传统上,高清地图是利用基于同时定位与地图构建(SLAM)的方法离线构建的,这一过程涉及复杂的流程,需要大量劳动力和经济成本。此外,这种方法在及时响应道路变化方面存在局限性。最近的研究开始转向基于学习的在线高清地图构建,使用车载传感器,专注于生成自动驾驶车辆周围的局部地图。这种方法消除了高成本的高清地图管理,允许即时更新以反映当前道路状况,并扩展到新位置。
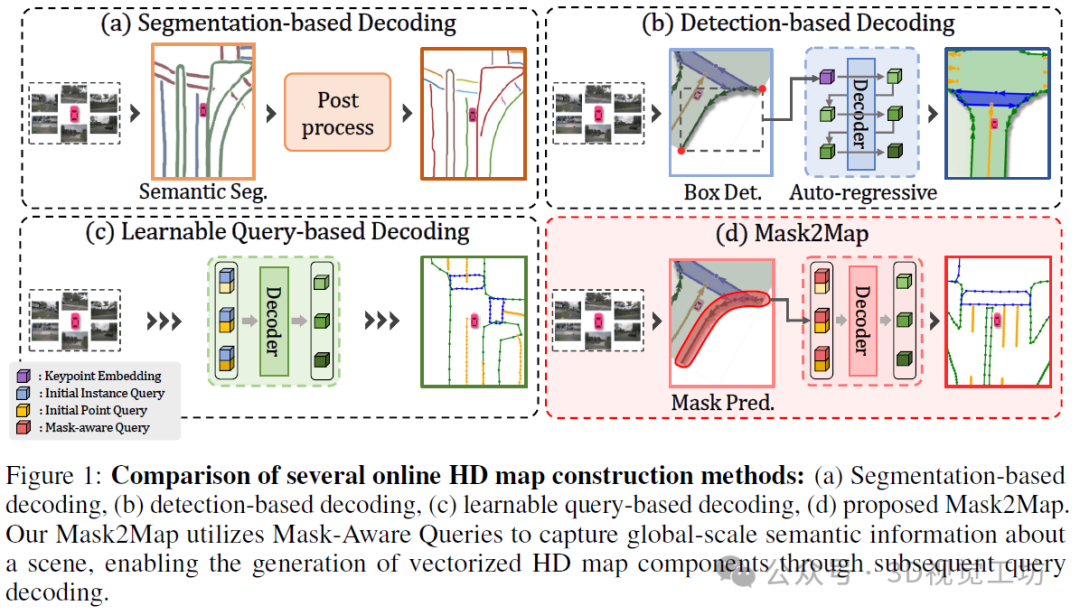
早期的研究将地图构建视为基于鸟瞰图(BEV)表示的语义分割挑战,该表示由各种传感器获得。它们预测栅格格式中每个像素的类别标签,从而避免了生成精确矢量轮廓的复杂性。虽然这种方法提供了语义地图信息,描绘了不同类别的地图组件,但在捕捉精确的关键位置及其结构关系方面存在不足。因此,其输出格式不适合直接应用于下游任务,如运动预测和规划。为了克服这一限制,人们研究了在线生成矢量化高清地图的方法。这些方法能够直接生成矢量化的地图实体,这是高清地图的一个共同特征。
迄今为止,已经提出了各种在线高清地图构建方法。最初提出了基于分割的解码方法,该方法涉及语义分割,然后使用启发式后处理算法生成矢量地图。然而,这种方法需要大量的处理时间。基于检测的解码方法识别对应于各种实例的关键点,然后顺序生成矢量地图组件。然而,仅依赖关键点可能无法充分捕捉实例的各种形状,从而阻碍了精确高清地图的生成。最近,提出了各种可学习的基于查询的解码方法,这些方法通过从鸟瞰图(BEV)特征中并行解码可学习的查询来直接预测矢量地图组件。由于初始可学习查询与给定场景无关,它们限制了同时在复杂场景中捕捉地图实例的语义和几何信息的能力。
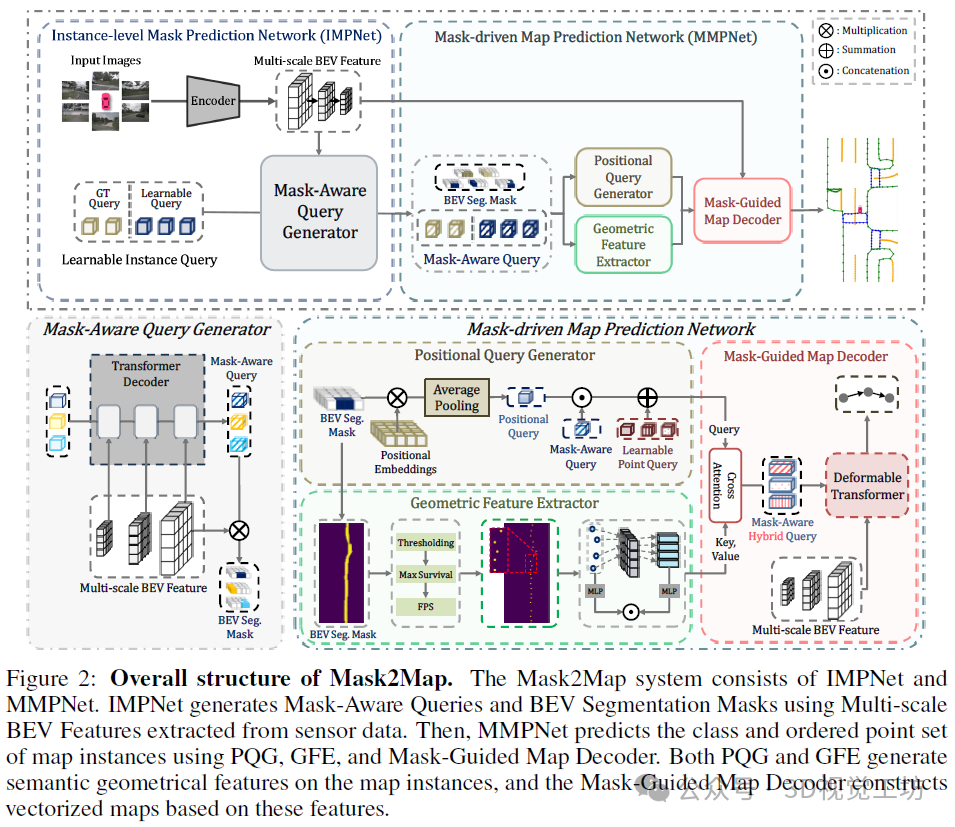
本研究介绍了一种新颖的端到端高清地图构建框架,称为Mask2Map。Mask2Map通过利用旨在区分BEV域中不同类别实例的分割掩码,与现有方法区分开来。所提出的Mask2Map架构包括两个网络:实例级掩码预测网络(IMPNet)和掩码驱动地图预测网络(MMPNet)。首先,IMPNet从传感器数据构建多尺度BEV特征,并生成掩码感知查询,以从全局视角捕捉实例的语义特征。遵循实例分割模型Mask2Former的框架,我们设计了掩码感知查询,能够生成与BEV域中不同类别实例相关联的BEV分割掩码。随后,基于IMPNet提供的掩码感知查询,MMPNet从BEV域的局部视角动态预测地图实例的有序点集。简而言之,MMPNet利用从IMPNet获得的全面语义场景信息,专注于生成连贯且精细的地图组件。
