






点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:3D视觉工坊
添加小助理:cv3d001,备注:方向+学校/公司+昵称,拉你入群。文末附3D视觉行业细分群。
扫描下方二维码,加入「3D视觉从入门到精通」知识星球(点开有惊喜),星球内凝聚了众多3D视觉实战问题,以及各个模块的学习资料:近20门秘制视频课程、最新顶会论文、计算机视觉书籍、优质3D视觉算法源码等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

0. 论文信息
标题:Segment Anything, Even Occluded
作者:Wei-En Tai, Yu-Lin Shih, Cheng Sun, Yu-Chiang Frank Wang, Hwann-Tzong Chen
机构:National Tsing Hua University、NVIDIA、National Taiwan University、Aeolus Robotics
原文链接:https://arxiv.org/abs/2503.06261
1. 导读
模型实例分割旨在检测和分割图像中物体的可见和不可见部分,在包括自动驾驶、机器人操作和场景理解在内的各种应用中起着至关重要的作用。虽然现有的方法需要联合训练前端检测器和掩码解码器,但是这种方法缺乏灵活性,并且不能利用预先存在的模态检测器的优势。为了解决这一限制,我们提出了SAMEO,这是一种新的框架,它将Segment Anything Model (SAM)作为一种通用的掩模解码器,能够与各种前端检测器接口,即使对于部分遮挡的对象也能够进行掩模预测。认识到有限的阿莫达尔分割数据集的限制,我们引入了阿莫达尔-LVIS,这是一个大规模的合成数据集,包含从模态LVIS和LVVIS数据集导出的300K图像。该数据集极大地扩展了可用于模型分割研究的训练数据。我们的实验结果表明,当我们的方法在新扩展的数据集上训练时,包括阿莫达尔-LVIS,在COCOA-cls和D2SA基准上实现了显著的零射击性能,突出了其推广到未知场景的潜力。
2. 效果展示
.模态分割示例:顶部一排显示原始图像。中间一排显示EfficientSAM预测的模态掩码,仅覆盖物体的可见部分。底部一排显示我们的方法预测的完整物体形状的模态掩码,即使在遮挡下也能分割任何物体


3. 引言
人类视觉感知不仅局限于场景中直接可见的部分。我们可以自然地通过对象识别和关于对象类别的先验知识的结合,来想象和理解部分遮挡物体的完整形状。即使正确分类物体存在困难,我们也通常可以通过分析可见部分并推断常见的遮挡模式来推测部分可见物体的完整形状。无模态实例分割旨在通过检测和定位图像中的物体,并预测其完整形状(包括可见部分和遮挡部分),来复制人类这一非凡的能力。
解决无模态实例分割问题的一种有效方法是将任务分解为两个主要部分:对象检测和掩码分割。近年来,对象检测取得了显著进展,如RTMDet和ConvNeXt-V2等先进模型均表现出令人瞩目的性能。推荐课程:扩散模型入门教程:数学原理、方法与应用。
然而,当前的无模态分割方法往往需要将检测器和掩码解码器联合训练,这阻碍了它们充分利用这些强大的预训练模态检测器。这一局限性促使我们开发了一个更灵活的框架,该框架能够在利用现有模态检测器的同时,仍然保持强大的无模态分割能力。视觉理解基础模型的出现为分割任务带来了新的可能性。其中,Segment Anything Model(SAM)及其高效变体EfficientSAM在基于提示的模态分割中展示了卓越的能力。我们利用EfficientSAM的架构,该架构包含一个用于更快推理的轻量级编码器,并通过专门训练将其适应于无模态分割。我们的方法使模型能够处理无模态和模态提示,以生成无模态掩码预测,同时保持潜在的零样本能力。
除了算法和架构的改进外,对于基于学习的方法而言,数据集也至关重要,然而当前的无模态分割数据集面临多项挑战:
• 规模有限:现有数据集包含的图像相对较少,阻碍了稳健模型的开发。
• 标注质量:一些依赖于自动生成方法的数据集,如果未经过适当验证,可能会导致实例标注不一致,有时甚至错误。
• 无关对象:大量标注对象(如墙壁和地板)对有意义的场景理解贡献甚微。
为解决这些局限性,我们提出了Amodal-LVIS,这是一个从LVIS和LVVIS派生的新大型数据集。我们的数据集包含30万张精心挑选的图像,每张图像包含一个实例标注。这些标注在合成遮挡实例和其原始未遮挡版本之间形成了配对示例。此外,我们还处理和精炼了现有数据集,创建了包含约100万张图像和200万个实例标注的综合训练集。
实验结果表明,当在我们的合并数据集上训练时,采用EfficientSAM架构的方法实现了卓越的零样本性能,超越了以往的有监督无模态分割方法。这些结果验证了我们利用高效现有架构和高质量大型训练数据进行无模态分割任务的方法的有效性。
4. 主要贡献
我们的主要贡献可以概括如下:
灵活的无模态框架:提出的方法SAMEO通过专门训练将EfficientSAM适应于无模态实例分割,该方法可与模态和无模态检测器提示一起工作。
大型数据集:新的Amodal-LVIS数据集包含30万张图像,在合成遮挡实例和其原始未遮挡版本之间形成了配对示例。
数据集收集:通过结合和精炼现有无模态数据集与Amodal-LVIS,创建了包含100万张图像和200万个实例的综合训练集。
零样本性能:在COCOA-cls和D2SA基准测试中取得了最先进的零样本结果,超越了以往的有监督方法。
5. 方法
.我们的非模态分割管道概述。给定一张输入图像,现有的目标检测器首先生成模态框(显示可见区域)或非模态框(显示完整的物体范围)。我们的SAMEO然后处理这些检测,以生成非模态掩码,恢复物体的完整形状,包括被遮挡的部分。

