






点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:3D视觉工坊
添加小助理:cv3d001,备注:方向+学校/公司+昵称,拉你入群。文末附3D视觉行业细分群。
扫描下方二维码,加入「3D视觉从入门到精通」知识星球,星球内凝聚了众多3D视觉实战问题,以及各个模块的学习资料:近20门秘制视频课程、最新顶会论文、计算机视觉书籍、优质3D视觉算法源码等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

0.这篇文章干了啥?
这篇文章介绍了一种新方法FADE,用于零样本和少样本异常检测,结合了语言和视觉引导,改进了CLIP模型。FADE通过使用多尺度GEM(Global Embedding Model)嵌入,增强了与语言的对齐,并利用大型语言模型生成的新的提示集合,提升了异常检测的准确性。在零样本异常检测中,FADE通过查询图像进行视觉引导,而在少样本设置中,则通过参考图像进行引导。实验结果表明,FADE在标准数据集MVTec-AD和VisA上表现优异,特别是在零样本异常分割上有显著改进,并在少样本设置中优于其他现有方法。此外,消融实验揭示了GEM和CLIP嵌入的不同适用场景以及文本提示的有效性,未来的工作可以进一步探索LLM生成的提示对性能的影响,并优化视觉引导方法,以适应不同的检测场景。
下面一起来阅读一下这项工作~
1. 论文信息
论文题目:FADE: Few-shot/zero-shot Anomaly Detection Engine using Large Vision-Language Model
作者:Yuanwei Li, Elizaveta Ivanova等
作者机构:Onfido London, UK
论文链接:https://arxiv.org/pdf/2409.00556
2. 摘要
自动图像异常检测在制造业的质量检验中至关重要。通常的无监督异常检测方法是使用正常样本的数据集为每个物体类别训练一个模型。然而,更现实的问题是零样本/少样本异常检测,其中可用的正常样本为零或仅有少量样本。这使得物体特定模型的训练变得具有挑战性。近年来,大型基础视觉-语言模型在各种下游任务中表现出强大的零样本性能。尽管这些模型已经学习了视觉和语言之间的复杂关系,但它们并不是专门为异常检测任务设计的。在本文中,我们提出了少样本/零样本异常检测引擎(FADE),它利用视觉-语言CLIP模型并将其调整用于工业异常检测。具体而言,我们通过以下方式改进语言引导的异常分割:1) 通过调整CLIP以提取与语言更好对齐的多尺度图像补丁嵌入,2) 自动生成与工业异常检测相关的文本提示集,3) 使用来自查询图像和参考图像的额外视觉引导,进一步改进零样本和少样本异常检测。在MVTec-AD(以及VisA)数据集上,FADE在异常分割方面优于其他最新方法,零样本下的像素AUROC达到89.6%(91.5%),1正常样本下达到95.4%(97.5%)。代码可在 https://github.com/BMVC-FADE/BMVC-FADE 获取。
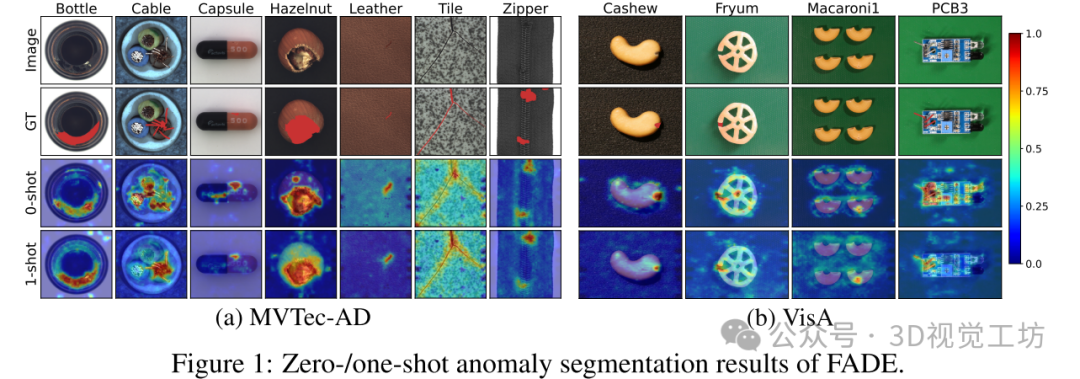
3. 效果展示
Zero-/one-shot异常分割结果。
4. 主要贡献
我们利用GEM补丁嵌入,它与语言对齐更好,从而提高了零样本语言引导的AS。此外,我们采用多尺度方法,使该方法在检测不同大小的异常时更具鲁棒性。
我们进一步通过使用LLM自动生成与正常性和异常概念相关的提示集来改进语言引导的异常检测,这些提示集包括与工业异常检测相关的多样化文本提示。
我们通过采用视觉引导的方法来增强异常检测性能,该方法适用于零样本和少样本设置。
FADE在MVTec-AD和VisA基准上展示了在AC和AS方面的竞争力,无论是在零样本还是少正常样本的情况下。
5. 基本原理是啥?
CLIP模型的利用与调整:
CLIP模型:CLIP(Contrastive Language-Image Pretraining)模型是一种通过对比学习将视觉信息和语言信息进行对齐的模型。FADE利用CLIP模型的视觉和语言表示来实现异常检测。
调整:FADE对CLIP模型进行调整,以更好地适应零样本和少样本异常检测的需求。具体来说,通过结合语言引导和视觉引导来提高检测性能。
多尺度GEM嵌入:
GEM嵌入:FADE引入了多尺度GEM(Global Embedding Matching)嵌入,以提高异常分割的准确性。这些嵌入在多个尺度下捕捉图像的特征,能够更好地与语言描述对齐。
多尺度处理:通过处理不同尺度的图像特征,FADE可以更准确地检测不同大小的异常。
语言引导:
LLM生成提示:使用大语言模型(LLM)生成的文本提示来帮助理解异常和正常的概念。这些提示集合能够捕捉更丰富的异常描述,从而提高异常检测的效果。
提示集合:通过生成新的提示集合来改进异常分割性能。
视觉引导:
查询图像的视觉引导:在零样本设置下,FADE利用查询图像来提供视觉引导,从而提升异常检测的性能。
参考图像的视觉引导:在少样本设置下,FADE利用参考图像提供的视觉信息来扩展方法,使其能够处理少样本的情况。
实验结果:
FADE在标准基准数据集上的性能与现有最先进的方法相当,在零样本异常分割方面表现出显著的改进。
通过多尺度GEM嵌入和改进的提示集合,FADE能够更好地检测异常,并且在不同设置下表现稳定。

