






点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:3D视觉工坊
添加小助理:cv3d001,备注:方向+学校/公司+昵称,拉你入群。文末附3D视觉行业细分群。
扫描下方二维码,加入「3D视觉从入门到精通」知识星球(点开有惊喜),星球内凝聚了众多3D视觉实战问题,以及各个模块的学习资料:近20门秘制视频课程、最新顶会论文、计算机视觉书籍、优质3D视觉算法源码等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

0.这篇文章干了啥?
这篇文章提出了LIFT-GS,一个不依赖3D监督的通用训练管道,旨在通过结合高斯溅射(Gaussian Splatting)和2D基础模型来实现3D定位。LIFT-GS能够在零-shot环境下进行3D定位,并通过有限3D数据微调显著提升下游任务的性能。它不仅能有效扩展到大规模数据集,并且随着2D基础模型的增强,性能不断提升,表明在更强的数据支持下,模型能够获得更好的3D推理能力。
下面一起来阅读一下这项工作~
1. 论文信息
论文题目:LIFT-GS: Cross-Scene Render-Supervised Distillation for 3D Language Grounding
作者:Ang Cao,Sergio Arnaud等
作者机构:University of Michigan, Ann Arbor 等
论文链接:https://arxiv.org/pdf/2502.20389
2. 摘要
我们训练 3D 视觉-语言理解模型的方法是训练一个前馈模型,该模型在 3D 空间进行预测,但从不需要 3D 标签,只在 2D 中进行监督,使用 2D 损失和可微渲染。这种方法在视觉-语言理解领域是全新的。通过将重建视为“潜变量”,我们可以在不对网络架构施加不必要约束的情况下渲染输出(例如,可以与仅解码器模型一起使用)。在训练过程中,只需要图像、相机姿态和 2D 标签。我们证明,通过使用来自预训练 2D 模型的伪标签,甚至可以去除对 2D 标签的需求。我们展示了如何使用这种方法进行预训练,并将其微调以用于 3D 视觉-语言理解任务。我们证明,这种方法在 3D 视觉-语言定位任务中优于基准/当前最先进的方法,并且也超越了其他 3D 预训练技术。项目页面:https://liftgs.github.io
3. 效果展示
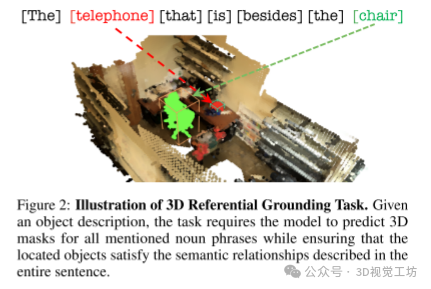
3D参考接地任务的图示。给定一个对象描述,该任务要求模型为所有提到的名词短语预测3D掩码,同时确保定位的对象满足整个句子中描述的语义关系。
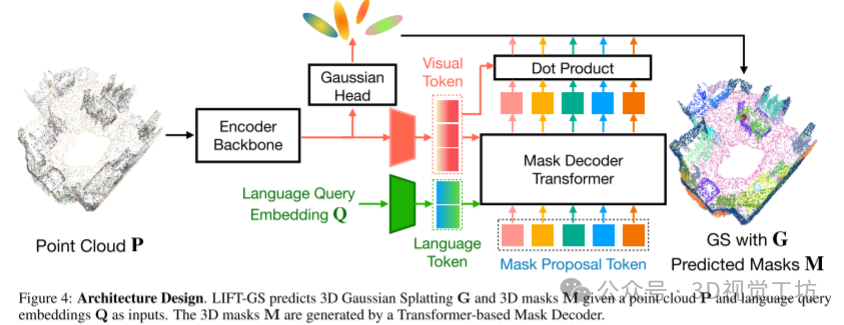
4. 主要贡献
可微渲染作为训练大规模 3D 可提示分割模型的工具。我们并未提出一个新的架构,而是通过使用可微渲染和结构化的 2D 定位损失来训练模型。
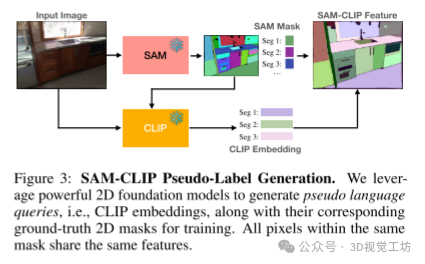
一种伪标签策略,用于将 2D 视觉-语言定位管道蒸馏为 3D 版本。预训练的 2D 模型仅用于伪标签,并且在推理过程中不需要它们。
最先进的性能和现实评估。我们通过使用传感器点云(在具身设置中常见)展示了该方法的有效性。严格的实验表明,该方法具有最先进的性能,并揭示了其规模特性。
5. 基本原理是啥?
LIFT-GS的基本原理是通过结合高斯溅射(Gaussian Splatting)技术和2D基础模型来训练3D视觉语言引导(3D VLG)模型,而无需依赖传统的3D监督数据。这种方法使得模型能够在没有明确的3D标注数据的情况下,进行“零-shot”的3D定位,即直接将2D图像中的信息扩展到3D空间中。
高斯溅射(Gaussian Splatting):
高斯溅射是一种将图像中的像素或特征点映射到3D空间中的方法。它通过在3D空间中创建具有不同强度和位置的高斯分布,来表示图像的深度和几何特征,从而实现2D到3D的映射。推荐课程:彻底搞懂3D人脸重建原理,从基础知识、算法讲解、代码解读和落地应用。2D基础模型:
利用已有的强大2D基础模型(如预训练的视觉模型),LIFT-GS能够在没有直接3D标注数据的情况下进行训练。这些模型可以捕捉到丰富的图像特征和语义信息,帮助在3D空间中进行准确的推理。零-shot 3D定位:
LIFT-GS可以在没有3D标注的情况下,直接基于2D图像进行3D定位,这意味着它能够处理没有经过标注的3D数据,并且在多种场景中进行3D推理。
6. 实验结果
零-shot 3D定位:
LIFT-GS在无需任何3D监督数据的情况下,成功地进行了零-shot 3D定位任务。通过将2D图像和高斯溅射技术结合,LIFT-GS能够直接从2D输入推断出相应的3D信息。这意味着它不依赖于传统的3D标注数据,能够在各种不同的环境和任务中进行有效的3D理解。有限3D数据微调:
在进行有限3D数据微调时,LIFT-GS的表现得到了显著提升。通过利用有限数量的3D数据进行进一步的训练,LIFT-GS能够显著提高下游任务(如3D物体检测、空间定位等)的精度和性能。这表明,LIFT-GS能够有效地利用少量的3D标注数据来提升模型的能力。数据规模和2D基础模型的扩展性:
LIFT-GS的性能随着数据规模的增加而持续提升。在使用更大的数据集和更强大的2D基础模型时,LIFT-GS展示了更好的扩展性和性能。这说明,随着更多的2D图像数据和更强的2D模型的结合,LIFT-GS能够持续提高其3D推理能力。与传统方法的对比:
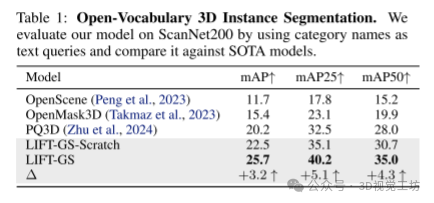
在与传统的基于3D监督的模型进行对比时,LIFT-GS显示了相当或更好的性能,尤其是在数据匮乏的情况下。通过不依赖昂贵和难以获取的3D标注数据,LIFT-GS能够在低数据条件下仍保持良好的性能,提供了一种更加灵活和可扩展的训练方式。

