






前言
音频或者视频,是今天互联网上被使用得最广泛也最受欢迎的信息媒介,可以肯定这个趋势为未来很长一段时间都不会改变,因此对于开发者而言,深入的了解这块内容是很有必要的。
音视频的技术分割
无论是音频或者视频,他们在互联网上被使用的主要是:创造,存储,播放。而这里面所涉及的技术就是音视频数据的创造和获取,数据的编码和存储,数据的解码和播放,以及音视频本身的协议格式
视音频的协议
音视频的协议非常重要,这是他们能在互联网上广泛传播的基础。
当然其实协议可能是封装协议比如mp4,flac,mp3,mkv,flv等,封装协议指的是将一个音频,一个视频,以及其他信息统一封装成一个文件的规则协议,假设我们下载了一部电影《东京不热》 mp4文件,里面就至少包含了视频,音频这两种数据,MP4可以算作是一种把他们封装的协议。
除了封装协议,最重要的其实是编解码协议,也是音视频的一个重点,它指的是把一帧(音频/视频)数据按照既定的规则进行编码或者解码,从而达到压缩数据便于存储传播的目的。比如我们大家都熟悉的哈夫曼编码,就是一种很典型的压缩数据的编码方法。最常见的有视频类:h264,h265;音频类:aac,ac3,mp3(MP3也可以被作为编码协议的称呼)。
之所以会出现编码协议,是因为视频的原始数据往往过于庞大,大家可以计算一下一个长度为一分钟,帧率为30帧,单帧图像像素格式为RGB8888,1080x1920的视频大概有多大。如果原封不动的保存或者传播。代价是非常昂贵的,因此对视频的内容进行编码,去除冗余数据,可以包存储大小降低至少80%以上,甚至更多。因此,音视频的编码协议对于他们自身是至关重要的。
音视频创建
音视频的创建往往需要依赖摄像头或者麦克风这些设备,因此就涉及到依赖摄像头和麦克风的驱动设备对其进行操作(实际上驱动之上肯定有多层的封装来简化使用的复杂性)。
编码和存储
对于已经获得了音视频的原始数据后,往往需要对他们进行编码,然后保存。目前市面上已有的非常成熟的编码方法h264(视频),aac(音频),是由不同的技术组织提供,并由各种硬件软件厂商提供了支持,因此对于普通开发者而言,我们面对的编码是一个黑盒子,把原始数据输入进编码器,等待输出编码后的数据即可。
对于存储而言,核心内容是把一个视频内容进行封装成不同的封装格式(比如mp4,flv),这里就涉及到了使用复用的功能,media muxer。它指的就是把音视频等不同内容封装成某种格式的能力。
解码和播放
在视频编码保存之后,最终还是会被播放观看的,这里其实涉及到了三个方面的内容,解复用(demuxer),解码(decoder),播放(player)。
因为媒体文件是被封装保存的,因此播放它的第一步,应该是解复用,就是把封装格式(mp4,flv)里的内容提取出来,获得单独的视频,音频以及其他内容。
获得了单独的视频音频之后,无法直接播放,因为他们是被编码过的看起来有些杂乱的数据,而不是一帧帧图像(音频)的集合。因此我们需要把数据送入对应的解码器对它们进行解码,然后才能获得可以播放的一帧帧视频(音频)数据,此时把他们送入播放器才可以正常播放。
而播放器并不是提供播放能力即可,因为对于视频的播放最重要的首先是音视频的同步,就是要保证每一帧画面大概要和某一组音频数据同时播放,这是最基础但是最重要的能力。其次,则是视频进度条的拖动,这个涉及 到视频时间寻址的能力。虽然往往系统会提供一个播放器,里面会具备相应的能力,但是如果需要独立开发也不算太难(要做好还是挺难的)。
小结
以上就是对于音视频的技术领域的简单拆分,这个并不涉及到平台,无论是windows,linux,ios,android大体上都是一样的。系统往往提供了更加丰富的API支持,操作相对更简单,考虑到平台的差异,大家往往也会考虑使用跨平台的框架(ffmpeg)。
Android的音视频框架
参照前面讲的音视频框架,我们可以来讲讲Android平台的对应的音视频框架,以及他们的使用方法。
对于Android视频而言,或许我们应该首先重点熟悉一下Android 的Surface,它是Android系统中的一个重要结构,不仅仅音视频框架的各个流程中随处可见,在我们日常的View的体系中他也是核心内容,讨论Android的显示原理也无法绕开它。
大家可以把surface理解为一个渲染数据的汇集地,surface可以作为camera图像数据输出的出口汇集地,也可以作为编码器的输入输入的入口。
音视频的创建
