






一、锁的分类
| MySQL Lock | |
| Lock【S 锁】【X 锁】 | Latch |
| 表锁 | Mutex |
| 页锁 | ReadLock |
| 行锁 | WriteLock |
二、锁的粒度
| 表 | 页 | 行 | |
| InnoDB | ✔ | ✖ | ✔ |
| MyISAM | ✔ | ✖ | ✖ |
| BDB | ✔ | ✔ | ✖ |
三、意向锁
上节提到InnoDB 支持多种粒度的锁,也就是行锁和表锁。为了支持多粒度锁定,InnoDB 存储引擎引入了意向锁(Intention Lock)。
那什么是意向锁呢?我们在这里可以举一个例子:如果没有意向锁,当已经有人使用行锁对表中的某一行进行修改时,如果另外一个请求要对全表进行修改,那么就需要对所有的行是否被锁定进行扫描,在这种情况下,效率是非常低的;不过,在引入意向锁之后,当有人使用行锁对表中的某一行进行修改之前,会先为表添加意向排他锁(IX),再为行记录添加排他锁(X),在这时如果有人尝试对全表进行修改就不需要判断表中的每一行数据是否被加锁了,只需要通过等待意向排他锁被释放就可以了。
四、锁的兼容性
对数据的操作其实只有两种,也就是读和写,而数据库在实现锁时,也会对这两种操作使用不同的锁;InnoDB 实现了标准的行级锁,也就是共享锁(Shared Lock)和排他锁(Exclusive Lock)。
-
共享锁(读锁、S锁),允许事务读一行数据。
-
排他锁(写锁、X锁),允许事务删除或更新一行数据。
而它们的名字也暗示着各自的另外一个特性,共享锁之间是兼容的,而排他锁与其他任意锁都不兼容:
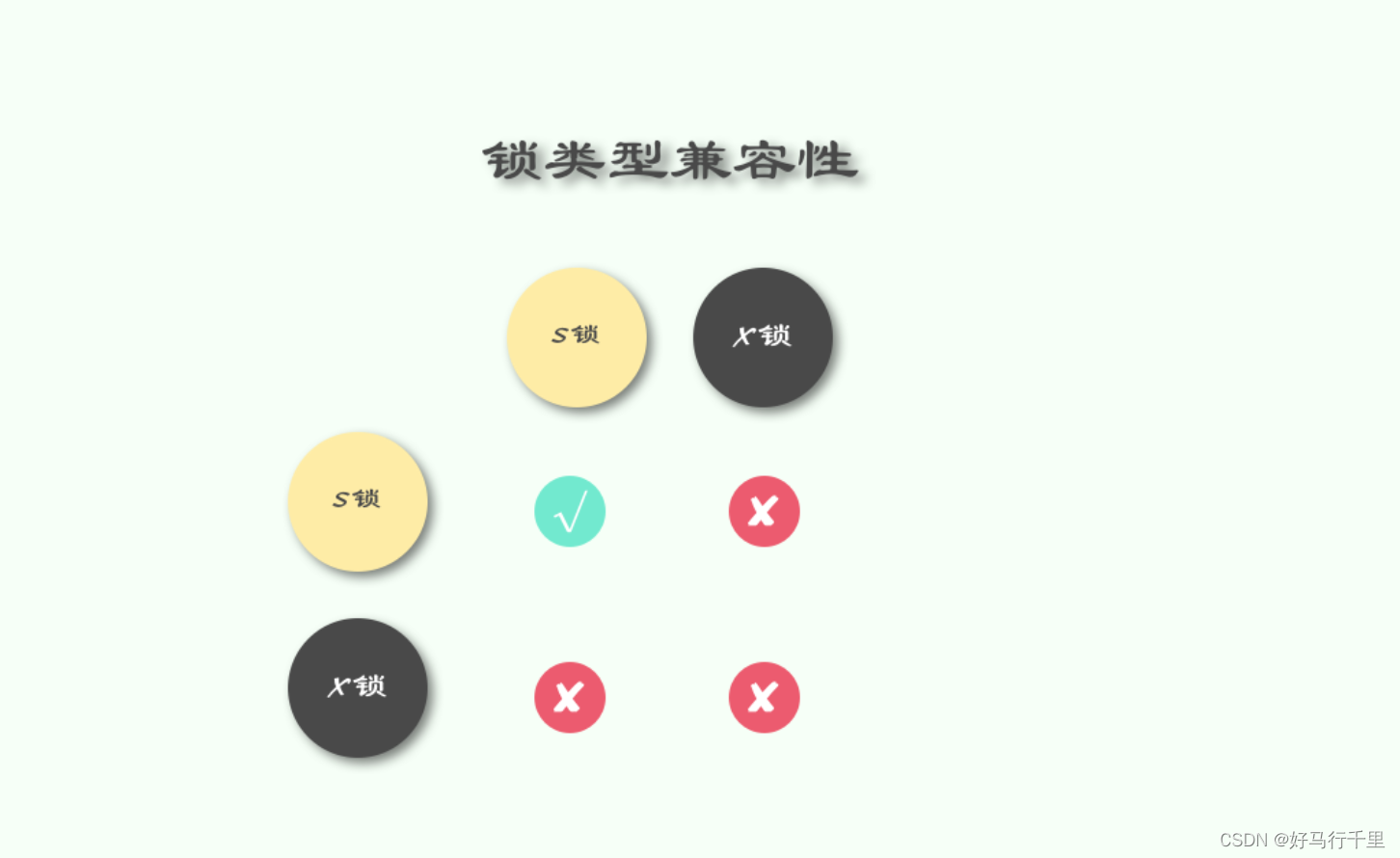
意向锁与其他锁的兼容性:

