






前言
验证曲线是调节学习器的参数的,学习曲线是用来调节训练样本大小的。
从理论上来讲,如果数据“同质”,当数据量到达一定程度时,学习器可以学到所有的“特征”,继续增加样本没有作用。
那么到底多少样本是合适的呢?
做个实验
逐渐增大训练样本量,同时判断训练集和测试集的准确率,看看会发生什么
1. 首先从训练集中拿出1个数据,训练模型,然后在该训练集(1个)和测试集上检验,发现在训练集上误差为0,在测试集上误差很大
2. 然后从训练集中拿出10个数据,训练模型,然后在该训练集(10个)和测试集上检验,发现在训练集上误差增大,在测试集上误差减小
3. 依次…
4. 直到拿出整个训练集,发现模型在训练集上误差越来越大,在测试集上误差越来越小
如图
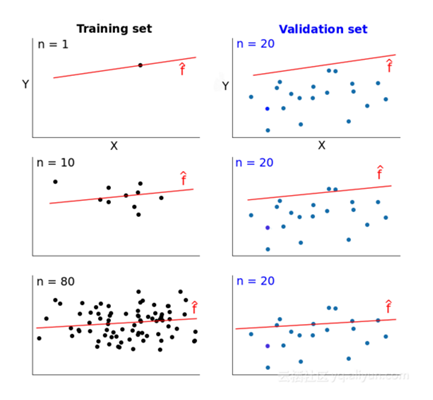
把训练集大小作为x,误差作为y
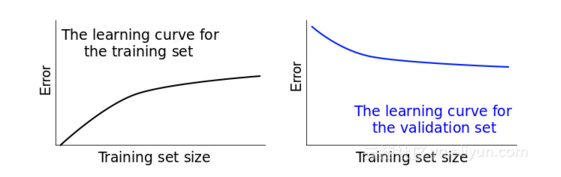
训练集误差逐渐增大,测试集误差逐渐减小。
那必然相交或者有个最小距离,此时继续增加样本已然无用,此时模型已无法从样本上学到任何新的东西。
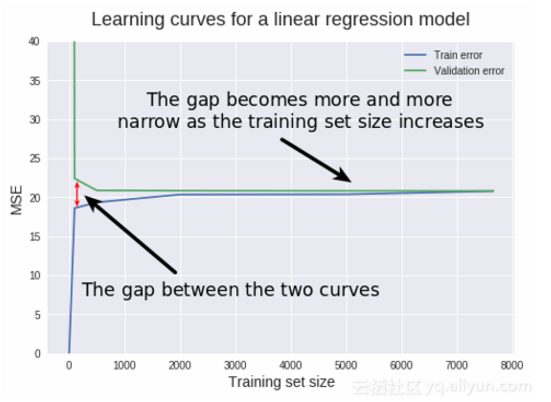
示例代码
import numpy as np
import matplotlib.pyplot as plt
from sklearn.naive\_bayes import GaussianNB
from sklearn.svm import SVC
from sklearn.datasets import load\_digits
from sklearn.model\_selection import learning\_curve
from sklearn.model\_selection import ShuffleSplit
def plot\_learning\_curve(estimator, title, X, y, ylim=None, cv=None, train\_sizes=np.linspace(.1, 1.0, 5)):
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(\*ylim)
plt.xlabel("Training examples")
plt.ylabel("Score")
train\_sizes, train\_scores, test\_scores \= learning\_curve(
estimator, X, y, cv\=cv, train\_sizes=train\_sizes)
train\_scores\_mean \= np.mean(train\_scores, axis=1)
train\_scores\_std \= np.std(train\_scores, axis=1)
test\_scores\_mean \= np.mean(test\_scores, axis=1)
test\_scores\_std \= np.std(test\_scores, axis=1)
plt.grid()
plt.fill\_between(train\_sizes, train\_scores\_mean \- train\_scores\_std,
train\_scores\_mean \+ train\_scores\_std, alpha=0.1,
color\="r")
plt.fill\_between(train\_sizes, test\_scores\_mean \- test\_scores\_std,
test\_scores\_mean \+ test\_scores\_std, alpha=0.1, color="g")
plt.plot(train\_sizes, train\_scores\_mean, 'o-', color="r",
label\="Training score")
plt.plot(train\_sizes, test\_scores\_mean, 'o-', color="g",
label\="Cross-validation score")
plt.legend(loc\="best")
return plt
digits \= load\_digits()
X, y \= digits.data, digits.target
title \= "Learning Curves (Naive Bayes)"
cv \= ShuffleSplit(n\_splits=100, test\_size=0.2, random\_state=0)
estimator \= GaussianNB()
plot\_learning\_curve(estimator, title, X, y, ylim\=(0.7, 1.01), cv=cv)
title \= "Learning Curves (SVM, RBF kernel, $\\gamma=0.001$)"
cv \= ShuffleSplit(n\_splits=10, test\_size=0.2, random\_state=0)
estimator \= SVC(gamma=0.001)
plot\_learning\_curve(estimator, title, X, y, (0.7, 1.01), cv=cv)
plt.show()
输出
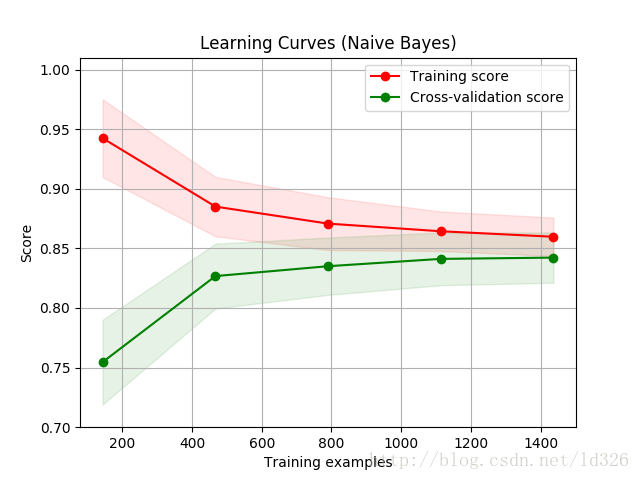
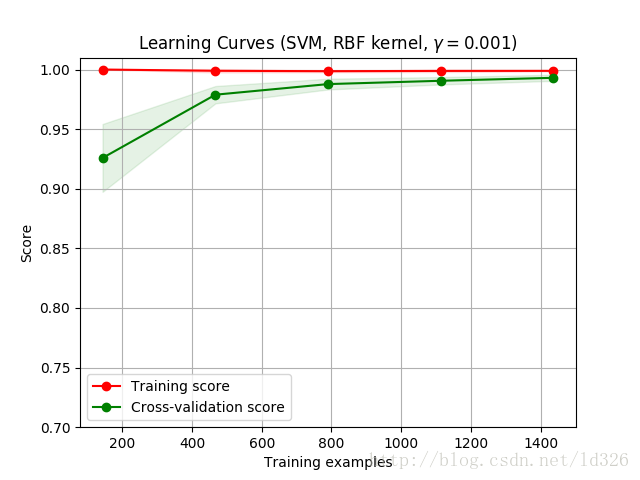
事实上,数据“同质”的可能性很小,所以数据量越大越好。
最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

五、面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