对于移动设备来讲,创建音视频的方式是使用摄像头和麦克风这两个硬件设备来获取媒体内容,在Android平台而言,就是使用Camera2或者CameraX相关的API即可获取摄像头的图像数据。而要获取音频数据,则一般通过MediaRecoder或者AudioRecod来实现。
视频的创建
对于视频而言,我们说到一般使用Camera2或者CameraX来实现对图像数据的获取。但是这两个模块也有所区别:
- camera2
- 优势 可以实现更精细的配置,更好的自定义。
- 缺陷 接口的操作相对繁琐。
- camerax
- 优势 对camera的相关操作有进一步的封装,可以快速完成对camera的配置使用,已经加入Jetpack中,算是官方推荐优先使用
- 缺陷 较难实现精细配置,对高度自定义需求支持不如前者
由于camerax的对于预览view,camera配置,生命周期管理等的高度封装,因此理论上按照官方教程看30分钟就可以基本掌握
我来简单介绍一下camera2的基本用法,对于camera2,最重要的类有三个:
- CameraManager
- 相机的系统服务管理,可以用来获取一个相机头,以及相机相关的参数
- CameraDevice
- 代表单个摄像头设备
- CameraCaptureSession
- 针对单个摄像头获取连接,对该摄像头采集的数据进行捕获(主要是通过给摄像头设置output surface)
camera2的使用主要围绕着对三个类的对象的获取,而且是依次获取的,得到前一个对象可以获取后一个对象,最终通过CameraCaptureSession来启动预览
首先在布局文件中添加用于预览的View,我们选择SurfaceView.它可以把camera传来的渲染数据直接展示出来。假设我们在主界面中已经完成了SurfaceView配置,正常获取到了SurfaceHolder的情况下,大致需要实现这样的操作:
// 1, 获得CameraManager
private val cameraManager:CameraManager by lazy{
applicationContext.getSystemService(Context.CAMERA_SERVICE) as CameraManager
}
// 2 获取camera
private val cameraThread = HandlerThread("CameraThread").apply { start() }
private val cameraHandler = Handler(cameraThread.looper)
private var theCamera:CameraDevice? = null
// cameraid:摄像头id,通过cameraManager获得所有的摄像头数据(包含一些配置参数)
val cameraId = getCameraIds().get(0)
// 通过openCamera,然后回调获得结果
cameraManager.openCamera(cameraId,object :CameraDevice.StateCallback(){
override fun onOpened(camera: CameraDevice) {
// 正常获取到了CameraDevice
theCamera = camera
}
...
...
},cameraHandler)
// 3,获取cameraSession
// 输出Surface列表(camera 可以输出到多个surface)
var outConfigs = mutableListOf<OutputConfiguration>()
var cameraSession:CameraCaptureSession? = null
// 注意,后面setRequest时输入的surface必须在此处的configuration里的surface范围内
var outConfig = OutputConfiguration(dataBinding.surfaceViewId.holder.surface)
outConfigs.add(outConfig)
var mStateCallback = object : CameraCaptureSession.StateCallback() {
override fun onConfigured(session: CameraCaptureSession) {
// 在回调中正常获取到session
cameraSession = session
}
...
