






前言
转眼9月了,秋招不知道条有没有过半,只是大致投了几家感兴趣的。(当舔狗是没有好下场的!)。
浅浅罗列了些最近秋招被问到的好问题(个人感觉),受限于知识面浅薄,有些问题当时直接干晕了(红温了属于是),但问题是不错的,所以抛砖引玉,看看有没有大佬给出更好的回答呢,如果能帮上大家就更好啦。
Triton (openai 版)
今年确实挺火的,肉眼可见zhihu上多了很多相关的优秀博客,互联网大厂想用它写算子,比cuda迭代周期更短;硬件厂想用它的DSL来推广自己的软件栈和生态。
1. 你是怎么做triton kernel优化的
不管啥 kernel,到我手上都是经过“两步走”来优化:
浅层优化:通过替换算子、(用atomic op)合并kernel、拆循环、调config等方式实现初步优化。
深层优化:分析下降所得IR,使用perf工具,对照算子库实现等方式,优化kernel的下降行为。

大部分情况下,“第一步”走完性能就接近算子库了,还是大哥们后续codegen的pass太顶级了,我成为了无情的config添加器。
关于这部分更详细的可以看看鄙人的记录,这里详细一些rtfff:[Triton] Kernel Optim
当“第一步”走完性能还是和算子库有距离,那就继续“第二步”,上perf!看ir!看看访存是否连续,得到的汇编是否符合预期等。(自己总有看不懂的时候,直接叫大哥)
分解出优化点,在ir下降过程加点美味的pattern,大部分情况还是得看看算子库的大哥们是咋写的kernel,然后(抄一下)启发一下编译器的 lowering过程。如果还是打不过怎么办,这时候就真得看看IO这些是否打得比较足了,或者换过服务器多跑几次(别试,一般没用)。
2.triton的下降流程,讲讲你对triton中layout的理解:
官方:triton-lang -> triton ir -> triton gpu dialect ->llvmir -> ptx
其中 llvm ir 更标准地说法应该是 nvvm ir,相比官方的 llvm ir要额外扩展了一些 hardware intrinsic 和 conversion。想了解可以看llvm project中的 llvm/include/llvm/IR/IntrinsicsNVVM.td 和 llvm/lib/Target/NVPTX/。
ptx后序会根据硬件信息转为sass。
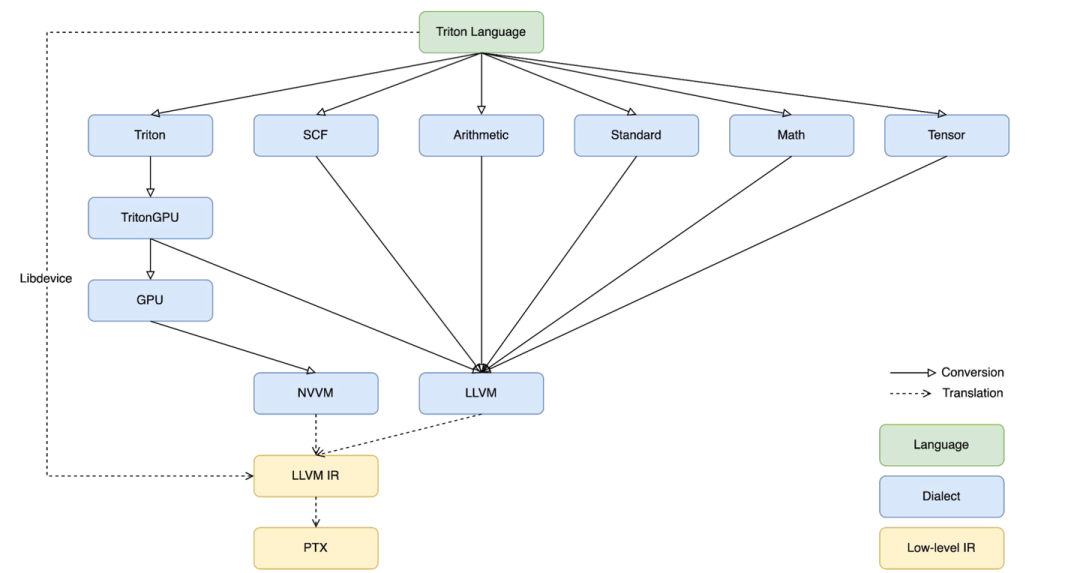
triton 中的 layout 在 triton gpu dialect 才第一次出现,作为attr辅助op的conversion和transform,主要分为两种:distributed layout 和 shared layout。
-
distributed layout:描述tensor应该如何被thread访问,又分为 block layout、mma layout 和 dotoperand layout
-
block layout:使用 AxisInfoAnalysis 获得 load 和 store 等指针操作 op 具体的操作 tensor(shape、layout信息等)以及连续性信息,这个信息后序会用来在 memory-coalesce (访存合并)。
mma layout 和 dotoperand layout:我理解都是描述了特定 op 的 operand 的数据布局,以指导后序 op 的 lowering。
- shared layout:shared layout 描述了 share mem 中可能被同时访问的处于同一个bank的数据。share mem中的每个bank会会单独相应内存访问请求,所以同一时间内,若多个 thread 访问的数据处于同一个 bank 就会产出 bank conflict ,导致吞吐异常。所以根据 shared layout 进行 layout-swizzling,调整相关的数据布局。