我们提出了几种创新方法来提高高清地图预测的准确性。首先,我们设计了位置查询生成器(PQG),它生成实例级位置查询,捕获全面的位置信息,以增强掩码感知查询。其次,虽然大多数现有方法在构建高清地图时没有考虑每个地图实例的点级信息,但我们引入了几何特征提取器(GFE)来捕获每个实例的几何结构。GFE处理鸟瞰图(BEV)分割掩码,从BEV特征中提取地图实例的点级几何特征。第三,我们观察到,由于IMPNet和MMPNet的查询与不同实例的真实值(GT)关联时存在网络间不一致性,Mask2Map的性能有限。为了解决这个问题,我们提出了一种网络间去噪训练策略。该方法利用噪声GT查询和扰动GT分割掩码作为IMPNet的输入,并指导模型抵消噪声,从而确保网络间的一致性,并提高高清地图构建的性能。
我们在多个具有挑战性的基准数据集上评估了所提出的Mask2Map,包括nuScenes和Argoverse2。我们的Mask2Map在这两个基准数据集上都取得了显著的性能提升,超过了之前的最先进(SOTA)方法。特别是,在nuScenes基准数据集上,Mask2Map实现了71.6%的平均精度(mAP),比之前的最佳基于相机的方法MapTRv2高出10.1% mAP。在基于栅格化的评估指标中,Mask2Map实现了54.7% mAP的SOTA性能,比MapTRv2高出18.0% mAP以上。在Argoverse2基准数据集上,使用相同的骨干网络ResNet50,Mask2Map比MapTRv2高出4.1% mAP。
下面一起来阅读一下这项工作~
1. 论文信息
标题:Mask2Map: Vectorized HD Map Construction Using Bird's Eye View Segmentation Masks
作者:Sehwan Choi, Jungho Kim, Hongjae Shin, Jun Won Choi
机构:Hanyang University、Seoul National University