}
var config = SessionConfiguration(SESSION_REGULAR,outConfigs,cameraExecutor,mStateCallback)
// 通过createCaptureSession尝试创建CameraCaptureSession
camera.createCaptureSession(config)
// 4,启动预览
// 创建一个捕获请求
var request = cameraDevice.createCaptureRequest(CameraDevice.TEMPLATE_PREVIEW).apply {
addTarget(dataBinding.surfaceViewId.holder.surface) // 添加预览view的surface,表明希望camera的数据输出到这个surface中
}.build()
// 设置捕获图像数据的请求
cameraSession.setRepeatingRequest(request,null,cameraHandler)
上述代码并不是完整代码,而是主要逻辑。开发者只要需要记住主要步骤即可:
- 通过SystemService获取CameraManager。
- 通过CameraManager获得CameraDevice。
- 通过CameraDevice获得CameraCaptureSession。
- CameraCaptureSession设置好surface开始获取摄像头数据。
具体的实现细节和对camera的参数的精细控制可自行实现。
音频的创建
对于Android设备而言,创建音频主要通过MediaRecorder,这是对音频录制的高度封装,而且可以实现音频视频的同时录制,而且实现编码并保存,正常而言如果对音视频没有更多要求,大家都应该使用这样高度封装的类,可以避免很多错误。而它的实现也非常简单,只要按照一定的顺序设置好配置即可。
// A common case of using MediaRecorder to record audio works as follows:
MediaRecorder recorder = new MediaRecorder();
recorder.setAudioSource(MediaRecorder.AudioSource.MIC);
recorder.setOutputFormat(MediaRecorder.OutputFormat.THREE_GPP);
recorder.setAudioEncoder(MediaRecorder.AudioEncoder.AMR_NB);
recorder.setOutputFile(PATH_NAME);
recorder.prepare();
recorder.start(); // Recording is now started
...
recorder.stop();
recorder.reset(); // You can reuse the object by going back to setAudioSource() step
recorder.release(); // Now the object cannot be reused
但是对于技术探讨必然不能追求省事,因此我们可以讲讲AudioRecod,这是Android系统中,用于管理音频资源的Java层实现类,通过它可以实现对音频的录制。
虽然AudioRecod自身的API结构同样简单,但是因为它剥离了音视频编码等内容,功能更加聚焦。对于AudioRecod,我们只需要创建对象,开始录制,读取数据,结束录制即可。
// MediaRecorder.AudioSource.MIC 音频来源 麦克风
// 剩余是 采样率,声道配置,采样深度,缓冲区大小,这些根据自身需要来进行配置
var audioRecoder = AudioRecord(MediaRecorder.AudioSource.MIC,SAMPLE_RATE,CHANNEL_CONFIG,
AudioFormat.ENCODING_PCM_16BIT,miniBufferSize)
// 开始录制
audioRecoder?.startRecording()
// 从AudioRecod读取音频数据到buffer
val readSize = audioRecord?.read(buffer, 0, buffer.size) ?: 0
// 停止录制
audioRecord?.stop()
我们可以看到声音的采集操作是不复杂的,不过我们也到知道声音的的各项配置是比较复杂的,需要注意。
关于Android编解码
前面获取到的音视频数据往往是原始数据,我们前面说过,原始数据直接保存的话太大了,所以往往需要经过编码,把数据缩小,才能正常保存。
Android系统针对编码和解码提供了一个统一的操作API,在Java层面我们无法对编解码细节做任何的窥探,但这并不意味着Java层面的编解码器只是高级API的摆设,实际上他们仍然属于较底层的API,因为通过它们可以接触到编码前后的数据,那么假如我们需要对音频或者视频做修改的话,这是一个很好的契机。而MediaRecoder的完全没有这样的可能性。
对于编解码器,核心类是MediaCodec。
声明周期
关于编解码器的生命周期如下:
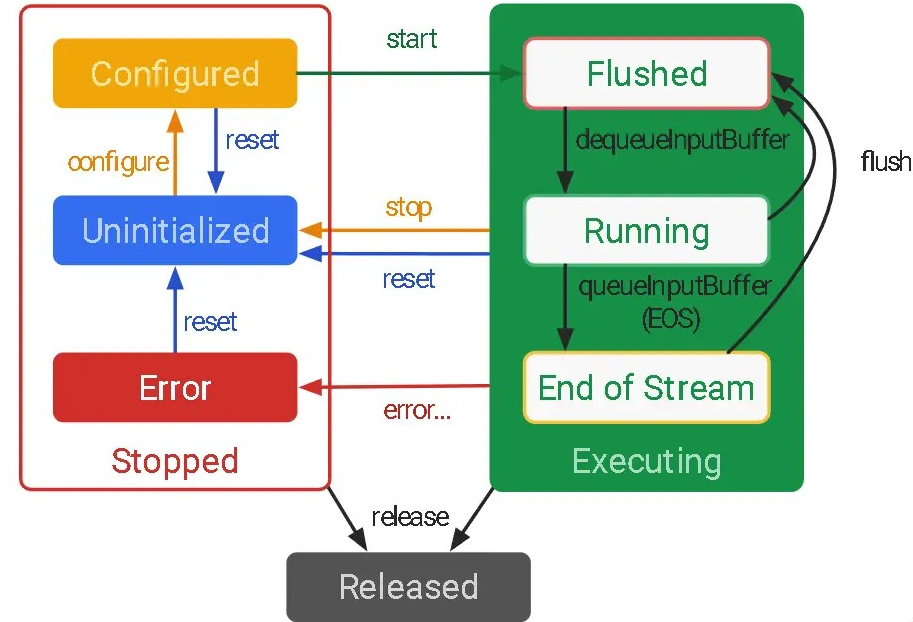
我们需要首先完成configure过程,然后开始进行编解码的工作,等编解码完成之后,再stop或者直接release.
