









除非你活在太空里,完全脱离了现代社交媒体和新闻的关注,否则你不太可能错过大型语言模型
欢迎来到云闪世界。除非你活在太空里,完全脱离了现代社交媒体和新闻的关注,否则你不太可能错过大型语言模型 (LLM) 的突飞猛进带给我们生活中的革命性进步。
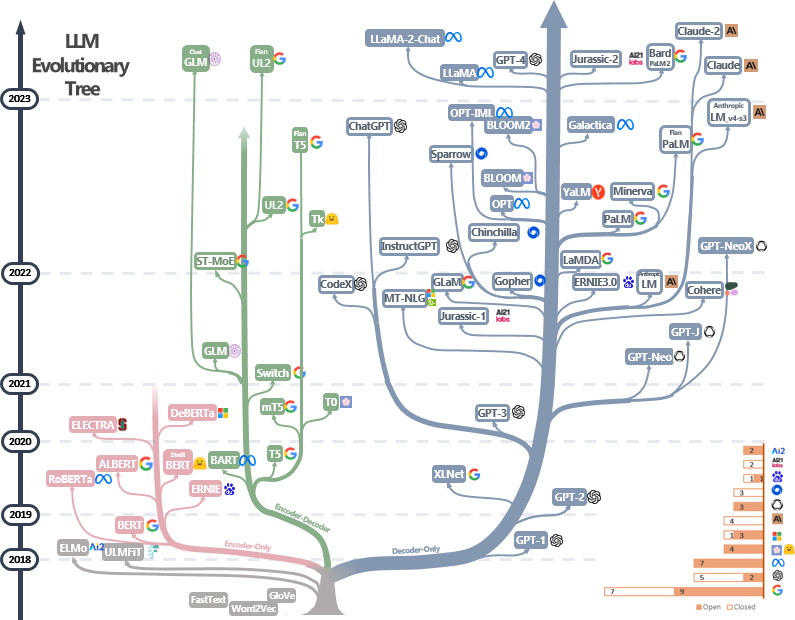
LLM 的演变。图片取自论文 [1] (来源)。即使我添加了这张图片,但当前 LLM 的发展速度也让这张图片变得过时了。
LLM 已经无处不在,几乎每天都会发布新模型。得益于蓬勃发展的开源社区,它们也更容易被公众使用,该社区在减少内存需求和开发 LLM 的高效微调方法(即使在计算资源有限的情况下)方面发挥了关键作用。
LLM 最令人兴奋的用例之一是,它们能够出色地完成未经过明确训练的任务,只需使用任务描述和一些示例即可。现在,您可以让有能力的 LLM 以您最喜欢的作家的风格创作故事,将长电子邮件总结为简洁的电子邮件,并通过向模型描述您的任务而无需对其进行微调来制定创新的营销活动。但您如何最好地将您的要求传达给 LLM?这就是提示的作用所在。
目录:
- 什么是提示?
- 为什么提示很重要?
- 探索不同的提示策略
- 我们如何实现这些技术?
4.1.使用零次提示提示 Llama 2 7B-Chat
4.2.使用少次提示提示 Llama 2 7B-Chat
4.3.如果我们不遵守聊天模板会发生什么?
4.4.使用 CoT 提示提示 Llama 2 7B-Chat
4.5. Llama 2 的 CoT 故障模式
4.6.使用零次提示提示 GPT-3.5
4.7.使用少次提示提示 GPT-3.5
4.8.使用 CoT 提示提示 GPT-3.5 - 结论和要点
- 可重复性
- 参考
什么是提示?
提示或提示工程是一种设计输入或提示的技术,用于引导人工智能模型(尤其是自然语言处理和图像生成中的模型)产生特定的期望输出。提示涉及将您的需求构造成一种输入格式,该格式可以有效地将期望的结果传达给模型,从而获得预期的输出。
大型语言模型 (LLM) 展示了上下文学习的能力[2] [3]。这意味着这些模型可以仅根据通过提示提供给模型的任务描述和示例来理解和执行各种任务,而无需针对每个新任务进行专门的微调。提示在这种情况下非常重要,因为它是用户和模型之间利用此功能的主要接口。定义明确的提示有助于向 LLM 定义任务的性质和期望,以及如何以可利用的方式向用户提供输出。
您可能倾向于认为,获得 LLM 学位应该不会那么难;毕竟,这只是用自然语言向模型描述您的要求,对吧?实际上,它并不那么简单。您会发现不同的 LLM 具有不同的优势。有些可能更好地遵循您想要的输出格式,而另一些可能需要更详细的说明。您希望 LLM 执行的任务可能很复杂,需要详细而精确的说明。因此,设计合适的提示通常需要大量的实验和基准测试。
为什么提示很重要?
在实践中,LLM 对输入的结构和提供方式非常敏感。我们可以从各个角度进行分析,以更好地了解情况:
- 遵守提示格式:LLM 通常使用不同的提示格式来接受用户输入。这通常在模型针对聊天用例进行指令调整或优化时完成 [4] [5]。在高层次上,大多数提示格式包括指令和输入。指令描述模型要执行的任务,而输入包含需要执行任务的文本。让我们以 Alpaca 指令格式为例(取自GitHub - tatsu-lab/stanford_alpaca: Code and documentation to train Stanford's Alpaca models, and generate the data.):
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Input:
{input}
### Response:鉴于模型是使用这样的模板进行指令调整的,因此当用户使用相同格式提示时,模型有望达到最佳性能。
2.描述输出格式以实现可解析性:在向模型提供提示后,您需要从模型的输出中提取所需的内容。理想情况下,这些输出应采用一种您可以通过编程方法轻松解析的格式。根据任务(例如文本分类),这可能涉及利用正则表达式 (regex) 来筛选 LLM 的输出。相比之下,对于需要更细粒度数据的任务(例如命名实体识别 (NER)),您可能更喜欢使用 JSON 之类的格式作为输出。
然而,你使用 LLM 越多,你就越快意识到获得可解析的输出可能具有挑战性。LLM 通常难以以用户要求的格式提供精确的输出。虽然诸如少样本提示之类的策略可以显著缓解这个问题,但要从 LLM 获得一致、可程序解析的输出需要仔细的实验和调整。
3.提示以获得最佳表现: LLM 对任务的描述方式非常敏感。如果提示不够精心设计或留下太多解释空间,则会导致表现不佳。想象一下向某人解释一项任务——您的解释越清晰、越详细,对方的理解就越好。然而,没有神奇的公式可以得出理想的提示。这需要仔细试验和评估不同的提示,以选择表现最佳的提示。
探索不同的提示策略
希望您现在已经确信自己需要认真对待提示。如果提示是一个工具包,那么我们可以利用哪些工具呢?