原文链接:https://arxiv.org/abs/2407.13517
代码链接:https://github.com/SehwanChoi0307/Mask2Map
2. 摘要
在本文中,我们介绍了Mask2Map,这是一种专为自动驾驶应用设计的新型端到端高清地图构建方法。我们的方法侧重于预测场景中地图实例的类别和有序点集,这些实例以鸟瞰图(BEV)的形式表示。Mask2Map由两个主要组件组成:实例级掩码预测网络(IMPNet)和掩码驱动地图预测网络(MMPNet)。IMPNet生成掩码感知查询和BEV分割掩码,以全局捕获全面的语义信息。随后,MMPNet通过两个子模块:位置查询生成器(PQG)和几何特征提取器(GFE),利用局部上下文信息增强这些查询特征。PQG通过将BEV位置信息嵌入掩码感知查询中来提取实例级位置查询,而GFE利用BEV分割掩码生成点级几何特征。然而,我们观察到Mask2Map的性能有限,这是由于IMPNet和MMPNet之间对真实值(GT)匹配的不同预测导致的网络间不一致性。为了应对这一挑战,我们提出了网络间去噪训练方法,该方法指导模型对受噪声GT查询和扰动GT分割掩码影响的输出进行去噪。我们在nuScenes和Argoverse2基准数据集上进行的评估表明,与先前最先进的方法相比,Mask2Map实现了显著的性能提升,分别提高了10.1%和4.1%的mAP。我们的代码可在https://github.com/SehwanChoi0307/Mask2Map上找到。
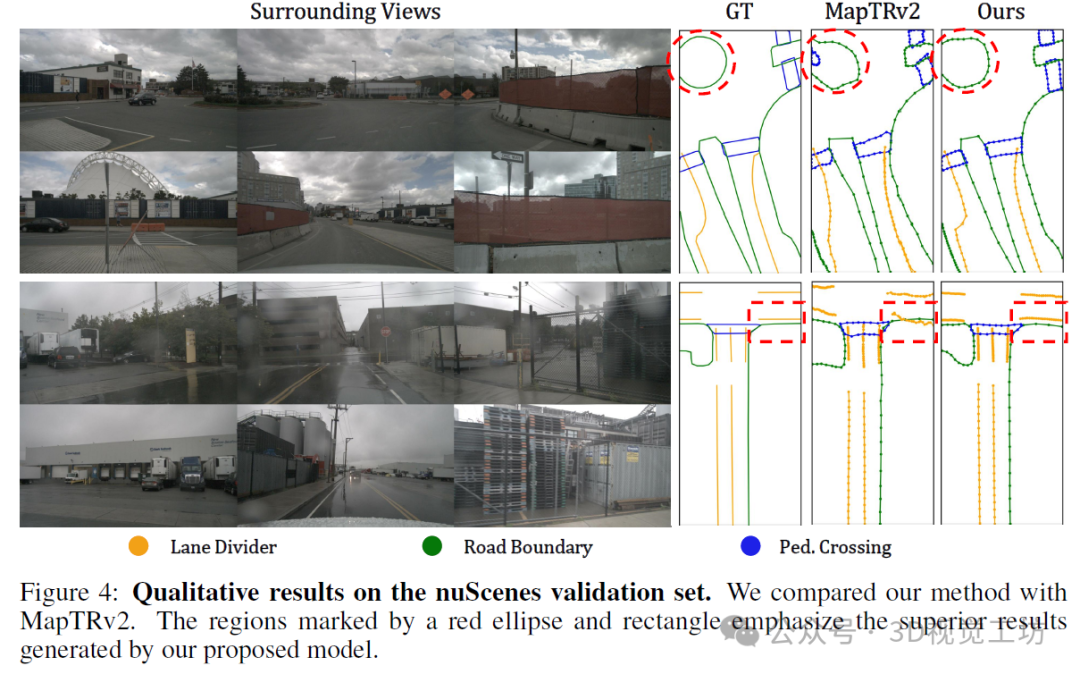
3. 效果展示
4. 主要贡献
本研究的主要贡献总结如下:
• 我们提出了Mask2Map,这是一种用于在线高清地图构建的新框架。我们的模型从场景中捕获实例级别的语义信息,并使用这些信息随后生成细粒度的地图组件。我们融合了Mask2Former中的一个关键元素:掩码感知查询,它被重新设计用于提取鸟瞰图(BEV)域中的语义掩码。
• 我们设计了一种掩码引导的分层特征提取架构,以有效地编码地图实例的实例级位置信息和点级几何信息。
• 我们提出了一种网络间去噪训练策略,该策略使用噪声真实值(GT)查询和扰动的GT分割掩码,以确保网络间的一致性并提升高清地图构建的性能。
5. 基本原理是啥?