7. 总结 & 未来工作
我们提出了LIFT-GS,一个模型无关的管道,用于在没有3D监督的情况下训练3D VLG模型,利用高斯溅射和2D基础模型。LIFT-GS不仅实现了零-shot 3D定位,而且在使用有限的3D数据进行微调时显著提高了下游性能。它还具备有效扩展的能力,能够从更大的数据集和更强的2D基础模型中受益,表明随着数据的增加,性能会持续改进。局限性和未来的方向将在附录中讨论。
本文仅做学术分享,如有侵权,请联系删文。


3D视觉交流群,成立啦!
目前我们已经建立了3D视觉方向多个社群,包括2D计算机视觉、最前沿、工业3D视觉、SLAM、自动驾驶、三维重建、无人机等方向,细分群包括:
工业3D视觉:相机标定、立体匹配、三维点云、结构光、机械臂抓取、缺陷检测、6D位姿估计、相位偏折术、Halcon、摄影测量、阵列相机、光度立体视觉等。
SLAM:视觉SLAM、激光SLAM、语义SLAM、滤波算法、多传感器融合、多传感器标定、动态SLAM、MOT SLAM、NeRF SLAM、机器人导航等。
自动驾驶:深度估计、Transformer、毫米波|激光雷达|视觉摄像头传感器、多传感器标定、多传感器融合、3D目标检测、路径规划、轨迹预测、3D点云分割、模型部署、车道线检测、Occupancy、目标跟踪等。
三维重建:3DGS、NeRF、多视图几何、OpenMVS、MVSNet、colmap、纹理贴图等
无人机:四旋翼建模、无人机飞控等
2D计算机视觉:图像分类/分割、目标/检测、医学影像、GAN、OCR、2D缺陷检测、遥感测绘、超分辨率、人脸检测、行为识别、模型量化剪枝、迁移学习、人体姿态估计等
最前沿:具身智能、大模型、Mamba、扩散模型、图像/视频生成等
除了这些,还有求职、硬件选型、视觉产品落地、产品、行业新闻等交流群
添加小助理: cv3d001,备注:研究方向+学校/公司+昵称(如3D点云+清华+小草莓), 拉你入群。

3D视觉工坊知识星球
「3D视觉从入门到精通」知识星球(点开有惊喜),已沉淀6年,星球内资料包括:秘制视频课程近20门(包括结构光三维重建、相机标定、SLAM、深度估计、3D目标检测、3DGS顶会带读课程、三维点云等)、项目对接、3D视觉学习路线总结、最新顶会论文&代码、3D视觉行业最新模组、3D视觉优质源码汇总、书籍推荐、编程基础&学习工具、实战项目&作业、求职招聘&面经&面试题等等。欢迎加入3D视觉从入门到精通知识星球,一起学习进步。

卡尔曼滤波、大模型、扩散模型、具身智能、3DGS、NeRF、结构光、相位偏折术、机械臂抓取、点云实战、Open3D、缺陷检测、BEV感知、Occupancy、Transformer、模型部署、3D目标检测、深度估计、多传感器标定、规划与控制、无人机仿真、C++、三维视觉python、dToF、相机标定、ROS2、机器人控制规划、LeGo-LAOM、多模态融合SLAM、LOAM-SLAM、室内室外SLAM、VINS-Fusion、ORB-SLAM3、MVSNet三维重建、colmap、线面结构光、硬件结构光扫描仪等。

3D视觉模组选型:www.3dcver.com

— 完 —
点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
3D视觉科技前沿进展日日相见 ~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