零样本提示:零样本提示 [2] [3] 涉及指示 LLM 执行提示中仅描述的任务,而不提供示例。术语“零样本”表示模型必须完全依赖提示中的任务描述,因为它没有收到与任务相关的具体演示。
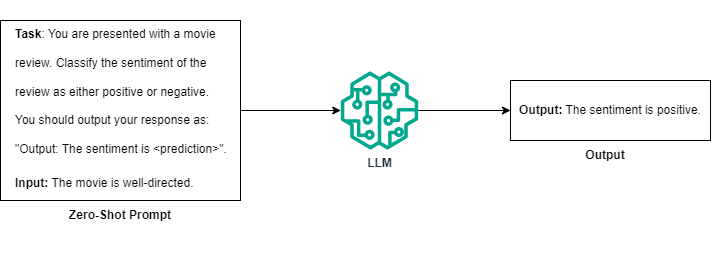
零次提示概述。(图片由作者提供)
在许多情况下,零样本提示足以指导 LLM 执行您想要的任务。但是,如果您的任务过于模糊、开放式或含糊,零样本提示可能会有局限性。假设您希望 LLM 按 1 到 5 的等级对答案进行排名。虽然模型可以使用零样本提示执行此任务,但这里可能会出现两个问题:
- LLM 可能对评分标准上每个数字的含义没有客观的理解。如果任务描述缺乏细微差别,它可能很难决定何时为答案分配 3 分或 4 分。
- LLM 可能有自己的 1 到 5 分制评分概念,这可能与您的个人评分标准相矛盾。在评分时,您可能优先考虑答案的真实性,但模型可能会根据答案的写作水平来评估答案。
为了让模型符合您的评分期望,您可以提供一些答案示例以及评分方法。现在,模型有了更多关于如何评分文档的背景和参考,从而缩小了任务中的歧义。这让我们想到了少样本提示。
少量提示:少量提示通过少量示例输入及其对应的输出丰富了任务描述 [3]。该技术通过包含几个示例对来说明任务,从而增强了模型的理解。
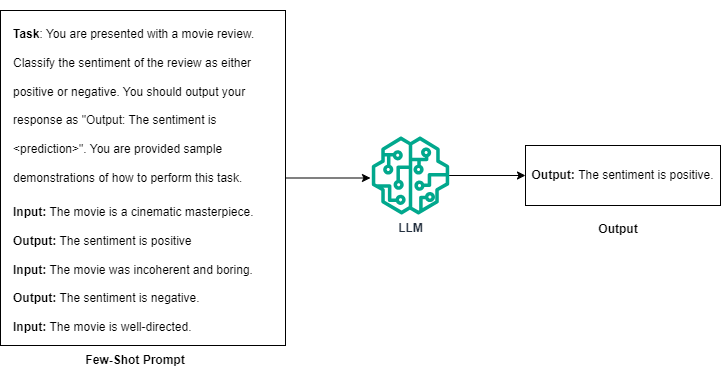
少量提示法概述。(图片由作者提供)
例如,为了指导法学硕士对电影评论进行情绪分类,您需要提供一些评论及其情绪评级。与零样本提示相比,少样本提示的主要好处是能够展示如何执行任务的示例,而不是期望法学硕士仅凭描述就能完成任务。
思路链:思路链 (CoT) 提示 [6] 是一种技术,它使 LLM 能够通过将复杂问题分解为更简单的中间步骤来解决这些问题。这种方法鼓励模型“大声思考”,使其推理过程透明化,并允许 LLM 更有效地解决推理问题。正如该作品的作者所提到的 [6],CoT 模仿了人类解决推理问题的方式,将问题分解为更简单的步骤并一次解决一个步骤,而不是直接跳到答案。
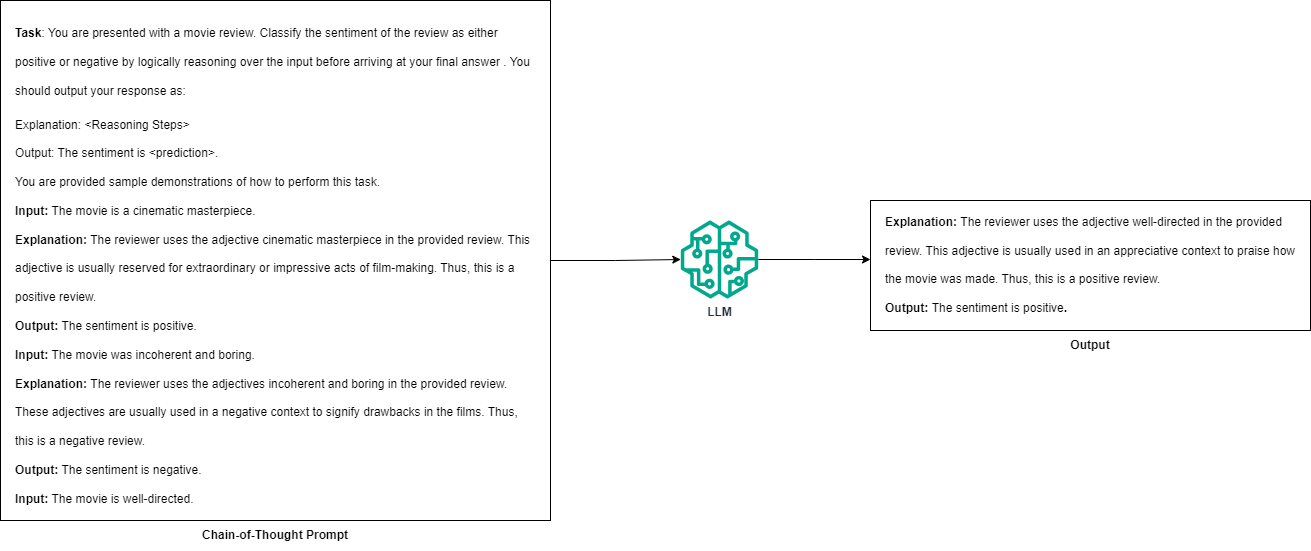
思路链提示概述。(图片由作者提供)
CoT 提示通常以少样本提示的形式实现,其中模型接收任务描述和输入输出对的示例。这些示例包括系统地得出正确答案的推理步骤,演示如何处理信息。因此,为了有效地执行 CoT 提示,用户需要高质量的演示示例。然而,这对于需要专业知识的任务来说可能具有挑战性。例如,使用 LLM 根据患者病史进行医学诊断需要领域专家(如医生或医师)的协助,以阐明正确的推理步骤。此外,CoT 在参数规模足够大的模型中特别有效。根据论文 [6],CoT 对 137B 参数 LaMBDA [7]、175B 参数 GPT-3 [3] 和 540B 参数 PaLM [8] 模型最有效。这一限制可能会限制其对小规模模型的适用性。
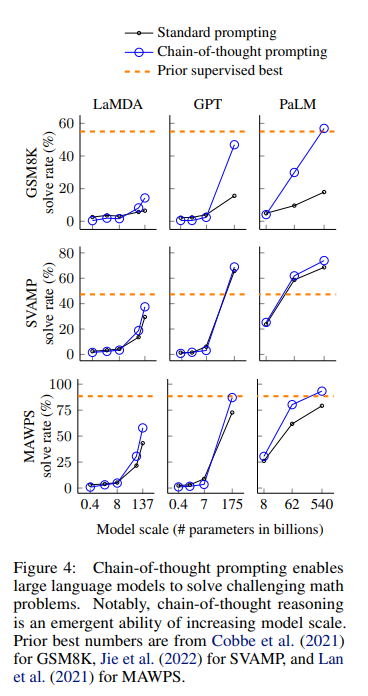
摘自[6](来源)的图表显示,CoT 提示提供的性能改进随着模型规模的扩大而大幅提升。
CoT 提示与标准提示的另一个不同之处在于,模型需要生成更多标记才能得出最终答案。虽然这不一定是缺点,但如果您在推理时受到计算限制,这是一个需要考虑的因素。
如果您想要更深入的了解,我推荐 OpenAI 的提示资源,网址为https://platform.openai.com/docs/guides/prompt-engineering/strategy-write-clear-instructions。
我们如何实现这些技术?
与本文相关的所有代码和资源均可在此 Github 存储库中找到,位于 presentation_to_prompting 文件夹下。请随意拉取存储库并直接运行笔记本以进行这些实验。如果您有任何反馈或意见,或者发现任何错误,请告诉我!
我们可以在样本数据集上探索这些技术,以便于理解。为此,我们将使用 MedQA 数据集 [9],其中包含测试医学和临床知识的问题。我们将专门利用该数据集中的 USMLE 问题。此任务非常适合分析各种提示技术,因为回答问题需要知识和推理。我们将在此数据集上测试 Llama-2 7B [10] 和 GPT-3.5 [11] 的功能。
我们首先下载数据集。MedQA 数据集可以从此链接下载。下载数据集后,我们可以解析并开始处理问题。测试集总共包含 1,273 个问题。我们从测试集中随机抽取 300 个问题来评估模型,并从训练集中选择 3 个随机示例作为模型的少样本演示。
import json
import random
random.seed(42)
def read_jsonl_file(file_path):
"""
Parses a JSONL (JSON Lines) file and returns a list of dictionaries.
Args:
file_path (str): The path to the JSONL file to be read.
Returns:
list of dict: A list where each element is a dictionary representing
a JSON object from the file.
