







已知有表结构如下:
CREATE TABLE test3 (
dt string,
order_id string,
user_id string,
amount DECIMAL ( 10, 2 ) )
ROW format delimited FIELDS TERMINATED BY '\t';
INSERT INTO TABLE test3 VALUES ('2017-01-01','10029028','1000003251',33.57);
INSERT INTO TABLE test3 VALUES ('2017-01-01','10029029','1000003251',33.57);
INSERT INTO TABLE test3 VALUES ('2017-01-01','100290288','1000003252',33.57);
INSERT INTO TABLE test3 VALUES ('2017-02-02','10029088','1000003251',33.57);
INSERT INTO TABLE test3 VALUES ('2017-02-02','10028888','1000008888',33.57);
INSERT INTO TABLE test3 VALUES ('2017-02-02','100290281','1000003251',33.57);
INSERT INTO TABLE test3 VALUES ('2017-02-02','100290282','1000003253',33.57);
INSERT INTO TABLE test3 VALUES ('2017-11-02','10290282','100003253',234);
INSERT INTO TABLE test3 VALUES ('2018-11-02','10290284','100003243',234);
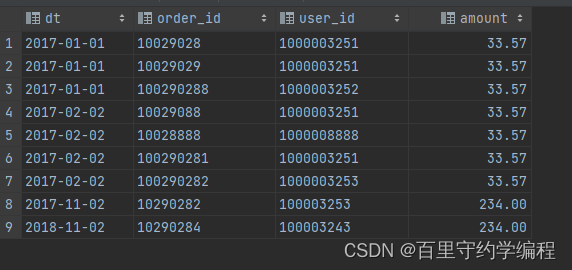
select * from test3;
请给出SQL进行统计:
(1)给出2017年每个月的订单数、用户数、总成交金额。
(2)给出2017年11月的新客数(指在11月才有第一笔订单)
第一题:简单的聚合统计即可,使用到date_format()函数,可见其接受date,timestamp,varchar(包括string)类型的时间参数,然后指定需要的结果格式,返回varchar类型的结果
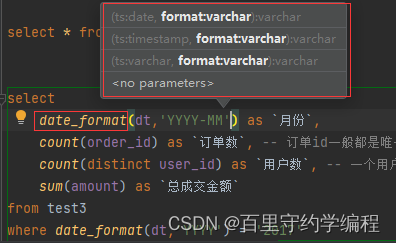
select
date_format(dt,'YYYY-MM') as `月份`,
count(order_id) as `订单数`, -- 订单id一般都是唯一键,所以不需要去重
count(distinct user_id) as `用户数`, -- 一个用户可以有多笔订单,所以统计用户的时候去重
sum(amount) as `总成交金额`
from test3
where date_format(dt,'YYYY') = '2017'
group by date_format(dt,'YYYY-MM');

第二题:需要统计的是2017年11月才有第一笔订单的用户数,首先需要知道每个用户的第一笔订单时间,即每个用户时间最早的订单,看到分组最XX,应该立马就能想到排序窗口函数了,即分组TopN问题的常规写法
第一步:获得每个用户的第一笔订单时间
第二步:筛选出第一笔订单时间在2017年11月的所有用户,统计总数即为结果
with t1 as (
select
user_id,
dt,
rank() over (partition by user_id order by dt) as rk
from test3
),
t2 as (
select
user_id,
dt
from t1
where rk = 1
)
select
count(user_id)
from t2
where date_format(dt,'YYYY-MM') = '2017-11';















 805
805











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