工作流程
running状态的编解码的基本工作流程是这样的:
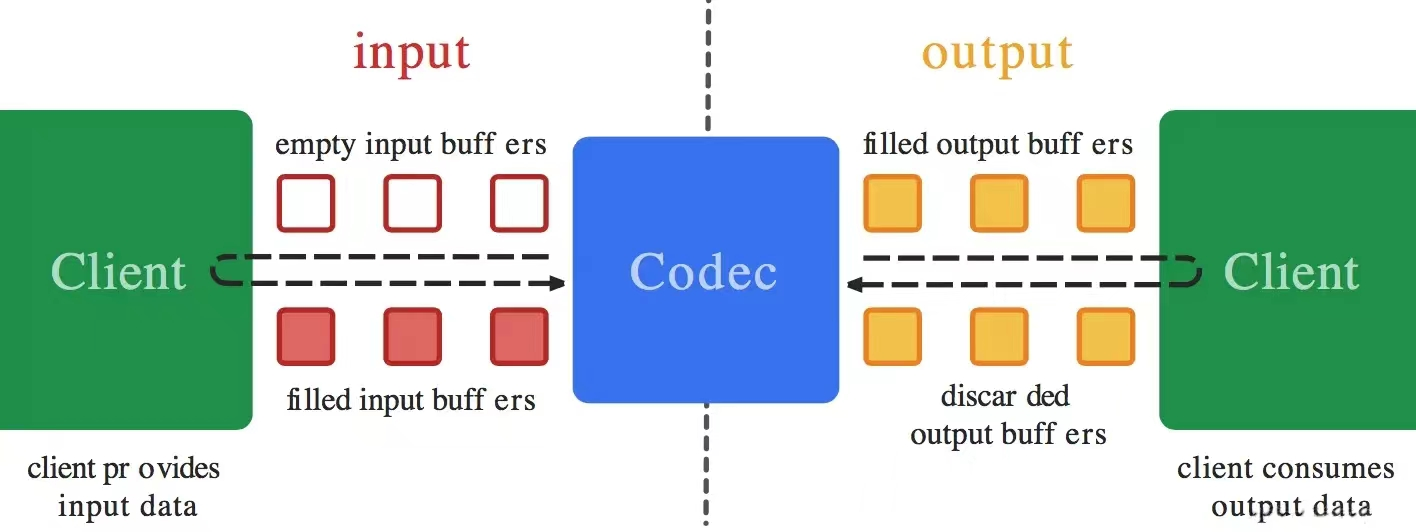
在输入端,不断的从编解码器中获取空的缓存空间,并填入待处理的数据。
在输出端,从对应的缓存空间中获取已经编解码完成的数据。
在连接输入和输出的编解码器则是一个黑盒子。
Android音视频编码
前面已经分别获取了音频和视频的数据,那么接下来就是对这些原始数据进行编码工作,注意对于视频和音频这两种完全不同的数据,是需要不同的编码器来实现编码过程的。
配置阶段
视频编码器的配置
// 获取视频的编码器
private val videoEncoder: MediaCodec by lazy {
MediaCodec.createEncoderByType(MediaFormat.MIMETYPE_VIDEO_AVC)
}
// 配置一些视频相关的参数。比如帧率,颜色格式等
val format = MediaFormat.createVideoFormat(MediaFormat.MIMETYPE_VIDEO_AVC,
videoWidth,videoHeight
)
format.setInteger(MediaFormat.KEY_COLOR_FORMAT,
MediaCodecInfo.CodecCapabilities.COLOR_FormatSurface
)
format.setInteger(MediaFormat.KEY_BIT_RATE, video_bit_rate) // bit rate
format.setInteger(MediaFormat.KEY_FRAME_RATE, video_fps) // 帧率
...