四、行锁算法
-
Record Lock:行锁,单个行记录上的锁。
-
Gap Lock:间隙锁,锁定一个范围,但不包括记录本身。GAP锁的目的,是为了防止幻读、防止间隙内有新数据插入、防止已存在的数据更新为间隙内的数据。
-
Next-Key Lock:1+2,锁定一个范围,并且锁定记录本身。对于行的查询,都是采用该方法,主要目的是解决幻读的问题。InnoDB默认加锁方式是next-key 锁。
五、自增锁
InnoDB存储引擎中,除了表锁、行锁外,还有一种特殊的锁是自增锁。当表的主键为自增列时,多个并发事务通过自增锁来保证自增主键不会出现重复等现象。
首先对自增长的insert语句分类:
| 插入类型 | 说明 |
|---|---|
| insert-like | 所有的插入语句,如insert,replace,insert .. select等 |
| simple inserts | 插入前就能确定行数的语句。例如insert、replace(不包括insert .. on duplicate key update) |
| bulk inserts | 插入前无法确定行数的语句。例如insert ... select, replace .. select ,load data |
| mixed inserts | 插入语句中,一部分是自增长的,一部分是确定的。如insert into t1(c1,c2) values(1,'a'),(NULL,'b'); |
MySQL中通过参数innodb_autoinc_lock_mode控制自增锁的行为,其可选值为0、1、2:
| innodb_autoinc_lock_mode | 说明 |
|---|---|
| 0 | 此时自增锁是表锁级别的,并发度最低。insert-like语句都需要加锁,在SQL执行完成或者回滚后才会释放(不是在事务完成后),这种情况下对自增锁的并发竞争是比较大的 |
| 1 | 此种情况下,并发度居中。对simple inserts语句做了优化,在获取到锁后,立即释放,不必再等待SQL执行完成。而对于bulk inserts语句仍然使用表级别的锁,等待SQL执行完后释放。 |
| 2 | 此种情况下,并发度最高。insert-like语句不会使用表级别的自增锁,而是通过互斥量产生。多条语句可同时执行。但是在binlog日志为基于语句格式场景下,会出现主从不一致的现象。 |















 8237
8237

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