Mask2Map的总体架构如图2所示。Mask2Map架构包含两个网络:IMPNet和MMPNet。首先,IMPNet生成掩码感知查询,从全局视角捕获整体语义信息。随后,MMPNet利用通过位置查询生成器(PQG)和几何特征提取器(GFE)获取的几何信息,从局部视角构建更详细的矢量地图。
6. 实验结果
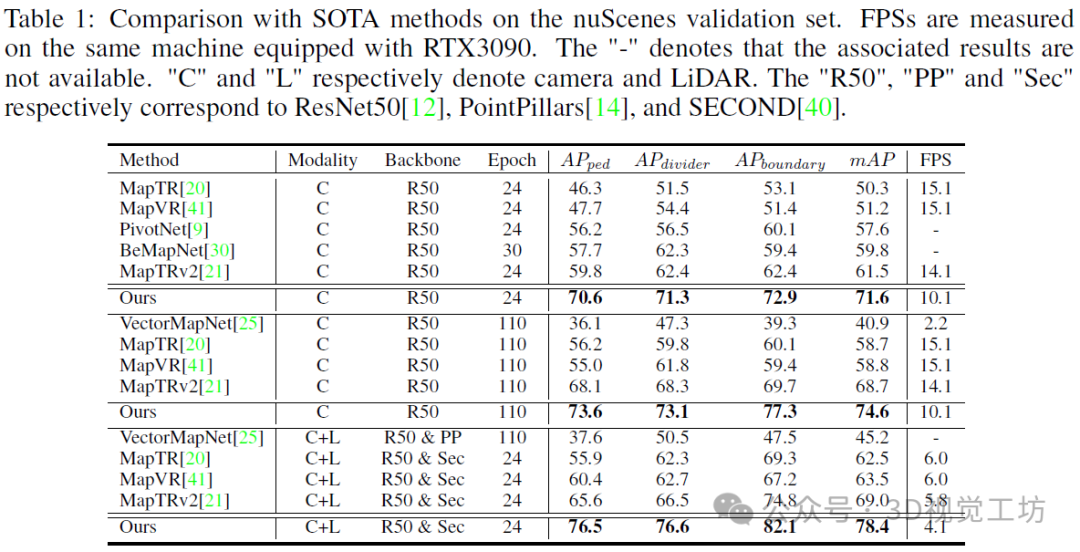
nuScenes上的结果。表1展示了Mask2Map在nuScenes验证集上的综合性能分析,采用了Chamfer距离指标。Mask2Map树立了新的最先进的性能水平,相较于现有方法表现出显著提升。仅使用相机输入时,Mask2Map在24个周期时取得了71.6%的mAP,在110个周期时取得了74.6%的mAP,分别优于先前的最先进模型MapTRv2 10.1%的mAP和5.9%的mAP。在使用相机-激光雷达融合时,Mask2Map相较于MapTRv2实现了9.4%的mAP性能提升。表2基于栅格化指标评估了Mask2Map的性能。值得注意的是,我们的Mask2Map方法相较于MapTRv2实现了18.0 mAP的显著性能提升。
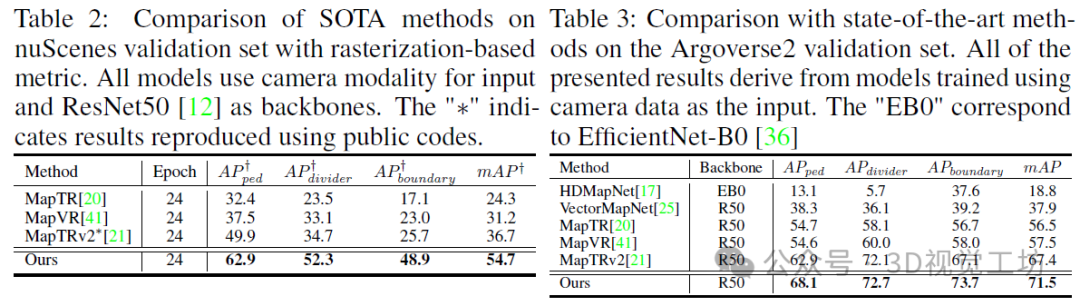
Argoverse2上的结果。表3展示了若干高清地图构建方法在Argoverse2验证集上的性能评估。所提出的Mask2Map相较于现有模型表现出显著的性能提升。Mask2Map超越了当前领先的方法MapTRv2,实现了4.1%的mAP提升,这表明我们的模型在不同场景下均能实现一致的性能。
7. 局限性 & 总结 & 未来工作
局限性和未来工作。关于未来的工作,我们考虑从两个方面改进Mask2Map。(i)众所周知,时序信息可以提高自动驾驶感知任务的可靠性。然而,我们的模型目前仅依赖于当前帧的输入,这可能导致在物体遮挡的场景中性能下降。通过查询或前一帧的鸟瞰图(BEV)特征进行时序融合的方法,可能是解决这一局限性的有效途径。(ii)我们的实验表明,与当前的最优方法MapTRv2相比,Mask2Map的帧率(FPS)有所下降,但性能提升显著。为了满足实时性要求,我们考虑采用模型压缩和优化方法。这些技术将是在不牺牲性能的情况下提高FPS的有前途的途径。
结论。在本文中,我们介绍了一种名为Mask2Map的端到端在线高清地图构建方法。Mask2Map利用实例级掩码预测网络(IMPNet)生成掩码感知查询和BEV分割掩码,从全局视角捕获语义场景上下文。随后,掩码驱动地图预测网络(MMPNet)通过位置查询生成器(PQG)和几何特征提取器(GFE)融入语义和几何信息,增强掩码感知查询。最后,掩码引导地图解码器预测地图实例的类别和有序点集。此外,我们提出了网络间去噪训练方法,以缓解IMPNet和MMPNet之间因二分匹配结果不同而产生的网络间不一致性。我们在nuScenes和Argoverse2基准数据集上的评估表明,所提出的方法相较于基线方法实现了显著的性能提升,大幅超越了现有的高清地图构建方法。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