videoEncoder.configure(format, null, null, MediaCodec.CONFIGURE_FLAG_ENCODE)
// 开始进行编码
videoEncoder.start()
音频编码器的配置(大差不差)
//获取音频的编码器
private val audioEncoder: MediaCodec by lazy {
MediaCodec.createEncoderByType(MediaFormat.MIMETYPE_AUDIO_AAC)
}
format = MediaFormat.createAudioFormat(
MediaFormat.MIMETYPE_AUDIO_AAC,
SAMPLE_RATE,
1
)
format.setInteger(MediaFormat.KEY_BIT_RATE, AUDIO_BIT_RATE)
format.setInteger(MediaFormat.KEY_AAC_PROFILE, MediaCodecInfo.CodecProfileLevel.AACObjectLC)
...
audioEncoder.configure(format, null, null, MediaCodec.CONFIGURE_FLAG_ENCODE)
// 开始进行编码
audioEncoder.start()
调用了configure方法之后,编码器就进入了configured的状态,然后调用start之后,就进入了编码状态,此时就需要往编码器里输入待编码的数据了。
编码
而目前,编解码的方式有两种,一种是同步模式,一种是异步模式,我们先展示下同步模式下,编码工作是怎样进行的:
// 注意,编码工作应该在子线程中进行
...
while (true){
/************ 编码的输入部分 *************/
// 尝试从缓存队列中获取一个可用空间的下标
val index = audioEncoder.dequeueInputBuffer(0)
if (index >= 0){
// 获取到缓存空间
val inputBuffer = audioEncoder.getInputBuffer(index)
var buffer = ByteArray(BUFFER_SIZE)
// 从音频录制器中读取录制的音频数据,不一定能读满 BUFFER_SIZE
val readSize = audioRecord?.read(buffer, 0, buffer.size) ?: 0
var inputBuffer :ByteBuffer? = null
if (readSize > 0) {
inputBuffer?.let {
it.clear()
it.put(buffer)
it.position(0)
it.limit(readSize)
// 当前时间戳
val time = getPresentationTimeUs()
audioEncoder.queueInputBuffer(index, 0, readSize,time , 0) // 把数据输入队列中
}
}
}
/************ 编码的输出部分 *************/
var encoderStatus = mediaCodec.dequeueOutputBuffer(bufferInfo,0)
if(encoderStatus == MediaCodec.INFO_TRY_AGAIN_LATER){
break;
}else if(encoderStatus == MediaCodec.INFO_OUTPUT_FORMAT_CHANGED){
outputFormat = mediaCodec.getOutputFormat()
Log.i(Constant.LOG_TAG,"获取输出的媒体格式 ===============")
}else if (encoderStatus<0){
Log.w(Constant.LOG_TAG,"dequeueInputBuffer error $encoderStatus")
}else{ // 大于等于0,表示成功
// 此时encoderStatus 就是输出缓冲队列的缓存区下标 index
var encodedData : ByteBuffer?= mediaCodec.getOutputBuffer(encoderStatus)?:return encodedFrame
Log.i(Constant.LOG_TAG,"获取编码的数据 ===============")
if(bufferInfo.flags and MediaCodec.BUFFER_FLAG_CODEC_CONFIG != 0){
bufferInfo.size = 0
}
if (bufferInfo.size!=0){
encodedData?.position(bufferInfo.offset)
encodedData?.limit(bufferInfo.size+bufferInfo.offset)
// 接下来把数据encodedData写入文件即可
}
// 缓存空间被使用完之后释放空间,把内存空间返回给编解码器
mediaCodec.releaseOutputBuffer(encoderStatus,false)
if ((bufferInfo.flags and MediaCodec.BUFFER_FLAG_END_OF_STREAM)!=0){
break
}
}
}
以上就是基于同步模式下,处理音频数据编码的大体过程,需要注意的有以下几点:
- 编解码都应该在子线程中进行,也要考虑线程通信的问题。
- 对于输出缓存区使用完之后需要手动释放掉。
- 很多API调用都可能出现throw Exception,需要进行catch
个人认为相对于同步模式而言,异步模式在大多数情况下可能更加有利于开发,因此后面的需要演示的代码都使用异步模式来展示。
异常模式的启用方式,就是在encoder进行configure之后,且start之前,设置setCallback回调即可。
private val audioHandlerThread = HandlerThread("async-audio-encode").apply { start() }
private val asyncAudioEncodeHandler: Handler = Handler(audioHandlerThread.looper)
...