"""
jsonl_lines = []
with open(file_path, 'r', encoding="utf-8") as file:
for line in file:
json_object = json.loads(line)
jsonl_lines.append(json_object)
return jsonl_lines
def write_jsonl_file(dict_list, file_path):
"""
Write a list of dictionaries to a JSON Lines file.
Args:
- dict_list (list): A list of dictionaries to write to the file.
- file_path (str): The path to the file where the data will be written.
"""
with open(file_path, 'w') as file:
for dictionary in dict_list:
# Convert the dictionary to a JSON string and write it to the file.
json_line = json.dumps(dictionary)
file.write(json_line + '\n')
# read the contents of the train and test set
train_set = read_jsonl_file("data_clean/questions/US/4_options/phrases_no_exclude_train.jsonl")
test_set = read_jsonl_file("data_clean/questions/US/4_options/phrases_no_exclude_test.jsonl")
# subsample test set samples and few-shot samples
test_set_subsampled = random.sample(test_set, 300)
few_shot_examples = random.sample(test_set, 3)
# dump the sampled questions and few-shot samples as jsonl files
write_jsonl_file(test_set_subsampled, "USMLE_test_samples_300.jsonl")
write_jsonl_file(few_shot_examples, "USMLE_few_shot_samples.jsonl")使用零次提示提示骆驼 2 7B-聊天
Llama 系列模型由 Meta 发布。它们是仅用于解码器的 LLM 系列,参数数量从 7B 到 70B。Llama-2 系列模型有两种变体:基本版本和聊天/指令调整版本。在本练习中,我们将使用聊天版本的 Llama 2-7B 模型。
让我们看看我们能让 Llama 模型回答这些医学问题的效果如何。我们将模型加载到内存中:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from tqdm import tqdm
questions = read_jsonl_file("USMLE_test_samples_300.jsonl")
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf", torch_dtype=torch.bfloat16).cuda()
model.eval()如果您使用的是 Nvidia Ampere GPU,则可以使用 torch.bfloat16 加载模型。它可以加快推理速度,并且比普通的 FP16/FP32 占用更少的 GPU 内存。
首先,让我们为我们的任务制定一个基本提示:
PROMPT = """You will be provided with a medical or clinical question, along with multiple possible answer choices. Pick the right answer from the choices.
Your response should be in the format "The answer is <correct_choice>". Do not add any other unnecessary content in your response"""我们的提示很简单。它包含有关任务性质的信息,并提供有关输出格式的说明。我们将看看这个提示在实践中有多有效。
Llama-2 聊天模型有一个特定的聊天模板可供遵循以提示它们。
<s>[INST] <<SYS>>
You will be provided with a medical or clinical question, along with multiple possible answer choices. Pick the right answer from the choices.
