






点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:3D视觉工坊
添加小助理:cv3d001,备注:方向+单位+昵称,拉你入群。文末附行业细分群。
扫描下方二维码,加入「3D视觉从入门到精通」知识星球(点开有惊喜),星球内汇总了众多3D视觉实战问题,以及各个模块的学习资料,包括20+门独家视频课程、100+场顶会直播讲解、最新顶会论文分享、计算机视觉书籍、优质3D视觉算法源码、3D视觉入门环境配置教程、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

0.论文信息
标题:NuGrounding: A Multi-View 3D Visual Grounding Framework in Autonomous Driving
作者:Fuhao Li, Huan Jin, Bin Gao, Liaoyuan Fan, Lihui Jiang, Long Zeng
机构:清华大学、华为、香港大学
原文链接:https://arxiv.org/abs/2503.22436
1.这篇文章干了啥
多视角3D视觉定位是实现自动驾驶系统自然语言理解与复杂环境感知的关键环节。然而,现有的数据集和方法通常受限于粗粒度的语言指令,且缺乏对三维几何定位与语言指令的深度融合。为此,作者引入了NuGrounding数据集,首个面向自动驾驶场景的大规模多视角3D视觉定位基准数据集。其次,为有效应对NuGrounding数据集所提出的挑战,作者设计了一种新颖的模型范式,有机结合了多模态大语言模型在指令理解方面的优势与视觉检测专有模型在定位精度上的能力,实现了复杂人类指令理解下的精确物体定位。
下面一起来阅读一下这项工作~
2.主要贡献
作者的贡献可以总结为以下几点:
引入了NuGrounding数据集,这是首个面向自动驾驶的多视角3D视觉定位大规模数据集。为确保数据集的多样性、可扩展性和泛化能力,提出了层次化构建(HoG)方法来构建NuGrounding。