audioEncoder.configure(...)
audioEncoder.setCallback(object : MediaCodec.Callback() {
private var audioTrack = -1
// 这是输入端
override fun onInputBufferAvailable(codec: MediaCodec, index: Int) {
if (!recoding){
return
}
var buffer = ByteArray(BUFFER_SIZE)
// 读取音频原始数据
val readSize = audioRecord?.read(buffer, 0, buffer.size) ?: 0
var inputBuffer :ByteBuffer? = null
inputBuffer = codec.getInputBuffer(index)
if (readSize > 0) {
inputBuffer?.let {
it.clear()
it.put(buffer)
it.position(0)
it.limit(readSize)
// 记录当前的时间戳
val time = getPresentationTimeUs()
codec.queueInputBuffer(index, 0, readSize,time , 0)
}
}
}
// 这是输出端
override fun onOutputBufferAvailable(
codec: MediaCodec,
index: Int,
info: MediaCodec.BufferInfo
) {
if(isEnd) return
val outputBuffer = codec.getOutputBuffer(index)
val outputFormat = codec.getOutputFormat(index)
if ((info.flags and MediaCodec.BUFFER_FLAG_CODEC_CONFIG) != 0) {
info.size = 0
}
outputBuffer?.let {
it.position(info.offset) // offset一般就是0
it.limit(info.offset + info.size)
...
// 把编码后的数据输出到文件
}
codec.releaseOutputBuffer(index, false)
var isEnd = (info.flags and MediaCodec.BUFFER_FLAG_END_OF_STREAM) != 0
}
override fun onError(codec: MediaCodec, e: MediaCodec.CodecException) {
...
}
override fun onOutputFormatChanged(codec: MediaCodec, format: MediaFormat) {
//输出格式变化
}
// 保证异步回调在这个线程中进行
}, asyncAudioEncodeHandler)
// 开始进行编码
audioEncoder.start()
以上就是音频编码的异步模式的使用方式。
对于视频而言,如果读取视频的原始数据的话,操作方式是基本一致的,但是编解码器也提供了Surface作为输入或者输出的接口,比如在编码时,编码器可以提供一个Surface用作输入的入口,而不需要我们手动把数据读入到编码器,这就大大的降低了我们的工作量。正好,camera也可以接受surface作为摄像头数据的输入地,因此,我们其实只需要把encoder提供的Surface添加到操作camera时需要填入的surface列表中即可。
...
// 注意,后面setRequest时输入的surface必须在此处的configuration里的surface范围内
var outConfig = OutputConfiguration(
dataBinding.surfaceViewId.holder.surface,
encoder.createInputSurface()) // createInputSurface()就是编码器提供的输入接口
...
其实如果我们想要使用原始数据也是可行的,利用ImageReader对象设置一个数据回调,ImageReader.surface同样添加到camera的输出列表中即可(没错,同样也是依赖surface)。
一般我们就直接通过encoder的surface来承接camera的数据,可以节省很多工作,而且使用了inputSurface之后,异步模式的输入回调就不会调用了。
private val handlerThread = HandlerThread("async-video-encode").apply { start() }
private val asyncEncodeHandler: Handler = Handler(handlerThread.looper)
...
videoEncoder.setCallback(object : MediaCodec.Callback() {
var outputFormat: MediaFormat? = null
var mVideoTrack: Int = -1
var isEnd = false
override fun onInputBufferAvailable(codec: MediaCodec, index: Int) {
// 使用了surface,我们不会受到回调
}
override fun onOutputBufferAvailable(
codec: MediaCodec,
index: Int,
bufferInfo: MediaCodec.BufferInfo
) {
if (isEnd) {
return
}
val outputFormat = encoder.getOutputFormat(index)
var encodedData: ByteBuffer? = encoder.getOutputBuffer(index) ?: return
if (bufferInfo.flags and MediaCodec.BUFFER_FLAG_CODEC_CONFIG != 0) {
bufferInfo.size = 0
}
if (bufferInfo.size != 0) {
encodedData?.position(bufferInfo.offset)
encodedData?.limit(bufferInfo.size + bufferInfo.offset)
encodedData?.let {
...