本文仅做学术分享,如有侵权,请联系删文。
3D视觉工坊交流群
目前我们已经建立了3D视觉方向多个社群,包括2D计算机视觉、大模型、工业3D视觉、SLAM、自动驾驶、三维重建、无人机等方向,细分群包括:
2D计算机视觉:图像分类/分割、目标/检测、医学影像、GAN、OCR、2D缺陷检测、遥感测绘、超分辨率、人脸检测、行为识别、模型量化剪枝、迁移学习、人体姿态估计等
大模型:NLP、CV、ASR、生成对抗大模型、强化学习大模型、对话大模型等
工业3D视觉:相机标定、立体匹配、三维点云、结构光、机械臂抓取、缺陷检测、6D位姿估计、相位偏折术、Halcon、摄影测量、阵列相机、光度立体视觉等。
SLAM:视觉SLAM、激光SLAM、语义SLAM、滤波算法、多传感器融合、多传感器标定、动态SLAM、MOT SLAM、NeRF SLAM、机器人导航等。
自动驾驶:深度估计、Transformer、毫米波|激光雷达|视觉摄像头传感器、多传感器标定、多传感器融合、自动驾驶综合群等、3D目标检测、路径规划、轨迹预测、3D点云分割、模型部署、车道线检测、Occupancy、目标跟踪等。
三维重建:3DGS、NeRF、多视图几何、OpenMVS、MVSNet、colmap、纹理贴图等
无人机:四旋翼建模、无人机飞控等
除了这些,还有求职、硬件选型、视觉产品落地、最新论文、3D视觉最新产品、3D视觉行业新闻等交流群
添加小助理: dddvision,备注:研究方向+学校/公司+昵称(如3D点云+清华+小草莓), 拉你入群。

3D视觉工坊知识星球
3D视觉从入门到精通知识星球、国内成立最早、6000+成员交流学习。包括:星球视频课程近20门(价值超6000)、项目对接、3D视觉学习路线总结、最新顶会论文&代码、3D视觉行业最新模组、3D视觉优质源码汇总、书籍推荐、编程基础&学习工具、实战项目&作业、求职招聘&面经&面试题等等。欢迎加入3D视觉从入门到精通知识星球,一起学习进步。

具身智能、3DGS、NeRF、结构光、相位偏折术、机械臂抓取、点云实战、Open3D、缺陷检测、BEV感知、Occupancy、Transformer、模型部署、3D目标检测、深度估计、多传感器标定、规划与控制、无人机仿真、三维视觉C++、三维视觉python、dToF、相机标定、ROS2、机器人控制规划、LeGo-LAOM、多模态融合SLAM、LOAM-SLAM、室内室外SLAM、VINS-Fusion、ORB-SLAM3、MVSNet三维重建、colmap、线面结构光、硬件结构光扫描仪,无人机等。

3D视觉模组选型:www.3dcver.com

— 完 —
点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
3D视觉科技前沿进展日日相见 ~


















 6701
6701

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