Your response should be in the format "The answer is <correct_choice>". Do not add any other unnecessary content in your response
<</SYS>>
A 21-year-old male presents to his primary care provider for fatigue. He reports that he graduated from college last month and returned 3 days ago from a 2 week vacation to Vietnam and Cambodia. For the past 2 days, he has developed a worsening headache, malaise, and pain in his hands and wrists. The patient has a past medical history of asthma managed with albuterol as needed. He is sexually active with both men and women, and he uses condoms “most of the time.” On physical exam, the patient’s temperature is 102.5°F (39.2°C), blood pressure is 112/66 mmHg, pulse is 105/min, respirations are 12/min, and oxygen saturation is 98% on room air. He has tenderness to palpation over his bilateral metacarpophalangeal joints and a maculopapular rash on his trunk and upper thighs. Tourniquet test is negative. Laboratory results are as follows:
Hemoglobin: 14 g/dL
Hematocrit: 44%
Leukocyte count: 3,200/mm^3
Platelet count: 112,000/mm^3
Serum:
Na+: 142 mEq/L
Cl-: 104 mEq/L
K+: 4.6 mEq/L
HCO3-: 24 mEq/L
BUN: 18 mg/dL
Glucose: 87 mg/dL
Creatinine: 0.9 mg/dL
AST: 106 U/L
ALT: 112 U/L
Bilirubin (total): 0.8 mg/dL
Bilirubin (conjugated): 0.3 mg/dL
Which of the following is the most likely diagnosis in this patient?
Options:
A. Chikungunya
B. Dengue fever
C. Epstein-Barr virus
D. Hepatitis A [/INST]任务描述应在 <<SYS>> 标记之间提供,后面跟着模型需要回答的实际问题。提示以 [/INST] 标记结束,以表示输入文本的结束。
角色可以是“用户”、“系统”或“助手”之一。“系统”角色为模型提供任务描述,“用户”角色包含模型需要响应的输入。这是我们稍后与 GPT-3.5 交互时将使用的相同约定。这相当于创建一个提供给 Llama-2 的虚构多轮对话历史记录,其中每个轮次对应于一个示例演示和一个来自模型的理想输出。
听起来很复杂?幸运的是,Huggingface Transformers 库支持将提示转换为聊天模板。我们将利用此功能让我们的生活更轻松。让我们从辅助功能开始处理数据集并创建提示。
def create_query(item):
"""
Creates the input for the model using the question and the multiple choice options.
Args:
item (dict): A dictionary containing the question and options.
Expected keys are "question" and "options", where "options" is another
dictionary with keys "A", "B", "C", and "D".
Returns:
str: A formatted query combining the question and options, ready for use.
"""
query = item["question"] + "\nOptions:\n" + \
"A. " + item["options"]["A"] + "\n" + \
"B. " + item["options"]["B"] + "\n" + \
"C. " + item["options"]["C"] + "\n" + \
"D. " + item["options"]["D"]
return query
def build_zero_shot_prompt(system_prompt, question):
"""
Builds the zero-shot prompt.
Args:
system_prompt (str): Task Instruction
content (dict): The content for which to create a query, formatted as
required by `create_query`.
Returns:
list of dict: A list of messages, including a system message defining
the task and a user message with the input question.
"""
messages = [{"role": "system", "content": system_prompt},
{"role": "user", "content": create_query(question)}]
return messages此函数构造查询以提供给 LLM。MedQA 数据集将每个问题存储为 JSON 元素,并以问题和选项作为键。我们解析 JSON 并构造问题以及选项。
让我们开始从模型中获取输出。当前任务涉及通过从各种选项中选择正确答案来回答提供的医学问题。与内容写作或总结等创造性任务不同,这些任务可能需要模型在输出中富有想象力和创造力,这是一项基于知识的任务,旨在测试模型根据其参数中编码的知识回答问题的能力。因此,我们将在生成答案时使用贪婪解码。让我们定义一个辅助函数来解析模型响应并计算准确性。
pattern = re.compile(r"([A-Z])\.\s*(.*)")
def parse_answer(response):
"""
Extracts the answer option from the predicted string.
Args:
- response (str): The string to search for the pattern.
Returns:
- str: The matched answer option if found or an empty string otherwise.
"""
match = re.search(pattern, response)
if match:
letter = match.group(1)
else:
letter = ""
return letter
def calculate_accuracy(ground_truth, predictions):
"""
Calculates the accuracy of predictions compared to ground truth labels.
Args:
- ground_truth (list): A list of true labels.
- predictions (list): A list of predicted labels.
Returns:
- float: The accuracy of predictions as a fraction of correct predictions over total predictions.
"""
return sum([1 if x==y else 0 for x,y in zip(ground_truth, predictions)]) / len(ground_truth)ground_truth = []
for item in questions:
ans_options = item["options"]
correct_ans_option = ""
for key,value in ans_options.items():
if value == item["answer"]:
correct_ans_option = key
break
ground_truth.append(correct_ans_option)zero_shot_llama_answers = []
for item in tqdm(questions):
zero_shot_prompt_messages = build_zero_shot_prompt(PROMPT, item)
input_ids = tokenizer.apply_chat_template(zero_shot_prompt_messages, tokenize=True, return_tensors="pt").cuda() #modified on 09/03/2024
# prompt = tokenizer.apply_chat_template(zero_shot_prompt_messages, tokenize=False)
# input_ids = tokenizer(prompt, return_tensors="pt", truncation=True).input_ids.cuda()
outputs = model.generate(input_ids=input_ids, max_new_tokens=10, do_sample=False)
# https://github.com/huggingface/transformers/issues/17117#issuecomment-1124497554
gen_text = tokenizer.batch_decode(outputs.detach().cpu().numpy()[:, input_ids.shape[1]:], skip_special_tokens=True)[0]
zero_shot_llama_answers.append(gen_text.strip())
zero_shot_llama_predictions = [parse_answer(x) for x in zero_shot_llama_answers]
print(calculate_accuracy(ground_truth, zero_shot_llama_predictions))在零样本设置下,我们的性能为 3̶6̶%̶ 35%。这是一个很好的开始,但让我们看看我们能否进一步提高这一性能。
2024 年 9 月 3 日编辑— 我注意到提示的格式和标记方式中有一个小“错误”。具体来说,我使用了 tokenizer.apply_chat_template(zero_shot_prompt_messages, tokenize = False),然后调用 tokenizer 以更早地获取 input_ids。此方法在提示的开头添加了一个额外的 <s> 标记。apply_chat_template 已经将 <s> 标记添加到序列中,但在创建聊天模板后调用 tokenizer 会在开头再次添加特殊标记 <s>。我通过在 apply_chat_template 中更改 tokenize=True 来修复此问题。我得到的新分数是 35%,与旧设置的 36% 相比略有下降。修复这个“错误”导致分数略有下降,这有点好笑,但我在这里和代码中进行了更正,以避免在使用聊天模板时产生任何混淆。本文中的任何发现或要点均不会受到此修复的影响。
提示骆驼 2 7B-Chat 并发出少量提示
现在让我们为模型提供任务演示。我们使用从训练集中随机抽取的三个问题,并将它们作为任务演示附加到模型中。幸运的是,我们可以继续使用 Transformers 库和标记器提供的聊天模板支持,以最少的代码更改附加我们的小样本示例。
def build_few_shot_prompt(system_prompt, content, few_shot_examples):
"""
Builds the few-shot prompt using provided examples.