6. 实验结果
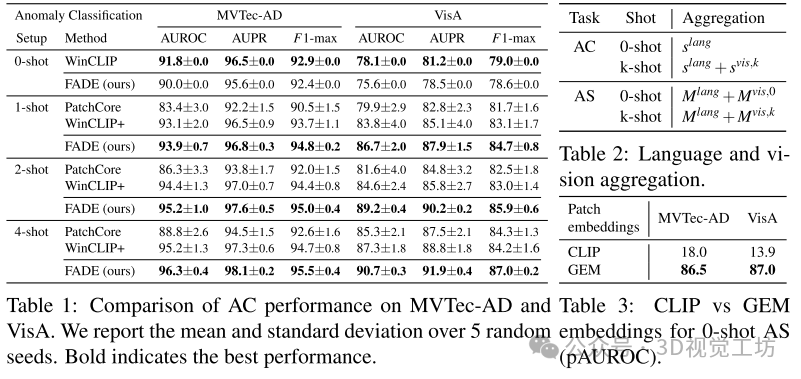
零样本异常分类(AC)和异常分割(AS):
AC性能:FADE在零样本设置下的异常分类性能与以往的最先进方法如PatchCore(无监督异常检测方法)和WinCLIP(零样本/少样本异常检测方法)相比。FADE在零样本设置下是WinCLIP的复现,没有任何新增加的部分。在少样本设置下,FADE在所有指标上均优于其他方法,特别是在VisA数据集上表现出更大的改进。这表明FADE的视觉引导AS组件对AC也有益处。
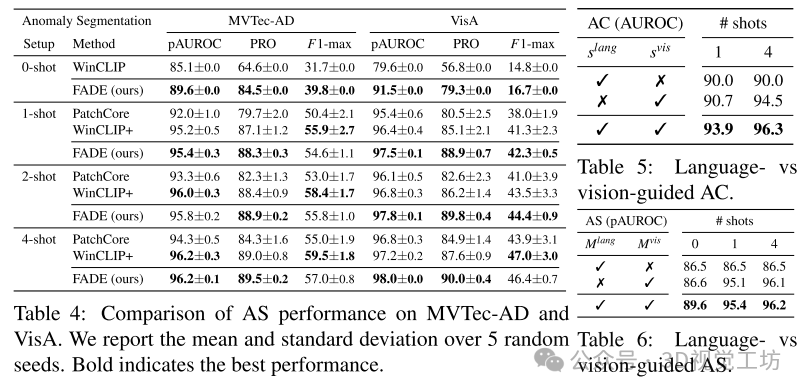
AS性能:FADE在零样本设置下显著优于PatchCore和WinCLIP,特别是在MVTec-AD和VisA数据集上。FADE通过多尺度GEM嵌入、改进的ChatGPT提示集合以及基于查询图像的零样本视觉引导,提升了异常分割的效果。在少样本设置下,FADE在MVTec-AD上表现类似于WinCLIP,而在更具挑战性的VisA数据集上仍然优于WinCLIP,显示出FADE在处理困难图像上的优势。FADE的性能在不同随机运行中的标准差较低,表明其对参考图像选择的鲁棒性更强。
定性结果:
FADE的定性结果展示了对一些对象的异常分割效果。附加的定量结果比较了FADE与其他最先进方法(如AnomalyCLIP、AnomalyGPT和APRIL-GAN)的性能。尽管这些方法需要额外的异常检测数据集进行训练,而FADE则不需要额外训练,但FADE在性能上仍然具有竞争力。
消融实验:
GEM与CLIP嵌入:使用CLIP嵌入时,像素级AUROC(pAUROC)低于50.0,这主要由于正常和异常区域的视觉表示相反。GEM嵌入修正了这一问题,结果显示GEM嵌入在零样本异常分割中优于CLIP嵌入。
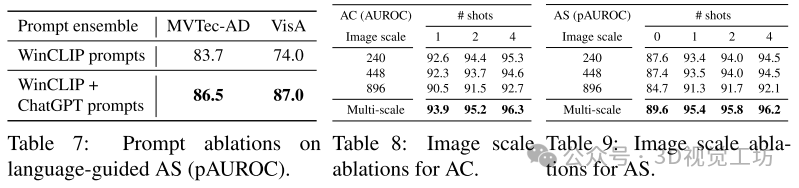
提示集合:使用ChatGPT生成的附加文本提示改进了零样本语言引导的异常分割,这些提示能够更全面地描述异常和正常概念。然而,这些提示对零样本图像级异常分类性能没有显著提升。