提出了多视角3D视觉定位模型框架,这是一种新颖的范式,巧妙地将多模态大模型的指令理解能力与专有检测模型的精确物体定位能力结合起来。
将现有的主流方法适配到NuGrounding数据集上并进行了评估,建立了一个全面的基准。实验结果表明,作者的模型框架显著超越了适配后的基线,精度提高了50.8%,召回率提高了54.7%。
3.多视角3D视觉定位数据集
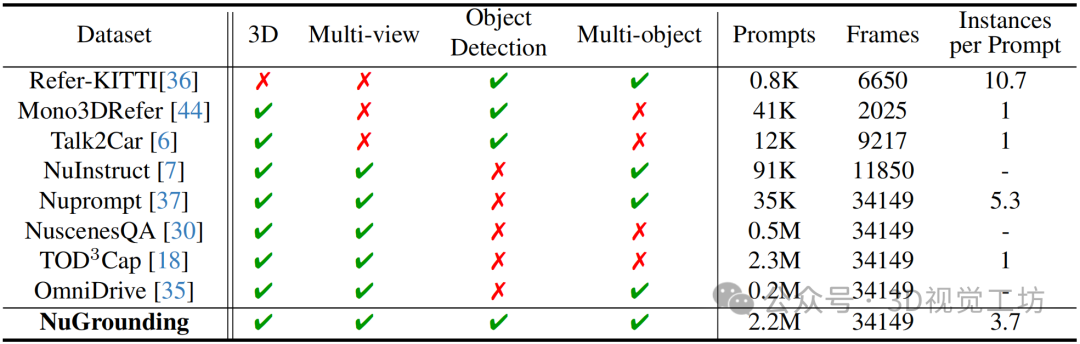
尽管基于语言的自动驾驶系统在近年来取得了长足进展,现有的数据集在满足多视角3D视觉定位需求方面仍显不足。其主要限制体现在:指令设计过于简化、数据规模受限以及任务设置粒度偏粗,难以支持精细化的目标定位任务。如上表所示,以往的视觉定位数据集多聚焦于二维图像中的像素级目标定位,缺乏对三维几何结构的建模能力;而部分数据集虽具备三维要素,但仍局限于单一视角图像,忽略了多视角融合在场景理解中的重要作用。此外,这些数据集在语言指令的多样性和覆盖范围方面也存在明显短板,难以涵盖复杂的实际场景和多变的语言表达。最近的相关研究大多集中在场景级的语言理解任务(如视觉问答)或单物体的描述与定位任务(如稠密语言标注),尚未能充分解决实例级、多目标、多视角的精细定位挑战。
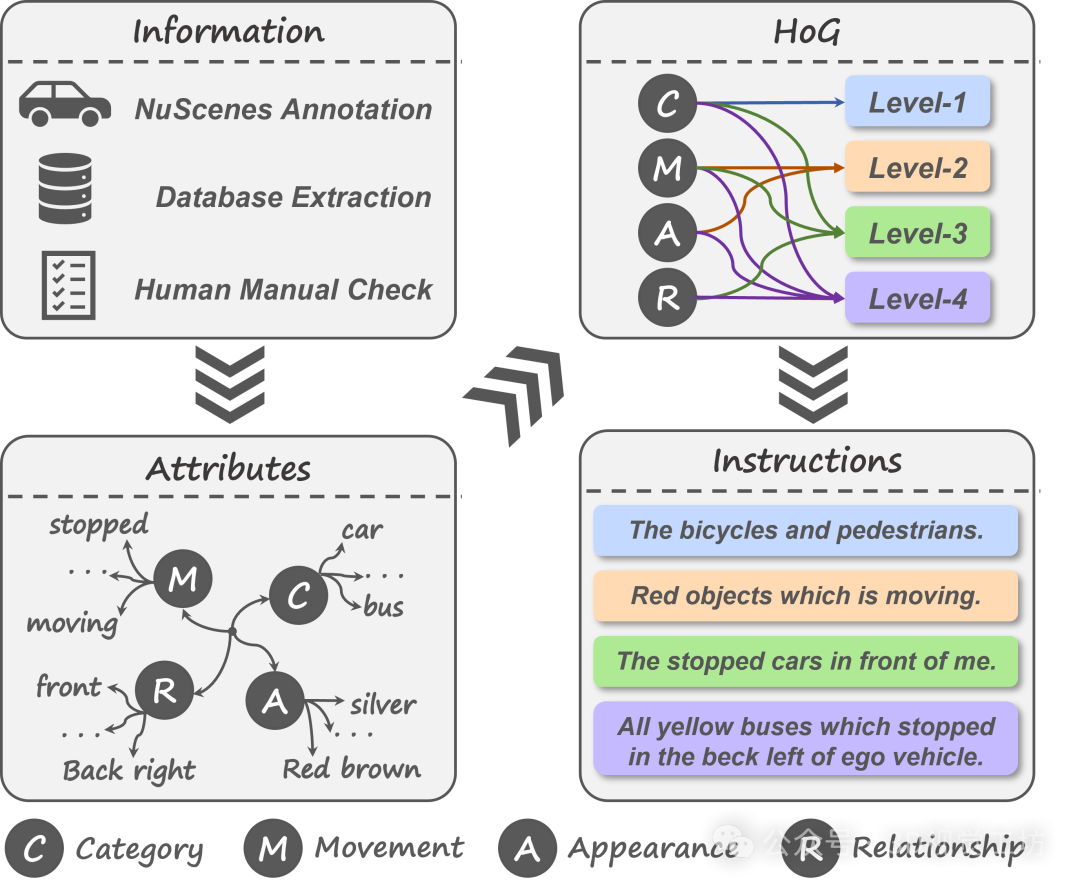
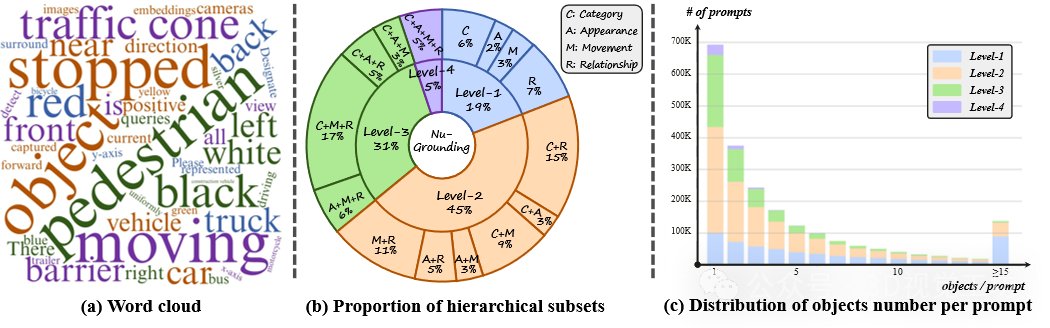
为填补这些空白,作者引入了NuGrounding数据集,这是首个面向自动驾驶的多视角3D视觉定位大规模基准数据集。与先前的工作不同,NuGrounding支持多物体、实例级定位,并在文本指令的复杂性和数量上达到平衡。构建方法如上图所示。首先,基于NuScenes通过自动标注和人工验证的方式为每个物体注释多种的常见属性。其次,为了更全面地覆盖人类语言描述模式、防止大语言模型采用发生归纳偏置而忽略部分物体细粒度属性,作者设计了层次化构建(HoG)方法来构建数据集,涵盖多个层次和语义维度。最后,对该数据集进行了多层样本数量分布统计和每个指令对应的平均物体数量统计,如下图所示。
4.多视角3D视觉定位方法