Args:
system_prompt (str): Task description for the LLM
content (dict): The content for which to create a query, similar to the
structure required by `create_query`.
few_shot_examples (list of dict): Examples to simulate a hypothetical
conversation. Each dict must have "options" and an "answer".
Returns:
list of dict: A list of messages, simulating a conversation with
few-shot examples, followed by the current user query.
"""
messages = [{"role": "system", "content": system_prompt}]
for item in few_shot_examples:
ans_options = item["options"]
correct_ans_option = ""
for key, value in ans_options.items():
if value == item["answer"]:
correct_ans_option = key
break
messages.append({"role": "user", "content": create_query(item)})
messages.append({"role": "assistant", "content": "The answer is " + correct_ans_option + "."})
messages.append({"role": "user", "content": create_query(content)})
return messages
few_shot_prompts = read_jsonl_file("USMLE_few_shot_samples.jsonl")让我们想象一下我们的小样本提示是什么样的。
<s>[INST] <<SYS>>
You will be provided with a medical or clinical question, along with multiple possible answer choices. Pick the right answer from the choices.
Your response should be in the format "The answer is <correct_choice>". Do not add any other unnecessary content in your response
<</SYS>>
A 30-year-old woman presents to the clinic because of fever, joint pain, and a rash on her lower extremities. She admits to intravenous drug use. Physical examination reveals palpable petechiae and purpura on her lower extremities. Laboratory results reveal a negative antinuclear antibody, positive rheumatoid factor, and positive serum cryoglobulins. Which of the following underlying conditions in this patient is responsible for these findings?
Options:
A. Hepatitis B infection
B. Hepatitis C infection
C. HIV infection
D. Systemic lupus erythematosus (SLE) [/INST] The answer is B. </s><s>[INST] A 10-year-old child presents to your office with a chronic cough. His mother states that he has had a cough for the past two weeks that is non-productive along with low fevers of 100.5 F as measured by an oral thermometer. The mother denies any other medical history and states that he has been around one other friend who also has had this cough for many weeks. The patient's vitals are within normal limits with the exception of his temperature of 100.7 F. His chest radiograph demonstrated diffuse interstitial infiltrates. Which organism is most likely causing his pneumonia?
Options:
A. Mycoplasma pneumoniae
B. Staphylococcus aureus
C. Streptococcus pneumoniae
D. Streptococcus agalactiae [/INST] The answer is A. </s><s>[INST] A 44-year-old with a past medical history significant for human immunodeficiency virus infection presents to the emergency department after he was found to be experiencing worsening confusion. The patient was noted to be disoriented by residents and staff at the homeless shelter where he resides. On presentation he reports headache and muscle aches but is unable to provide more information. His temperature is 102.2°F (39°C), blood pressure is 112/71 mmHg, pulse is 115/min, and respirations are 24/min. Knee extension with hips flexed produces significant resistance and pain. A lumbar puncture is performed with the following results:
Opening pressure: Normal
Fluid color: Clear
Cell count: Increased lymphocytes
Protein: Slightly elevated
Which of the following is the most likely cause of this patient's symptoms?
Options:
A. Cryptococcus
B. Group B streptococcus
C. Herpes simplex virus
D. Neisseria meningitidis [/INST] The answer is C. </s><s>[INST] A 21-year-old male presents to his primary care provider for fatigue. He reports that he graduated from college last month and returned 3 days ago from a 2 week vacation to Vietnam and Cambodia. For the past 2 days, he has developed a worsening headache, malaise, and pain in his hands and wrists. The patient has a past medical history of asthma managed with albuterol as needed. He is sexually active with both men and women, and he uses condoms “most of the time.” On physical exam, the patient’s temperature is 102.5°F (39.2°C), blood pressure is 112/66 mmHg, pulse is 105/min, respirations are 12/min, and oxygen saturation is 98% on room air. He has tenderness to palpation over his bilateral metacarpophalangeal joints and a maculopapular rash on his trunk and upper thighs. Tourniquet test is negative. Laboratory results are as follows:
Hemoglobin: 14 g/dL
Hematocrit: 44%
Leukocyte count: 3,200/mm^3
Platelet count: 112,000/mm^3
Serum:
Na+: 142 mEq/L
Cl-: 104 mEq/L
K+: 4.6 mEq/L
HCO3-: 24 mEq/L
BUN: 18 mg/dL
Glucose: 87 mg/dL
Creatinine: 0.9 mg/dL
AST: 106 U/L
ALT: 112 U/L
Bilirubin (total): 0.8 mg/dL
Bilirubin (conjugated): 0.3 mg/dL
Which of the following is the most likely diagnosis in this patient?