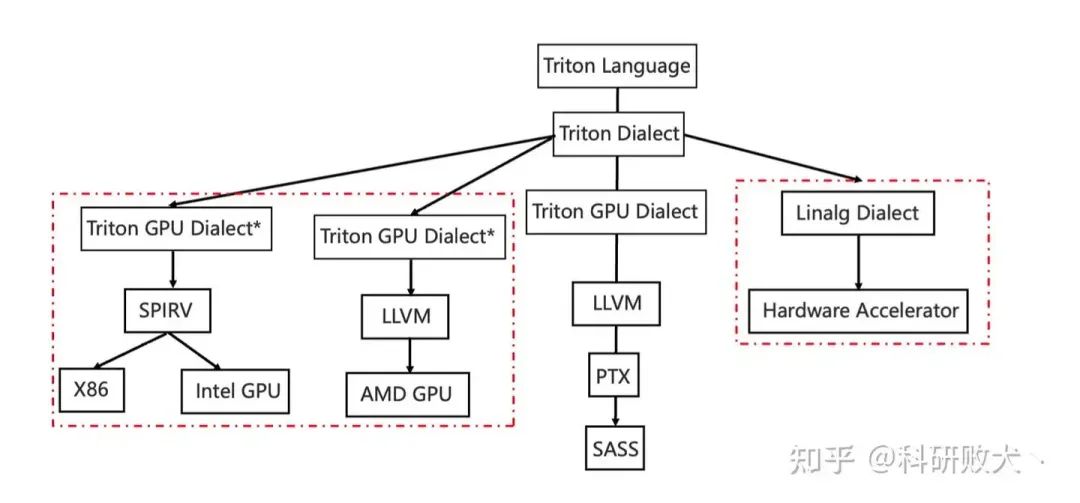
关注开源社区的朋友们可能了解到前段时间寒武纪开源了 triton-linalg 这为其他 DSA(ASIC) 接入 triton 提供了一条不错的道路。
我了解到这条路:triton-lang -> triton ir -> linalg dialect -> hardware dialect -> llvm ir -> … ->hardware assembly
和硬件无关的dialect比官方的更多,优化可以在 ttir、linalg-on-tensor,linalg-on-memref,hardware dialect 做,arch 和 non-arch 的抽象隔离地比较好。但路铺得长工程量也就大。
3.支持triton的好处,和官网的triton有何不同
支持triton,一是可以用户也方便自己定义kernel,迁移成本低。二是开发人员也可以写算子库或者特定的加速库,现在很多框架中都带上了triton的kernel实现。
和官方的不同在于,(个人理解)从ttir开始分叉开,用不上官方的ttgir往后的优化pass,本质上更贴近SPMD的编程范式,某些原语有自己的映射。在优化ir上,某些也是根据硬件特性来的。
MLIR
1. mlir codegen 这条路更适合处理哪类任务 ?
当时比较蒙,后面面试官大哥说“更适合访存密集型任务”,后来想来,或许是codegen这条路更好调整数据的memory层次,比较好优化不同memory-space之间的data flow?(不知道有没有其他大哥解答下)
2. 对 SIMD 硬件的优化 和 SIMT 硬件的优化(or codegen) 有什么异同
当时只想到了SIMD希望访存更加连续,SIMT希望吞吐更大。今天回顾了一下 棍哥的 文章,
有了琦琦的棍子:漫谈高性能计算与性能优化:访存
突然感觉能串起来一些了。
SIMD
核心优化 latency,越快完成越好 -> 保证访存连续性,用连续指令(非strided,非scalar)
其他常见优化:
-
tile(+fuse) 到不同 core 上并行执行,core之间利用smem交换数据 -> 减少 data move
-
在core内循环展开(最内维)做软流水;core之间async -> 减少访存 latency
SIMT
核心优化 throughtput ,吞吐越大越好 -> 用好 DMA 和 TMA,打满 tensorcore其他常见优化:
-
离散访存优化 smem 中 memory-coalesce、layout-swizzling -> 减少访存 latency
-
异步调度 warp,通过warp切换来掩盖访存延迟(其实相当于软流水) -> 减少访存 latency
3. 算子融合先tile再fuse还是先fuse再tile
做算子融合的时候,从写算子的角度上,惯性是想先确定能够fuse到一起的op,再把这个序列一起tile。fuse起来的形式一般是固定的pattern或者像xla那类,或者是贪心的。这样tile时就能获得一个片上一定能放得下且性能不错的 tile_size。
我熟悉的一条路是先tile再fuse,找到一个锚点op,确定好tile策略后再将producer和consumer给贪心的fuse进去,后续hardware dialect再做 mlu+add -> fma 这样的融合行为。今天听大哥讲,可以从 tvm ansor 的那种行为去理解,应用模版后就只需要去寻找其中的 tile_size 就好了,贪心fuse不进去就算了,但后续这条路应该还是会优化的,毕竟我想基于这相关的做做毕设(在大哥的花上雕shit)。
由于文章篇幅有限,没法将全部的面试题展示出来,有需要完整面试题+答案解析的朋友,可以扫描下方二维码领取!!!
























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









