






点击上方“3D视觉工坊”,选择“星标”
干货第一时间送达

内容来自知乎,「3D视觉工坊」整理,如有侵权请联系删除 https://www.zhihu.com/question/373809553
三维重建的具体步骤有哪些?,每一步分别是为了获得什么信息?
作者 shangzhao
个人的研究发方向是基于RGBD 的三维重建。常规的步骤是相机校准, 数据获取, 数据预处理, 数据融合和配准, 数据导出。
其中,相机校准是为了获取基于相机模型或者是双目模型的二维到三维映射的参数。
数据获取是通过驱动获取相机数据流进行压缩,存储,通讯。
数据预处理主要包括了 图像的降噪(特别是深度图), 图像的分割(区分出前景或者关注区域),图像的约束预处理(比如edge map,normal map等等)
数据配准和融合是三维重建的核心部分,主要是通过配准来把所有获取的数据变换到一个共同的全局空间,空间的表现形式可以是多样的。可以是一个三维网格,来更新每个网格顶点的坐标和法向量,类似laplacian smooth之类的感觉;也可以是一个三维标量体,比如目前在RGBD领域最常用的Signed Distance Field (SDF)或 Truncated Signed Distance Field (TSDF);也可以直接在点云下配准,相当于找到一个最好的对应匹配关系使得所有的数据的error metric或者distance metric达到一个全局最优,常用的一个描述metric就是Hausdorff distance。当数据在一个空间内后,可以通过最近点搜索,或者投影最近点(projective depth association)来计算出对应关系后对数据的存储进行更新。最具代表性的是TSDF fusion。
最后是数据的导出,一般通过marching cube方法来提取等值面获得三维网格。其中,点云方式需要先变换成体素表示后再进行导出。
深度学习已经关注了重建领域,主要关注的是形状补全和重建。其中个人认为比较有代表性的是来自于Facebook Research 的DeepSDF。但是大多数的数据驱动方法都是通过形成对训练数据的隐式空间来进行重建,所以重建相当于从已知的训练知识中通过隐空间插值的方法来获得重建数据。虽然可以通过神经网络获得有代表性的特征表示,但是这类方法的鲁棒性和实际可用性相对来说会比较局限。但这也是它研究价值的体现。
作者 芭芭拉冲鸭
图像在呈现的时候可以以我们肉眼看到的图像,也可以以点云形式。在研究图像处理时,大多针对的是点云图像。目前基于图像序列的三维重建的三维重建主要有两种策略:一是顺序方法,是指从两幅图像的匹配和重建开始逐渐增加新的图像直至重建整个序列。由于这种方法无法同时利用所有的图像信息,累积误差就不可避免。二是测量矩阵分解方法,首先根据所有图像间的匹配关系获得一个测量矩阵,对测量矩阵进行分解就可一次性解出所有的场景结构以及摄像机的运动参数。由于这种策略是将所有图像平等对待,因而能够保证误差的均匀分布。不足之处是这种方法要求被重建点在所有的图像中均保持可见,这一条件在许多情况下不易满足,这也限制了它的应用。
三维重建的入门需要和具体的数据结合在一起才能实践,需要一定的线性代数和最优化等数学基础。深蓝学院基于图像的三维重建课程从稠密点云重建、表面重建和3D模型可视化几个方面进行探索,有效解决了在三维重建中可能遇到的问题。
作者 VR全景阿初
空间三维重建中,有一个很重要的信息就是深度信息,那么获取深度信息的方式有哪些呢?简单来说,主要有以下几种:双目视觉法双目视觉是利用视差原理的一种视觉方法,就和人的两个眼睛一样,使用相对位置固定的两个摄像头同时拍摄一个物体,通过物体在两个摄像头上成像的像素差,根据三角测量法计算获得物体距离摄像头的深度信息。
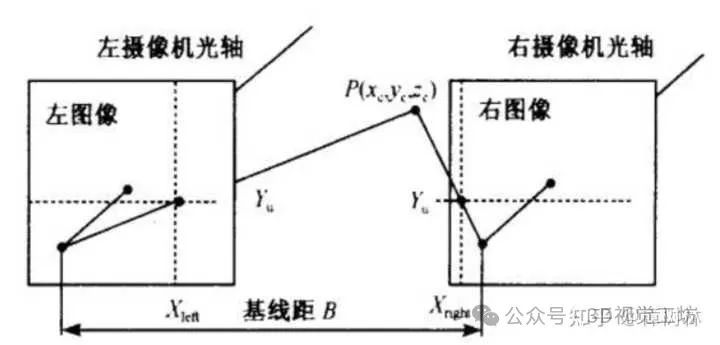
图片来源于网络,侵歉删结构光法结构光法成像原理是可控光源向被测物体投射明显的特征信息,使得一些光滑的、缺乏纹理特征、无明显灰度和形状变化的表面有了可区分的纹理特征,那么就在相机、结构光源和每一个被测物点之间可构成的唯一的三角形,用的也是三角测量法。

图片来源于网络,侵歉删
飞行时间法(TOF)TOF是Time of flight的简写,直译为飞行时间的意思。飞行时间法(TOF),简单来说,是通过连续发射光脉冲(一般为不可见光)到被测物体上,然后接收从物体反射回去的光脉冲通过探测光脉冲的飞行往返)时间来计算被测物体离相机的距离。根据已产生深度信息,再结合传统相机获取物体表面的轮廓。
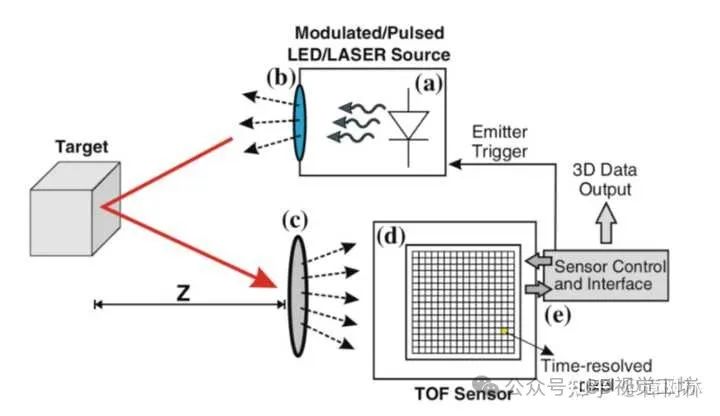
图片来源于网络,侵歉删



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