Options:
A. Chikungunya
B. Dengue fever
C. Epstein-Barr virus
D. Hepatitis A [/INST]由于我们附加了三个演示,因此提示相当长。现在让我们使用少样本提示运行 Llama-2 并获取结果:
few_shot_llama_answers = []
for item in tqdm(questions):
few_shot_prompt_messages = build_few_shot_prompt(PROMPT, item, few_shot_prompts)
input_ids = tokenizer.apply_chat_template(few_shot_prompt_messages, tokenize=True, return_tensors="pt").cuda() #modified on 09/03/2024
# prompt = tokenizer.apply_chat_template(few_shot_prompt_messages, tokenize=False)
# input_ids = tokenizer(prompt, return_tensors="pt", truncation=True).input_ids.cuda()
outputs = model.generate(input_ids=input_ids, max_new_tokens=10, do_sample=False)
gen_text = tokenizer.batch_decode(outputs.detach().cpu().numpy()[:, input_ids.shape[1]:], skip_special_tokens=True)[0]
few_shot_llama_answers.append(gen_text.strip())
few_shot_llama_predictions = [parse_answer(x) for x in few_shot_llama_answers]
print(calculate_accuracy(ground_truth, few_shot_llama_predictions))我们现在的总体准确率达到了 41.67% 40.33%。还不错,与使用相同模型的零样本提示相比,准确率提高了近 6% 5%!
2024 年 9 月 3 日编辑— 与零样本设置类似,我修复了在少样本设置中向模型发送提示的方式。我得到的新分数是 40.33%,与旧设置的 41.67% 相比,略有下降约 1.3%。修复这个“错误”导致分数略有下降,这又有点好笑,但我在这里和代码中进行了更正,以避免在使用聊天模板时产生任何混淆。本文中的任何发现或结论都不会受到此修复的影响。
如果我们不遵守聊天模板会发生什么?
之前,我观察到,建议根据最初用于微调 LLM 的提示模板来构造我们的提示。让我们验证一下不遵守聊天模板是否会损害我们的性能。我们创建一个函数,使用相同的示例构建一个少样本提示,而不遵守聊天格式。
def build_few_shot_prompt_wo_chat_template(system_prompt, content, few_shot_examples):
"""
Builds the few-shot prompt using provided examples, bypassing the chat-template
for Llama-2.
Args:
system_prompt (str): Task description for the LLM
content (dict): The content for which to create a query, similar to the
structure required by `create_query`.
few_shot_examples (list of dict): Examples to simulate a hypothetical
conversation. Each dict must have "options" and an "answer".
Returns:
str: few-shot prompt in non-chat format
"""
few_shot_prompt = ""
few_shot_prompt += "Task: " + system_prompt + "\n"
for item in few_shot_examples:
ans_options = item["options"]
correct_ans_option = ""
for key, value in ans_options.items():
if value == item["answer"]:
correct_ans_option = key
break
few_shot_prompt += create_query(item) + "\n" + "The answer is " + correct_ans_option + "." + "\n"
few_shot_prompt += create_query(content) + "\n"
return few_shot_prompt我们的提示现在如下所示:
Task: You will be provided with a medical or clinical question, along with multiple possible answer choices. Pick the right answer from the choices.
Your response should be in the format "The answer is <correct_choice>". Do not add any other unnecessary content in your response
A 30-year-old woman presents to the clinic because of fever, joint pain, and a rash on her lower extremities. She admits to intravenous drug use. Physical examination reveals palpable petechiae and purpura on her lower extremities. Laboratory results reveal a negative antinuclear antibody, positive rheumatoid factor, and positive serum cryoglobulins. Which of the following underlying conditions in this patient is responsible for these findings?
Options:
A. Hepatitis B infection
B. Hepatitis C infection
C. HIV infection
D. Systemic lupus erythematosus (SLE)
The answer is B.
A 10-year-old child presents to your office with a chronic cough. His mother states that he has had a cough for the past two weeks that is non-productive along with low fevers of 100.5 F as measured by an oral thermometer. The mother denies any other medical history and states that he has been around one other friend who also has had this cough for many weeks. The patient's vitals are within normal limits with the exception of his temperature of 100.7 F. His chest radiograph demonstrated diffuse interstitial infiltrates. Which organism is most likely causing his pneumonia?
Options:
A. Mycoplasma pneumoniae
B. Staphylococcus aureus
C. Streptococcus pneumoniae
D. Streptococcus agalactiae
The answer is A.
A 44-year-old with a past medical history significant for human immunodeficiency virus infection presents to the emergency department after he was found to be experiencing worsening confusion. The patient was noted to be disoriented by residents and staff at the homeless shelter where he resides. On presentation he reports headache and muscle aches but is unable to provide more information. His temperature is 102.2°F (39°C), blood pressure is 112/71 mmHg, pulse is 115/min, and respirations are 24/min. Knee extension with hips flexed produces significant resistance and pain. A lumbar puncture is performed with the following results:
Opening pressure: Normal
Fluid color: Clear
Cell count: Increased lymphocytes
Protein: Slightly elevated
Which of the following is the most likely cause of this patient's symptoms?
Options:
A. Cryptococcus
B. Group B streptococcus
C. Herpes simplex virus
D. Neisseria meningitidis
The answer is C.
A 21-year-old male presents to his primary care provider for fatigue. He reports that he graduated from college last month and returned 3 days ago from a 2 week vacation to Vietnam and Cambodia. For the past 2 days, he has developed a worsening headache, malaise, and pain in his hands and wrists. The patient has a past medical history of asthma managed with albuterol as needed. He is sexually active with both men and women, and he uses condoms “most of the time.” On physical exam, the patient’s temperature is 102.5°F (39.2°C), blood pressure is 112/66 mmHg, pulse is 105/min, respirations are 12/min, and oxygen saturation is 98% on room air. He has tenderness to palpation over his bilateral metacarpophalangeal joints and a maculopapular rash on his trunk and upper thighs. Tourniquet test is negative. Laboratory results are as follows:
Hemoglobin: 14 g/dL
Hematocrit: 44%
Leukocyte count: 3,200/mm^3
Platelet count: 112,000/mm^3
Serum:
Na+: 142 mEq/L
Cl-: 104 mEq/L
K+: 4.6 mEq/L
HCO3-: 24 mEq/L
BUN: 18 mg/dL
Glucose: 87 mg/dL
Creatinine: 0.9 mg/dL
AST: 106 U/L
ALT: 112 U/L
Bilirubin (total): 0.8 mg/dL
Bilirubin (conjugated): 0.3 mg/dL
Which of the following is the most likely diagnosis in this patient?