// 输出的编码数据可以写入文件
}
}
// 缓存空间被使用完之后释放空间,把内存空间返回给编解码器
encoder.releaseOutputBuffer(index, false)
isEnd = (bufferInfo.flags and MediaCodec.BUFFER_FLAG_END_OF_STREAM) != 0
}
override fun onError(codec: MediaCodec, e: MediaCodec.CodecException) {
Log.i(LOG_TAG, "onError : ${e.errorCode} ${e.message}")
}
override fun onOutputFormatChanged(codec: MediaCodec, format: MediaFormat) {
Log.i(LOG_TAG, "onOutputFormatChanged : ${format.toString()}")
}
}, asyncEncodeHandler)
可以看到,代码大大减少。
这只是音视频的编码的基本逻辑,有大量需要关注的问题并没有体现出来:
- MediaCodec的API会抛出大量的异常,需要catch
- 编码器的启动和关闭的控制时机
- 可能的多线程问题
- 编解码输入过程中的PTS设置
- 如何写入文件
以上几个问题,前面三个其实还好,如果仔细看文档和需要很容易掌握。而PTS设置可能对大家会存在一些困扰,所以有必要专门用一个小节来解释一下,写入文件则是另一个问题,在下一个节中进行讲述。
编解码的PTS
PTS是presentation timestamp(显示时间戳)的意思,一般使用presentationTimeUs变量来表示。
大概就是告诉编解码器当前数据应该在哪个时间点来显示。需要在queueInputBuffer时设置,而且无论是音频或者视频都需要pts这个数据(单位微秒),但是如何得到这个数据呢?
官方文档对于这个PTS的解释并不多,但是根据我的观察,这时间戳的对于时间的起点并没有限制,重要的是能正确表示在时间轴中每一帧数据应该处在哪个时间点。
我看网络上许多的demo大家使用的是
System.nanoTime()/1000L
也就是每次queueInputBuffer之前,都通过上面的代码获取一次当前时间戳。这种方式似乎没有太大的问题,而且播放显示基本正常。
但是官方的测试代码却不是这么写的,而是根据音频或者视频的格式配置来计算出当前时间戳,比如我摘抄的这段对音频数据的PTS的计算:
// numBytesSubmitted 就是累计提交给编码器的数据量,1000000是单位转换,把秒转换为微秒
// 而根据音频的采样率,采样精度,声道数我们可以计算出一秒钟内的音频数据量
// channelCount就是声道数,sampleRate是采样率,
//而2代表的应该就是16/8的意思,16是一般音频采样精度,8则是把bit转换为byte
long timeUs = (long)numBytesSubmitted * 1000000 / (2 * channelCount * sampleRate);
上面的公式就是根据已经提交的音频数据量除以一秒钟来获得当前提交的数据所处的时间戳。我们举个例子,假设音频数据每一秒的数据量是1024kb,而numBytesSubmitted此时是1536kb,那么就表示当前提交的数据所处的时间戳是1.5*1000_000L微秒这个时间点(默认时间起点是0)
我个人认为官方的计算方法应该是最合理的,但是根据我的实际测试,假如使用官方的计算方式来设置PTS,得到的视频文件缺失可以正常播放,但是显示的视频时长信息却不正常(无法预览到视频时长,播放时无进度条显示)。
我猜测可能是时间起点为0导致的,因此在这个基础上把时间起点改为某一个系统时间,
if (startPresentationTimeUs == -1L) { // 初始化
startPresentationTimeUs = System.nanoTime()/1000L
}
var timeUs = numBytesSubmitted * 1000000L / (2 * channelCount * sampleRate)+startPresentationTimeUs
通过这样修改后,显示和播放都变得正常了。对于视频其实也是类似的方法,我们一般会提前知道想要录制的视频的帧率,通过记录帧数就可以得到每一帧应该在哪个时间点显示…
封装复用
我们知道音频和视频是单独的数据,必然不能直接通过文件流写入到文件,必然需要按照所封装的格式进行写入(如果是mp4就需要按照mp4的格式要求写入)。这就是我们要讲的媒体文件的封装复用(muxer)。
封装复用的核心类是MediaMuxer,其实它的API并不复杂:
// 根据媒体文件路径,格式来创建对象
var mediaMuxer = MediaMuxer(filePath, MediaMuxer.OutputFormat.MUXER_OUTPUT_MPEG_4)
var outputFormat = codec.outputFormat
// 根据编码器输出的编码数据所属的格式(视频或音频),来添加一个轨道
// 这个轨道后面就专门存储这个格式的媒体数据
audioTrack = mediaMuxer.addTrack(outputFormat)
//start之后就可以了开始写入了(但是start只能调用一次)
mediaMuxer.start()
// 写入数据
mediaMuxer.writeSampleData(audioTrack,encodedData,bufferInfo)
// 释放资源
mediaMuxer.stop()
mediaMuxer.release()
以上基本就是我们使用MediaMuxer所用到的所有API了,但是问题并没有那么简单,因为mediaMuxer.start只能调用一次,但是音视频编码时在不同的编码器不同的线程中进行的,所以我们就需要一些线程同步操作,保证在音频和视频的轨道都被添加上了之后再调用start,开始写入数据。
只要选好时机,线程同步就不会太复杂,编码器在正式输出编码数据之后,会提前回调一次输出数据的格式onOutputFormatChanged,因此我们在这个回调中添加轨道即可,然后等待两个编码器都完成了这个回调以后再start即可。
一个思考题,MediaMuxer的writeSampleData是否需要进行线程同步?