多尺度聚合:不同输入图像尺度/大小对AC和AS性能的影响表明,使用多尺度聚合可以更好地检测不同大小的异常。在所有k-shot设置中,多尺度方法表现最佳。
语言与视觉引导:语言引导依赖于文本提示,而视觉引导依赖于查询图像(零样本)或参考图像(少样本)。两种引导方式是互补的,能够提升整体性能。
7. 总结 & 未来工作
我们提出了一种新方法 FADE,利用并调整 CLIP 模型以实现语言和视觉引导的零样本/少样本异常检测。首先,我们通过使用多尺度 GEM 嵌入来改进语言引导的异常分割,这些嵌入与 CLIP 嵌入相比,更好地与语言对齐。通过使用大语言模型(LLM)生成新的提示集合进一步改进了这一点,这些提示更好地捕捉了异常和正常的概念。最后,来自查询图像的视觉引导进一步提升了零样本异常检测的性能,而来自参考图像的视觉引导则将该方法扩展到少样本设置。在标准基准上,FADE 相较于其他最先进的方法表现出色,尤其在零样本异常分割方面改进幅度最大。
对于 FADE,有几个值得作为未来工作进行研究的方面。首先,ChatGPT 生成的文本提示不可重复。虽然可以使用其他开源的 LLM 来设置种子以确保可重复性,但还值得研究异常检测性能对由相同 LLM 生成的不同提示或不同 LLM 生成的提示的敏感性。我们的实验结果显示,对于语言引导的异常检测,GEM 嵌入在零样本 AS 中表现更好,而 CLIP 嵌入更适合零样本 AC。另一方面,对于视觉引导的异常检测,GEM 嵌入在零样本 AS 中表现更好,而 CLIP 嵌入则更适合少样本 AS。需要进行更全面的研究,以更好地理解在不同检测管道和场景下何时使用 GEM 和 CLIP 嵌入。
视觉引导的零样本 AS 是通过自身的查询图像补丁构建内存库的。这在检测纹理图像(例如皮革)中的异常时效果良好,因为这些图像通常包含视觉上相似的补丁。然而,对于对象图像(例如晶体管)中差异较大的补丁,这种方法的效果较差,并可能产生误报。未来的工作需要探索其他视觉引导的零样本方法,以解决这一问题。
本文仅做学术分享,如有侵权,请联系删文。

