






兄弟们,先问个扎心的问题:
每天在集群节点间疯狂敲jps查服务?改个配置文件要手动scp到 10 台机器?装个软件得逐台输命令?
作为在 Hadoop 坑摸爬滚打 8 年的老鸟,我当年咬牙写了 3 个脚本,直接把重复劳动效率拉满!今天就把压箱底的「偷懒神器」分享出来,学会后能把运维时间压缩到原来的 1/10~
一、「一键透视」集群服务:jps-cluster.sh
痛点暴击:想查 bigdata02 和 bigdata03 的服务?得先ssh过去再敲jps,一套操作下来 5 分钟没了!
飞哥神操作:写个脚本让主节点一键「远程查房」,喝口水的功夫看全集群状态!
🚀 脚本亮点
- 懒人福音:在 node01 敲
jps-cluster.sh,直接输出 3 台节点的进程列表 - 路径自由:脚本丢到
/usr/local/bin,全局任意目录调用 - 权限到位:
chmod +x jps-cluster.sh赋权,永久有效
📝 核心代码
#!/bin/bash
USAGE="使用方法:sh jps-cluster.sh"
NODES=("bigdata01" "bigdata02" "bigdata03")
for NODE in ${NODES[*]};do
echo "--------$NODE--------"
ssh $NODE "/opt/installs/jdk/bin/jps"
done
echo "------------------------------------------"
echo "--------jps-cluster.sh脚本执行完成!--------"记得赋权限
chmod u+x jps-cluster.sh不管在哪个地方都可以执行该命令 jps-cluster.sh
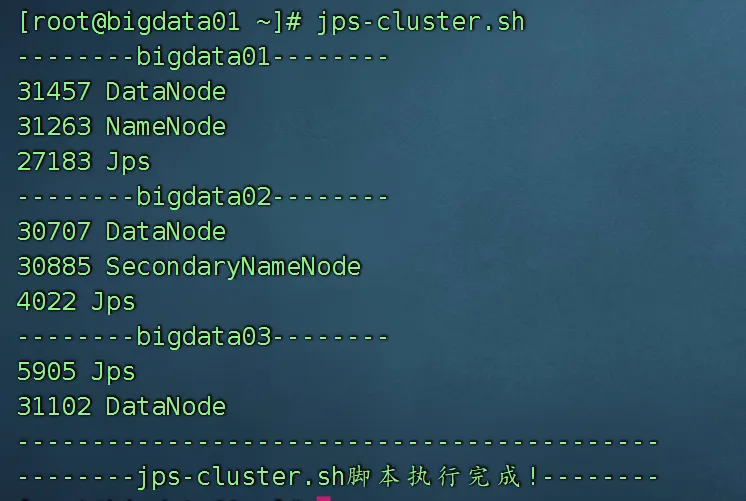
执行效果:
[root@node01 ~]# jps-cluster.sh
===== bigdata02 进程状态 =====
2345 NodeManager
3456 DataNode
===== bigdata03 进程状态 =====
2468 NodeManager
3579 DataNode二、「集群秒传」文件同步:xsync.sh
痛点暴击:改完/etc/profile要手动scp到其他节点?改一次配置半小时耗在拷贝上!
飞哥神操作:基于rsync写个批量分发脚本,目录 / 文件一键同步到所有节点,速度比scp快 3 倍!
🚀 脚本亮点
- 递归同步:支持多层目录,比如同步 Hadoop 配置文件夹无需逐层操作
- 自动建目录:目标节点没路径?脚本自动
mkdir -p,拒绝「No such file」报错 - 避坑提醒:全程在 Linux 编辑!Windows 的换行符会让脚本变「砖」
📝 代码解析(带防呆检查)
#!/bin/bash
pcount=$#
if [ $pcount -lt 1 ]; then echo "兄弟,传参啊!"; exit; fi # 没参数直接报错
for host in bigdata02 bigdata03; do
echo "===== 同步到 $host ====="
for file in $@; do
if [ -e $file ]; then
pdir=$(cd -P $(dirname $file); pwd) # 获取绝对路径,避免相对路径坑
fname=$(basename $file)
ssh $host "source /etc/profile; mkdir -p $pdir" # 先创建目录
rsync -av $pdir/$fname $USER@$host:$pdir # 增量同步,只传变化内容
else
echo "$file 不存在!别坑我了"
fi
done
done真香案例:
# 同步hosts文件到所有节点
xsync.sh /etc/hosts
# 同步Hadoop配置(含子目录)
xsync.sh /opt/hadoop-3.3.6/etc/hadoop/三、「集群广播」命令执行:xcall.sh
痛点暴击:装个ntpdate要在每个节点敲一遍命令?输错一个字母就得重来!
飞哥神操作:写个命令分发脚本,一条指令让所有节点同步执行,敲一次等于敲 10 次!
🚀 脚本亮点
- 参数透传:支持任意 Linux 命令,比如
yum install、systemctl restart - 路径兼容:配合软链接实现「裸命令」调用,不用写全路径
- 批量执行:循环节点 +
ssh直连,100ms 内完成集群操作
📝 极简代码(3 行搞定)
#!/bin/bash
params=$@
for ((i=2; i<=3; i++)); do # 节点命名为bigdata02/bigdata03
echo "===== bigdata0$i 执行: $params ====="
ssh bigdata0$i "$params" # 直接传递任意命令
done实战演示:
# 批量安装ntpdate(3台节点同时装)
xcall.sh yum install -y ntpdate
# 同步阿里云时间(需先装ntpdate)
xcall.sh ntpdate time1.aliyun.com
# 跨节点执行jps(先创建软链接)
xcall.sh ln -s /opt/jdk/bin/jps /usr/local/bin/jps # 建立软链接
xcall.sh jps # 直接调用,效果同jps-cluster.sh四、飞哥私藏技巧:脚本进阶玩法
- 节点列表外置:把
bigdata02/bigdata03写成nodes.txt文件,集群扩容时直接改文件 - 日志追踪:加一行
echo "$(date) $host $file" >> sync.log,出错时能快速回溯 - 危险操作防护:对
rm、mv等命令加确认弹窗:
if [[ $params == *"rm"* ]]; then read -p "确认执行?(y/n)" -n 1; [[ $REPLY == y ]] || exit; fi装逼小技巧:用toilet命令给脚本加 ASCII 标题(需先装toilet):
# jps-cluster.sh开头
toilet -f term -F border JPS CLUSTER 五、最后送兄弟们一句话
真正的运维高手,都是「懒」出来的—— 能用脚本解决的事,坚决不手动!这 3 个脚本我至今还在生产环境用,每次看到新人手动敲scp,我都会默默发链接(深藏功与名)
需要完整脚本的兄弟,关注【小飞敲代码】,私信回复「集群脚本」即可获取!你平时最烦的集群重复操作是啥?评论区留言,飞哥帮你写脚本定制解决方案~
下期预告:《Hadoop 数据倾斜终极解决方案:我是如何把任务执行时间从 4 小时压到 20 分钟的》

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