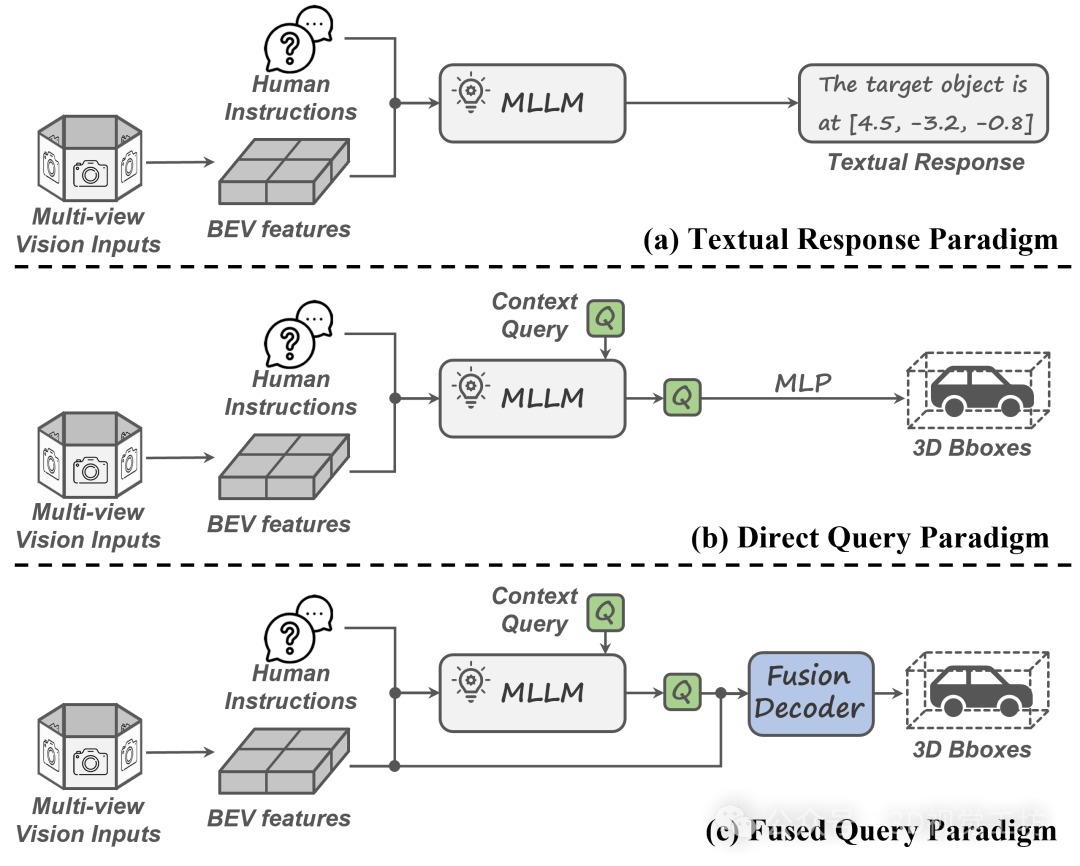
多视角3D视觉定位任务对模型在复杂语言理解与精细场景感知方面提出了更高要求。如上图(a)所示,现有方法通常将多视角图像编码为BEV(Bird's Eye View)特征图,并将三维空间推理能力融入多模态大语言模型。然而此类方法主要优化目标偏向文本生成,因此在精确物体定位方面存在明显局限。为提升空间精度,近期研究如上图(b)所示,引入了3D query机制,试图将LLM的隐藏层向量表示解码回归为3D边界框。然而,这些query向量通常处于语义空间,缺乏对3D几何细节的直接建模能力,从而影响了最终定位效果。为解决上述问题,作者提出了一种全新的多视角3D视觉定位框架,其核心思想在于将多模态大模型在语言理解方面的优势与专有检测模型在几何感知与定位方面的精度能力进行解耦融合,如上图(c)所示。具体来说,该框架的整体结构如下图所示。
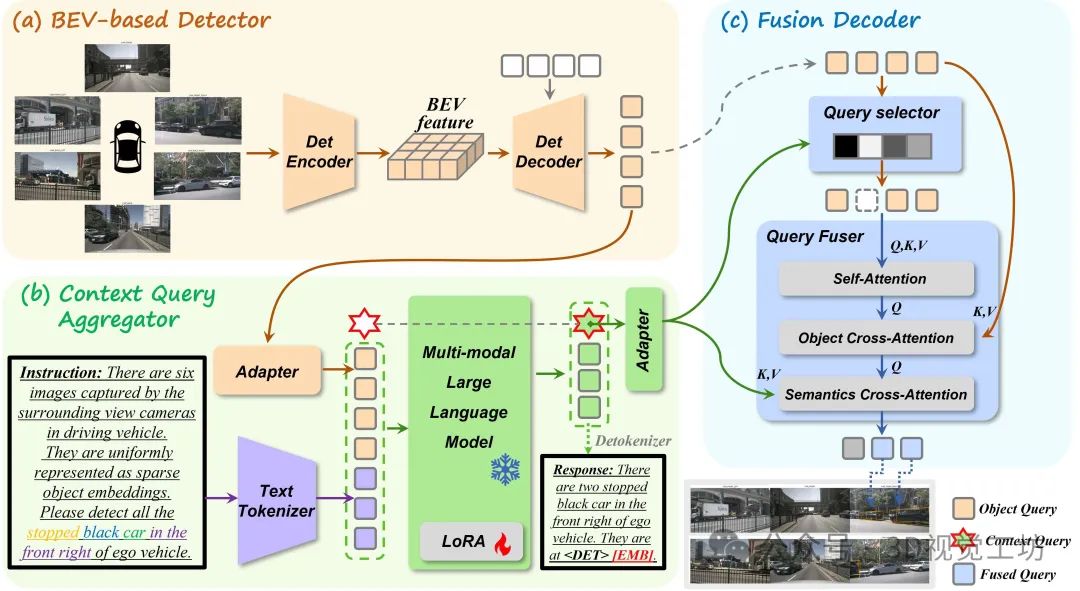
提出的多视角3D视觉定位框架由三个关键模块组成:基于BEV的检测模块、上下文聚合模块以及融合解码模块。首先,在基于BEV的检测模块中,采用专有检测编码器,从多视角图像中提取稠密BEV特征图。随后,借助基于Query的检测解码器,利用这些BEV特征生成稀疏的实例级目标Query,以构建初步的场景表示。接着,在上下文聚合模块中,前述目标Query与用户提供的语言指令共同输入至多模态大语言模型。为实现更细致的任务表示,引入了两个解耦的任务token以及一个可学习的上下文query。在文本回答生成过程中,MLLM基于任务token将三维场景信息与语言语义有效聚合,并编码进上下文query向量中,从而实现语言与视觉信息的深层融合。最后,在融合解码模块,通过计算上下文query与所有物体query之间的相关性,筛除语义无关或冗余的实例,从而降低噪声干扰。保留下来的物体query将与其他query交互以增强其空间信息,同时与上下文query交互以强化语义表达能力。最终得到的融合query被输入至专有解码器中,以完成最终的精准定位输出。
5.实验结果