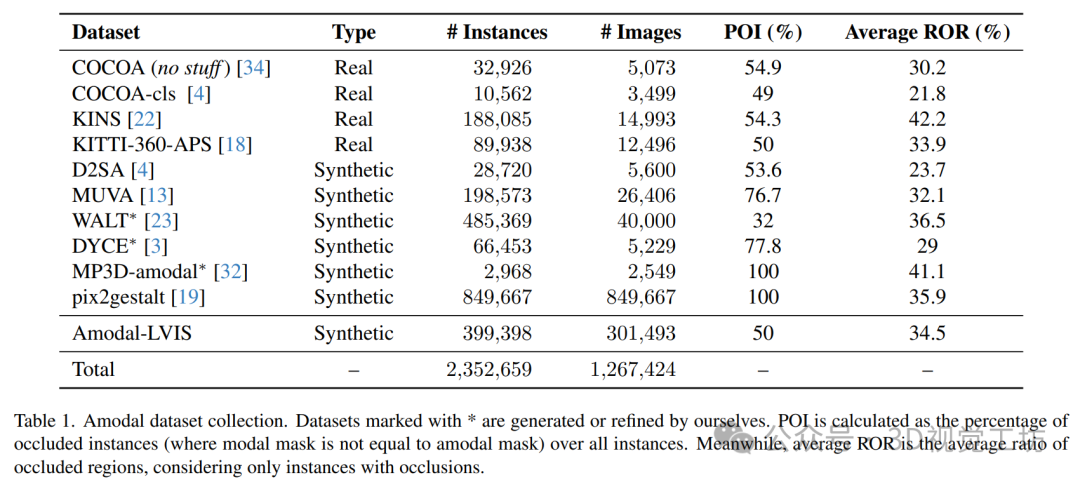
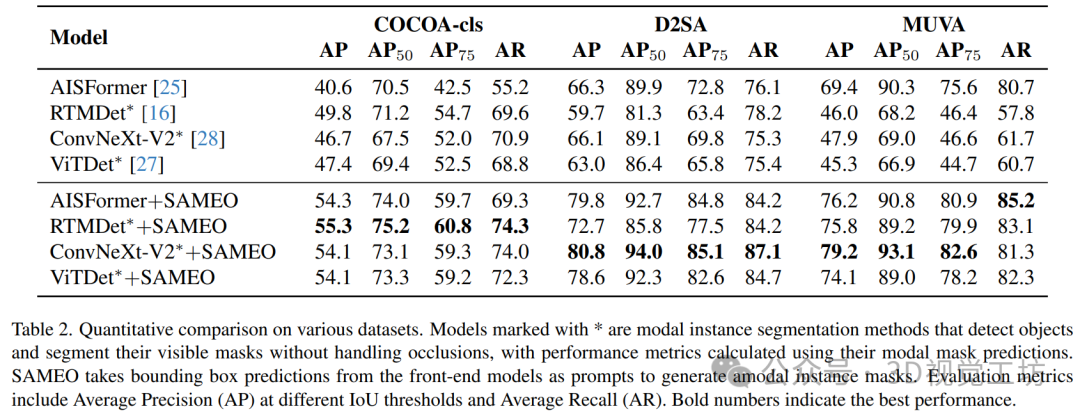
6. 实验结果
7. 总结 & 未来工作
我们提出了一种灵活的多模态实例分割方法,通过调整基础分割模型来处理物体的可见部分和遮挡部分。我们的框架成功利用了预训练的模态检测器,同时保持了强大的多模态分割能力。Amodal-LVIS的引入,包含30万张精心挑选的像,以及我们综合的100万张图像和200万个实例注释,解决了现有数据集的关键局限性,并为稳健的模型开发提供了必要的规模。
我们的广泛实验表明,SAMEO在COCOA-cls.D2SA和MUVA数据集上始终优于最先进的方法。最值得注意的是,当在包括Amodal-LVIS在内的我们的数据集上进行训练时,SAMEO在未见过的数据集上实现了强大的零样本性能。该模型在各种前端检测器上的稳健泛化能力得以保持,验证了我们在不牺牲性能的情况下适应基础模型进行非局部分割的方法。我们在附录中进一步讨论了SAMEO的局限性以及可能的未来工作。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
本文仅做学术分享,如有侵权,请联系删文。