Options:
A. Chikungunya
B. Dengue fever
C. Epstein-Barr virus
D. Hepatitis A现在让我们使用这些提示来评估 Llama 2 并观察它的表现:
few_shot_llama_answers_wo_chat_template = []
for item in tqdm(questions):
prompt = build_few_shot_prompt_wo_chat_template(PROMPT, item, few_shot_prompts)
input_ids = tokenizer(prompt, return_tensors="pt", truncation=True).input_ids.cuda()
outputs = model.generate(input_ids=input_ids, max_new_tokens=10, do_sample=False)
gen_text = tokenizer.batch_decode(outputs.detach().cpu().numpy()[:, input_ids.shape[1]:], skip_special_tokens=True)[0]
few_shot_llama_answers_wo_chat_template.append(gen_text.strip())
few_shot_llama_predictions_wo_chat_template = [parse_answer(x) for x in few_shot_llama_answers_wo_chat_template]
print(calculate_accuracy(ground_truth, few_shot_llama_predictions_wo_chat_template))我们的准确率达到了 36%。这比我们之前的几次得分低 6̶%̶ 4.3%。这强化了我们之前的论点,即根据用于微调我们打算使用的 LLM 的模板来构建我们的提示至关重要。提示模板很重要!
提示骆驼 2 7B-与 CoT 聊天提示
让我们通过评估 CoT 提示来结束本文。请记住,我们的数据集包括旨在通过 USMLE 考试测试医学知识的问题。这类问题通常需要事实回忆和概念推理才能回答。这使得它成为测试 CoT 效果的完美任务。
首先,我们必须向模型提供一个示例 CoT 提示,以演示如何推理问题。为此,我们将使用 Google MedPALM 论文 [12] 中的一个提示。

用于在 MedQA 数据集上评估 MedPALM 模型的五次 CoT 提示。提示借用自 [12] 的第 41 页表 A.18(来源)。
我们使用这个五次提示来评估模型。由于此提示样式与我们之前的提示略有不同,让我们再次创建一些辅助函数来处理它们并获得输出。在使用 CoT 提示时,我们生成具有更大输出标记计数的输出,以使模型在回答问题之前能够“思考”和“推理”。
def create_query_cot(item):
"""
Creates the input for the model using the question and the multiple choice options in the CoT format.
Args:
item (dict): A dictionary containing the question and options.
Expected keys are "question" and "options", where "options" is another
dictionary with keys "A", "B", "C", and "D".
Returns:
str: A formatted query combining the question and options, ready for use.
"""
query = "Question: " + item["question"] + "\n" + \
"(A) " + item["options"]["A"] + " " + \
"(B) " + item["options"]["B"] + " " + \
"(C) " + item["options"]["C"] + " " + \
"(D) " + item["options"]["D"]
return query
def build_cot_prompt(instruction, input_question, cot_examples):
"""
Builds the few-shot prompt for the GPT API using provided examples.
Args:
content (dict): The content for which to create a query, similar to the
structure required by `create_query`.
few_shot_examples (list of dict): Examples to simulate a hypothetical
conversation. Each dict must have "question" and an "explanation".
Returns:
list of dict: A list of messages, simulating a conversation with
few-shot examples, followed by the current user query.
"""
messages = [{"role": "system", "content": instruction}]
for item in cot_examples:
messages.append({"role": "user", "content": item["question"]})
messages.append({"role": "assistant", "content": item["explanation"]})
messages.append({"role": "user", "content": create_query_cot(input_question)})
return messages
def parse_answer_cot(text):
"""
Extracts the choice from a string that follows the pattern "Answer: (Choice) Text".
Args:
- text (str): The input string from which to extract the choice.
Returns:
- str: The extracted choice or a message indicating no match was found.
"""
# Regex pattern to match the answer part
pattern = r"Answer: (.*)"
# Search for the pattern in the text and extract the matching group
match = re.search(pattern, text)
if match:
if len(match.group(1)) > 1:
return match.group(1)[1]
else:
return ""
else:
return ""cot_llama_answers = []
for item in tqdm(questions):
cot_prompt = build_cot_prompt(COT_INSTRUCTION, item, COT_EXAMPLES)
input_ids = tokenizer.apply_chat_template(cot_prompt, tokenize=True, return_tensors="pt").cuda() #modified on 09/03/2024
# prompt = tokenizer.apply_chat_template(cot_prompt, tokenize=False)
# input_ids = tokenizer(prompt, return_tensors="pt", truncation=True).input_ids.cuda()
outputs = model.generate(input_ids=input_ids, max_new_tokens=100, do_sample=False)
gen_text = tokenizer.batch_decode(outputs.detach().cpu().numpy()[:, input_ids.shape[1]:], skip_special_tokens=True)[0]
cot_llama_answers.append(gen_text.strip())
cot_llama_predictions = [parse_answer_cot(x) for x in cot_llama_answers]
print(calculate_accuracy(ground_truth, cot_llama_predictions))使用 CoT 提示对 Llama 2–7B 进行测试时,我们的性能下降到了 2̶0̶%̶ 21.33%。这与 CoT 论文 [6] 的发现基本一致,其中作者提到 CoT 是 LLM 的一个新兴特性,会随着模型规模的扩大而提高。话虽如此,让我们分析一下性能大幅下降的原因。
2024 年 9 月 3 日编辑— 与零样本设置类似,我修复了 CoT 设置中向模型发送提示的方式。我得到的新分数是 21.33%,与旧设置的 20% 分数相比,小幅增加了约 1.33%。我在这里和代码中进行了更正,以避免对使用聊天模板产生任何混淆。本文中的任何发现或结论都不会受到此修复的影响。
Llama 2 的 CoT 故障模式
我们从 Llama 2 提供的某些测试集问题的答案中抽取了一些样本,以分析错误情况:
这些 CoT 样本和图表的分析不受修复小“错误”的影响。我已经验证了这些图表中使用的预测在旧设置和新设置中是相同的。

示例预测 1 — 模型得出答案,但不符合格式,导致结果解析困难。(图片来自作者)

示例预测 2 — 模型未能遵循提示格式并得出结论性答案。(图片来自作者)
虽然 CoT 提示允许模型在得出最终答案之前进行“思考”,但在大多数情况下,模型要么无法得出最终答案,要么以与我们的示例演示不一致的格式提及答案。我在这里没有分析过但可能值得探索的一种失败模式是检查测试集中模型“推理”错误并因此得出错误答案的案例。这超出了本文和我的医学知识的范围,但我肯定打算以后再讨论。
使用零样本提示来提示 GPT-3.5
让我们开始定义一些辅助函数,帮助我们处理这些输入以利用 GPT API。您需要生成一个 API 密钥才能使用 GPT-3.5 API。您可以在 Windows 中使用以下命令设置 API 密钥:
setx OPENAI_API_KEY "your-api-key-here"
或者在 Linux 中使用:
export OPENAI_API_KEY "your-api-key-here"
在您正在使用的当前会话中。
from openai import OpenAI
import re
from tqdm import tqdm
# assuming you have already set the secret key using env variable
# if not, you can also instantiate the OpenAI client by providing the
# secret key directly like so:
# I highly recommend not doing this, as it is a best practice to not store
# the api key in your code directly or in any plain-text file for security
# reasons.
# client = OpenAI(api_key = "")
client = OpenAI() def get_response(messages, model_name, temperature = 0.0, max_tokens = 10):
"""
Obtains the responses/answers of the model through the chat-completions API.