3D视觉交流群,成立啦!
目前我们已经建立了3D视觉方向多个社群,包括2D计算机视觉、最前沿、工业3D视觉、SLAM、自动驾驶、三维重建、无人机等方向,细分群包括:
工业3D视觉:相机标定、立体匹配、三维点云、结构光、机械臂抓取、缺陷检测、6D位姿估计、相位偏折术、Halcon、摄影测量、阵列相机、光度立体视觉等。
SLAM:视觉SLAM、激光SLAM、语义SLAM、滤波算法、多传感器融合、多传感器标定、动态SLAM、MOT SLAM、NeRF SLAM、机器人导航等。
自动驾驶:深度估计、Transformer、毫米波|激光雷达|视觉摄像头传感器、多传感器标定、多传感器融合、自动驾驶综合群等、3D目标检测、路径规划、轨迹预测、3D点云分割、模型部署、车道线检测、Occupancy、目标跟踪等。
三维重建:3DGS、NeRF、多视图几何、OpenMVS、MVSNet、colmap、纹理贴图等
无人机:四旋翼建模、无人机飞控等
2D计算机视觉:图像分类/分割、目标/检测、医学影像、GAN、OCR、2D缺陷检测、遥感测绘、超分辨率、人脸检测、行为识别、模型量化剪枝、迁移学习、人体姿态估计等
最前沿:具身智能、大模型、Mamba、扩散模型等
除了这些,还有求职、硬件选型、视觉产品落地、产品、行业新闻等交流群
添加小助理: cv3d001,备注:研究方向+学校/公司+昵称(如3D点云+清华+小草莓), 拉你入群。

3D视觉工坊知识星球
「3D视觉从入门到精通」知识星球,已沉淀6年,星球内资料包括:秘制视频课程近20门(包括结构光三维重建、相机标定、SLAM、深度估计、3D目标检测、3DGS顶会带读课程、三维点云等)、项目对接、3D视觉学习路线总结、最新顶会论文&代码、3D视觉行业最新模组、3D视觉优质源码汇总、书籍推荐、编程基础&学习工具、实战项目&作业、求职招聘&面经&面试题等等。欢迎加入3D视觉从入门到精通知识星球,一起学习进步。
具身智能、3DGS、NeRF、结构光、相位偏折术、机械臂抓取、点云实战、Open3D、缺陷检测、BEV感知、Occupancy、Transformer、模型部署、3D目标检测、深度估计、多传感器标定、规划与控制、无人机仿真、C++、三维视觉python、dToF、相机标定、ROS2、机器人控制规划、LeGo-LAOM、多模态融合SLAM、LOAM-SLAM、室内室外SLAM、VINS-Fusion、ORB-SLAM3、MVSNet三维重建、colmap、线面结构光、硬件结构光扫描仪等。

3D视觉模组选型:www.3dcver.com

— 完 —
点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
3D视觉科技前沿进展日日相见 ~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