总结
目前分析了Android音视频创建,编码,存储,可以说我们粗略的讲完了音视频的上半程;还剩下读取,解码,播放,由于篇幅所限决定分为两篇叙述较好。
如何学习
当前市面上系统性、全面性的音视频教程与专业书籍相对稀缺,使得新手往往需要通过点滴积累和自我摸索的方式逐步建立起相关的知识体系,这一过程不仅难度加大,耗费的时间成本也相当可观。
为了帮助广大音视频爱好者和从业者高效入门并深入探究音视频开发技术,特此整理了一份详实的音视频开发学习指南,旨在引导大家构建起扎实且完整的知识架构,助力每一位有志之士成功转型为专业的音视频开发工程师。
【有需要的朋友,可以扫描下方二维码免费领取!!】

首先给大家分享一份高级音视频学习思维导图,希望这份思维导图能够给大家学习音视频开发提供一个好的方向

并且根据上述这份思维导图融合了这些年的工作经历及对网上的资料查询和整理, 最终将其整合了一份高级音视频开发学习笔记
第1章 Android音视频硬解码篇
- 1.1 音视频基础知识
- 1.2 音视频硬解码流程:封装基础解码框
- 1.3 音视频播放:音视频同步
- 1.4 音视频解封和封装:生产一个MP4

第2章 使用OpenGL渲染视频画面篇
- 2.1 初步了解OpenGL ES
- 2.2 使用OpenGL渲染视频画面
- 2.3 OpenGL渲染多视频,实现画中画
- 2.4 深入了解OpenGL之EGL
- 2.5.2 FBO简介
- 2.6 Android音视频硬编码:生成一个MP4

第3章 Android FFmpeg音视频解码篇
- 3.1 FFmpeg so库编译
- 3.2 Android 引入FFmpeg
- 3.3 Android FFmpeg视频解码播放
- 3.4Android FFmpeg+OpenSL ES音频解码播放
- 3.5 Android FFmpeg+OpenGL ES播放视频
- 3.6 FFmpeg简单合成MP4:视屏解封与重新封装
- 3.7 Android FFmpeg 视频编码

第4章 直播系统聊天技术
- 4.1 百万在线的美拍直播弹幕系统的实时推送技术实践之路
- 4.2 阿里电商IM消息平台,在群聊、直播场景下的技术实践
- 4.3 微信直播聊天室单房间1500万在线的消息架构演进之路
- 4.4 百度直播的海量用户实时消息系统架构演进实践
- 4.5 微信小游戏直播在Android端的跨进程渲染推流实践

第5章 阿里IM技术分享
- 5.1 企业级IM王者——钉钉在后端架构上的过人之处
- 5.2 闲鱼IM基于Flutter的移动端跨端改造实践
- 5.3 闲鱼亿级IM消息系统的架构演进之路
- 5.4 闲鱼亿级IM消息系统的可靠投递优化实践

有需要的朋友,可以扫描下方二维码免费领取!!














 2704
2704











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