Args:
messages (list of dict): The built messages provided to the API.
model_name (str): Name of the model to access through the API
temperature (float): A value between 0 and 1 that controls the randomness of the output.
A temperature value of 0 ideally makes the model pick the most likely token, making the outputs (mostly) deterministic.
max_tokens (int): Maximum number of tokens that the model should generate
Returns:
str: The response message content from the model.
"""
response = client.chat.completions.create(
model=model_name,
messages=messages,
temperature=temperature,
max_tokens=max_tokens
)
return response.choices[0].message.content此函数现在以 GPT-3.5 API 的格式构建提示。我们可以通过库提供的 chat-completions API 与 GPT-3.5 模型进行交互。API 要求将消息构造为字典列表,以便发送到 API。每条消息都必须指定角色和内容。关于“系统”、 “用户”和“助手”角色遵循的约定与前面针对 Llama-7B 聊天模型描述的约定相同。
现在我们使用 GPT-3.5 API 来处理测试集并获取响应。收到所有响应后,我们从模型的响应中提取选项并计算准确率。
zero_shot_gpt_answers = []
for item in tqdm(questions):
zero_shot_prompt_messages = build_zero_shot_prompt(PROMPT, item)
answer = get_response(zero_shot_prompt_messages, model_name = "gpt-3.5-turbo", temperature = 0.0, max_tokens = 10)
zero_shot_gpt_answers.append(answer)
zero_shot_gpt_predictions = [parse_answer(x) for x in zero_shot_gpt_answers]
print(calculate_accuracy(ground_truth, zero_shot_gpt_predictions))我们的性能现在为 63%。这比 Llama 2–7B 的性能有了显著的提高。这并不奇怪,因为 GPT-3.5 可能比 Llama 2–7B 更大,并且使用更多的数据进行训练,同时 OpenAI 可能已将其他专有优化纳入模型中。让我们看看少样本提示现在的效果如何。
使用 Few-Shot Prompt 来提示 GPT-3.5
为了向 LLM 提供少样本示例,我们重用了从训练集中抽取的三个示例,并将它们附加到提示中。对于 GPT-3.5,我们创建了一个带有示例的消息列表,类似于我们之前对 Llama 2 的处理。使用“用户”角色附加输入,并在“助手”角色中显示相应的选项。我们重用了之前的函数来构建少样本提示。
这又相当于为 GPT-3.5 创建一个虚构的多轮对话历史,其中每一轮都对应一个示例演示。
现在让我们使用 GPT-3.5 获取输出。
few_shot_gpt_answers = []
for item in tqdm(questions):
few_shot_prompt_messages = build_few_shot_prompt(PROMPT, item, few_shot_prompts)
answer = get_response(few_shot_prompt_messages, model_name= "gpt-3.5-turbo", temperature = 0.0, max_tokens = 10)
few_shot_gpt_answers.append(answer)
few_shot_gpt_predictions = [parse_answer(x) for x in few_shot_gpt_answers]
print(calculate_accuracy(ground_truth, few_shot_gpt_predictions))我们成功地通过少量提示将性能从 63% 提高到了 67%!这是一个显著的进步,凸显了为模型提供任务演示的价值。
使用 CoT Prompt 来提示 GPT-3.5
现在让我们使用 CoT 提示来评估 GPT-3.5。我们重新使用相同的 CoT 提示并得到输出:
cot_gpt_answers = []
for item in tqdm(questions):
cot_prompt = build_cot_prompt(COT_INSTRUCTION, item, COT_EXAMPLES)
answer = get_response(cot_prompt, model_name= "gpt-3.5-turbo", temperature = 0.0, max_tokens = 100)
cot_gpt_answers.append(answer)
cot_gpt_predictions = [parse_answer_cot(x) for x in cot_gpt_answers]
print(calculate_accuracy(ground_truth, cot_gpt_predictions))使用 GPT-3.5 的 CoT 提示可实现 71% 的准确率!这比少样本提示又提高了 4%。看来,让模型在回答问题之前大声“思考”对这项任务有益。这也与论文 [6] 的发现一致,即 CoT 为较大参数模型解锁了性能改进。
结论和要点:
提示是使用大型语言模型 (LLM) 的一项关键技能,并且要了解提示工具包中有各种工具,可以根据具体情况帮助您从 LLM 中提取更好的性能。我希望本文可以作为该主题的广泛且(希望!)易于理解的介绍。但是,它的目的不是提供所有提示策略的全面概述。提示仍然是一个非常活跃的研究领域,其中引入了许多方法,例如 ReAct [13]、思维树提示 [14] 等。我建议探索这些技术,以更好地理解它们并增强您的提示工具包。
可重复性
在本文中,我的目标是让所有实验尽可能具有确定性和可重复性。我们使用贪婪解码来获得使用 Llama-2 的零样本、少样本和 CoT 提示的输出。虽然这些分数在技术上应该是可重复的,但在极少数情况下,与 Cuda/GPU 相关或库相关的问题可能会导致结果略有不同。
类似地,在从 GPT-3.5 API 获取响应时,我们使用温度 0 来获取结果,并且只选择下一个最可能的 token,而无需对所有提示设置进行采样。这使得结果“大部分是确定性的”,因此再次向 GPT-3.5 发送相同的提示可能会导致略有不同的结果。
感谢关注云闪世界(亚马逊云aws和谷歌云gcp服务协助)
订阅频道 https://t.me/awsgoogvps_Host
TG交流群(t.me/awsgoogvpsHost)















 7039
7039











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}