3D视觉交流群,成立啦!
目前我们已经建立了3D视觉方向多个社群,包括2D计算机视觉、最前沿、工业3D视觉、SLAM、自动驾驶、三维重建、无人机等方向,细分群包括:
工业3D视觉:相机标定、立体匹配、三维点云、结构光、机械臂抓取、缺陷检测、6D位姿估计、相位偏折术、Halcon、摄影测量、阵列相机、光度立体视觉等。
SLAM:视觉SLAM、激光SLAM、语义SLAM、滤波算法、多传感器融合、多传感器标定、动态SLAM、MOT SLAM、NeRF SLAM、机器人导航等。
自动驾驶:深度估计、Transformer、毫米波|激光雷达|视觉摄像头传感器、多传感器标定、多传感器融合、3D目标检测、路径规划、轨迹预测、3D点云分割、模型部署、车道线检测、Occupancy、目标跟踪等。
三维重建:3DGS、NeRF、多视图几何、OpenMVS、MVSNet、colmap、纹理贴图等
无人机:四旋翼建模、无人机飞控等
2D计算机视觉:图像分类/分割、目标/检测、医学影像、GAN、OCR、2D缺陷检测、遥感测绘、超分辨率、人脸检测、行为识别、模型量化剪枝、迁移学习、人体姿态估计等
最前沿:具身智能、大模型、Mamba、扩散模型、图像/视频生成等
除了这些,还有求职、硬件选型、视觉产品落地、产品、行业新闻等交流群
添加小助理: cv3d001,备注:研究方向+学校/公司+昵称(如3D点云+清华+小草莓), 拉你入群。

3D视觉工坊知识星球
「3D视觉从入门到精通」知识星球(点开有惊喜),已沉淀6年,星球内资料包括:秘制视频课程近20门(包括结构光三维重建、相机标定、SLAM、深度估计、3D目标检测、3DGS顶会带读课程、三维点云等)、项目对接、3D视觉学习路线总结、最新顶会论文&代码、3D视觉行业最新模组、3D视觉优质源码汇总、书籍推荐、编程基础&学习工具、实战项目&作业、求职招聘&面经&面试题等等。欢迎加入3D视觉从入门到精通知识星球,一起学习进步。

卡尔曼滤波、大模型、扩散模型、具身智能、3DGS、NeRF、结构光、相位偏折术、机械臂抓取、点云实战、Open3D、缺陷检测、BEV感知、Occupancy、Transformer、模型部署、3D目标检测、深度估计、多传感器标定、规划与控制、无人机仿真、C++、三维视觉python、dToF、相机标定、ROS2、机器人控制规划、LeGo-LAOM、多模态融合SLAM、LOAM-SLAM、室内室外SLAM、VINS-Fusion、ORB-SLAM3、MVSNet三维重建、colmap、线面结构光、硬件结构光扫描仪等。

3D视觉模组选型:www.3dcver.com

— 完 —
点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
3D视觉科技前沿进展日日相见 ~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