由于目前尚无专门面向多视角3D视觉定位任务和数据集的标准方法,作者选择对现有的场景理解方案进行适配,并在构建的 NuGrounding数据集上进行系统评估。具体对比方法包括ELM、NuPrompt和OmniDrive,如上表所示。即便在仅采用轻量主干网络 V2-99的情况下,作者提出的方法在性能上依然全面超越现有主流方法。此外为提升推理效率,在模型中采用了ViT-B作为图像编码器主干,而非计算开销更大的ViT-L。尽管如此,作者的方法在关键指标上依然取得了优异表现,实现了0.59的精度、0.64的召回率、0.40的mAP和0.48的NDS,显著领先其他方法。
本文仅做学术分享,如有侵权,请联系删文。


3D硬件专区

「3D视觉从入门到精通」知识星球
扫描下方二维码,加入「3D视觉从入门到精通」知识星球(点开有惊喜),已沉淀7年,星球内资料包括:3D视觉系列视频近20+门、100+场直播顶会讲解、项目对接、3D视觉学习路线总结、最新顶会论文&代码、3D视觉行业最新模组、3D视觉优质源码汇总、书籍推荐、编程基础&学习工具、实战项目&作业、求职招聘&面经&面试题等。欢迎加入3D视觉从入门到精通知识星球,一起学习进步!

3D视觉全栈学习课程:www.3dcver.com

3D视觉交流群

点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
3D视觉科技前沿进展日日相见 ~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









